
[이번 포스팅은, "FCN: Fully Convolutional Networks for Semantic Segemantation" 논문과 아래 블로그들을 참조하여 작성하였습니다]
[논문 리뷰] FCN: Fully Convolutional Networks for Semantic Segmentation
Convolutional Network의 구조를 end-to-end, pixells-to-pixels 방식으로 학습시켜 semantic segmentation 분야에서 SOTA 달성임의의 사이즈의 이미지를 인풋으로 넣었을 때, 동일한 사이즈의 아웃풋이 나오도록 full
velog.io
1) FCN
FCN은 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 Semantic Segmentation Task를 수행할 수 …
wikidocs.net
이번에 알아볼 논문은 Image Segmentation 분야에서 중요한 역할을 하게 된 FCN의 등장을 알린 "FCN: Fully Convolutional Networks for Semantic Segemantation" 입니다.
해당 논문은 Jonathan Long, Evan Shelharmer, Trevor Darrell에 의해 저술되었으며 포스팅을 작성하는 현재(23년 10월 26일) 기준, 약 4만 4천회가 인용된 유명한 논문입니다.
논문이 발표되었던 2015년 당시에는 다양하고 성능좋은 Image Classification 모델들이 등장하면서 획기적인 발전을 이루었지만, Image Segmentation에 있어서는 한계점들이 존재하던 시기였는데요. 본 논문이 제시한 모델을 활용함으로써 Image Segmentation에 있어서 큰 발전이 이루어지게 되었습니다.
특히, 픽셀 단위의 예측을 위한 최초의 end-to-end 방식이자 지도 사전학습을 활용했다는 점과 skip 구조를 활용해 이미지의 전반적인 정보와 세부 정보를 혼합시켰다는 점에서 Image Segementation 분야에서 큰 기여를 한 논문이라고 할 수 있습니다.
1. Fully Convolutional Network
1) 개요
- Convolutional Network의 구조를 활용해 end-to-end, pixels-to-pixels 방식으로 학습시켜 semantic segmentation 분야에서 SOTA를 달성했습니다.
* SOTA : State-Of-The-Art 의 약자로, 현재 최고 수준의 결과를 의미합니다.
- 기존 Classification 모델인 AlexNet, VGGNet 등을 fine tuning하여, 전반적인 정보(본문에서는 Coarse로 표현)에서 세밀한 정보(Fine)를 혼합시켜 더 정확한 픽셀 분류가 가능해졌습니다.
2) 네트워크의 구조
a) Adapting Classifier for dense prediction
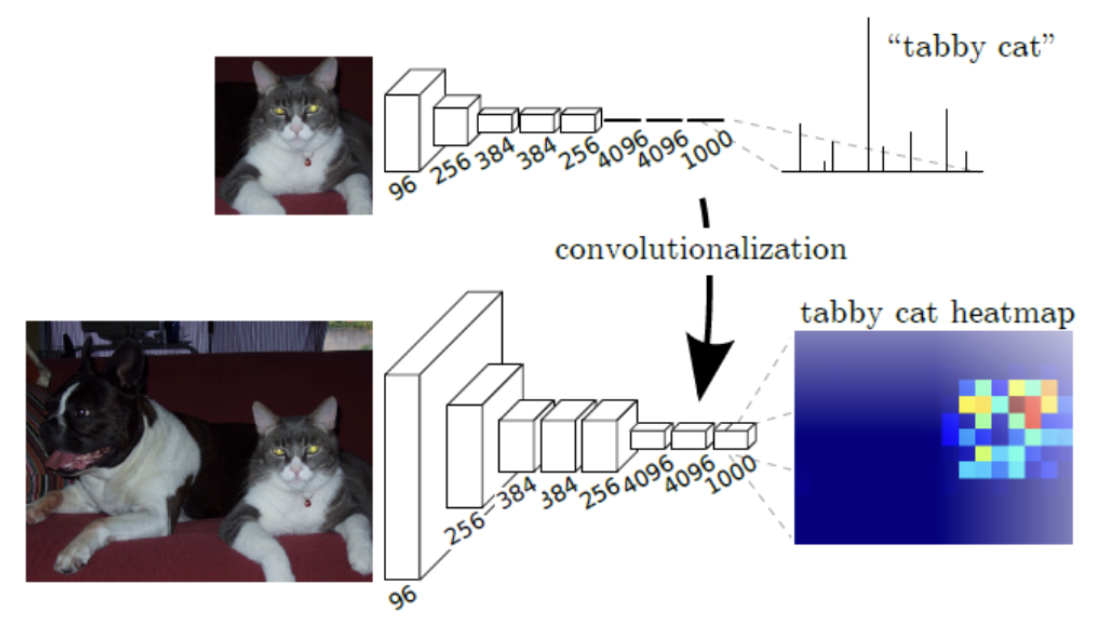
* 기존의 분류기(Classifier)들은 마지막에 전 연결층(Fully Connected Layer)에 연결되어 고정된 크기의 입력을 받으므로, 이미지가 가지고 있던 공간적 정보를 가지지 않은 출력을 생성하게 됩니다.
* 이미지 전체를 분류하는 Classification의 경우 이미지에 내재한 공간 정보가 소실되더라도 큰 문제가 되지 않을 수 있지만, Segementation의 경우 공간 정보를 유지하여 픽셀 단위로 예측해야 하므로 문제가 됩니다.
* 이 문제를 해결하기 위해, 기존 분류기에서 Fully Connected Later는 버리고 1x1 Conv 및 Upsampling(Transpose Convolution)이 포함된 층으로 변경하여, 픽셀 단위의 클래스 분류가 가능해지고 입력 이미지와 같은 사이즈 회복을 하도록 네트워크가 구성됩니다.
(위 그림에서 처럼, 기존 네트워크의 전연결층을 활용하면 전체 이미지가 특정 클래스에 속할 확률만이 도출되지만, 전연결층이 아닌 1x1 Conv 및 Transpose Conv 를 활용하면 각 픽셀 단위의 예측값이 수치로 도출된다는 의미입니다)
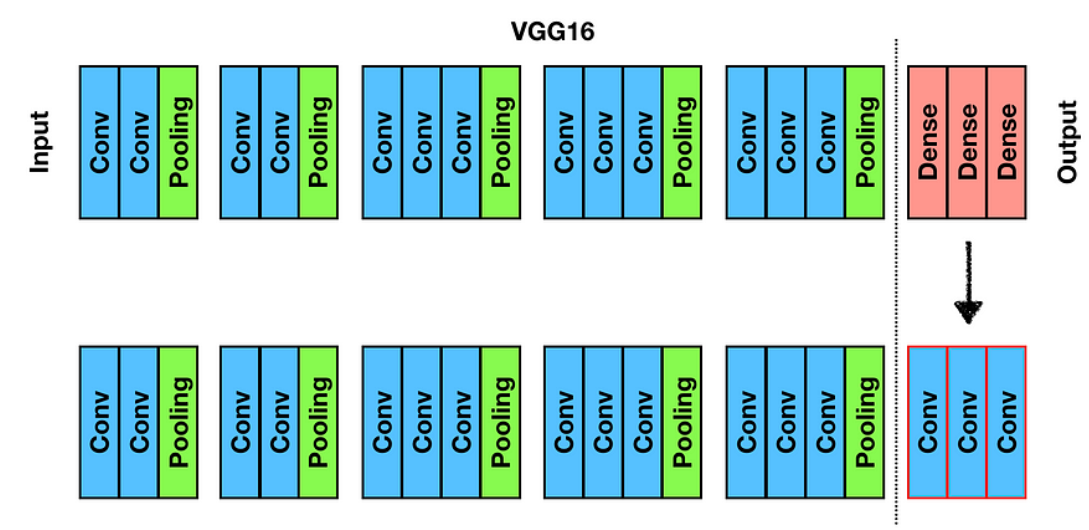
(아래 그림은 VGG16의 마지막 Dense Layer, 즉 Fully Connected Layer가 있는 것을 알 수 있지만, 이를 해당 논문의 아이디어처럼 1x1 Conv / Trasnpose Conv를 활용한 층으로 바꾼 모습입니다)
b) 전체 네트워크의 구조
- 앞서 설명한 기본 아이디어를 바탕으로 논문에서 제시한 FCN의 구조에 대해서 알아보겠습니다.
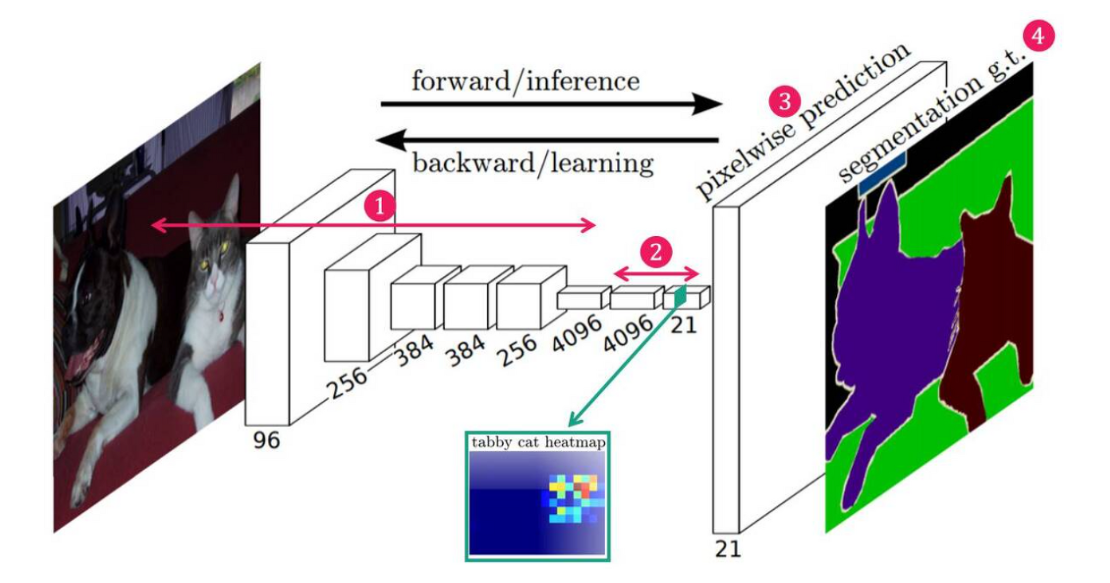
1) Convolution Layer를 통해 Feature를 추출
2) 1x1 Convolution Layer를 이용해 Feature map의 채널수를 데이터셋 객체의 개수와 동일하게 변경
(Class Presence Heat Map 추출)
3) Up Sampling : 낮은해상도의 Heat Map을 Upsampling(=Transposed Convolution)하여 입력 이미지와 같은 크기의 Map을 생성
4) 네트워크에서 생성된 픽셀 단위의 클래스 예측맵(Pixelwise prediction)과 레이블되어 있는 픽셀단위 클래스 맵(Segementation Ground Truth)을 픽셀 단위로 비교하여, 이 차이를 최소화하는 방향으로 네트워크를 학습
- 위와 같은 방식으로 학습을 합니다. 하지만 이와 같은 방식만을 사용할 시 위치정보에 대한 큰 문제가 발생합니다. 아래는 VGG 16을 예시로 이 문제를 기술해보고자 합니다.
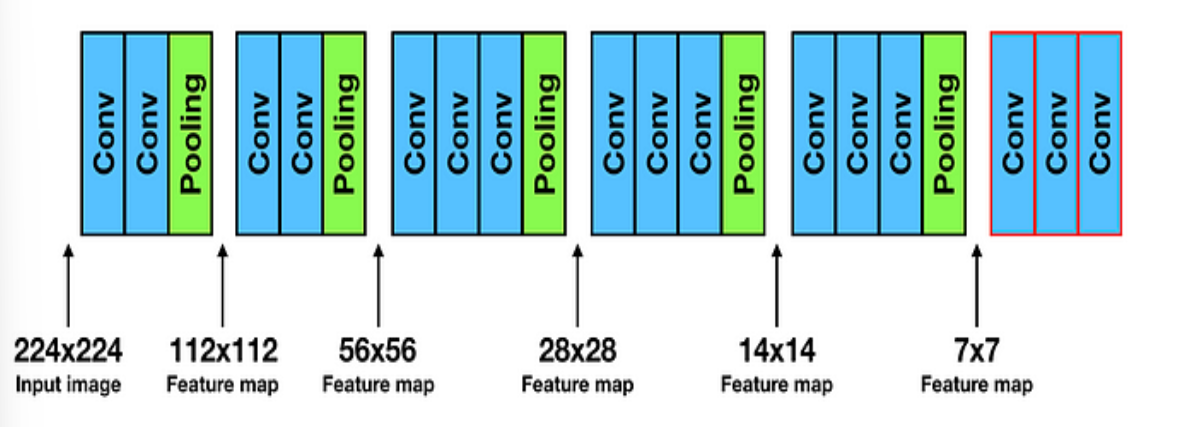
* VGG16에서 입력 이미지의 크기가 224 x 224이지만, 해당 네트워크에서 사용되는 2x2 Pooling을 1번 거치게 되면 전체 맵의 크기는 절반으로 줄어들게 됩니다.
* 위 맵에서는 총 5번의 2x2 크기의 Pooling Layer를 거치게 되면, 총 2의 5승, 즉 32(=2x2x2x2x2)만큼 입력 맵의 크기가 줄어들게되어 결국 7x7 ( 7 = 224 / 32) 의 맵이 나오게 됩니다.
* 이 말인 즉, 마지막 Featurer map의 1 pixel은 입력 이미지의 32pixel을 대표하게 되며, 결국 픽셀의 정보들이 축약되어 최종 feature map에 나타나게 됩니다.
* 이렇게 축약되어 진 feature map의 정보를 바탕으로, 입력 이미지의 map의 크기와 동일하게 Up sampling을 거친다고 하더라도 결국 축약된 정보를 복사하거나 보간(Interpolation)을 활용해 재현하기에 이미지의 디테일에 관한 정보를 재현할 수 없다는 문제가 생깁니다. 아래는 Interpolation의 예시 입니다.
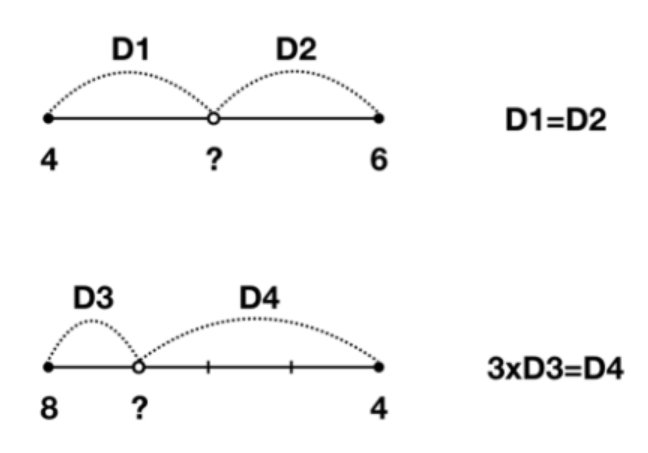
(즉, 특정 값의 사이 값을 Linear하게 추정하는 방법입니다. 이는 Linear 한 값만을 추정할 수 있다는 한계를 지니고 있습니다.)
* 이를 해결하기 위해 사용되는 것이 Transposed Convolution 입니다. 물론, 이 방법 또한 세부적인 이미지의 디테일 정보를 재현하기에는 제한된다는 단점이 있기에 이를 활용하는 것만으로는 부족하다는 문제가 있습니다. 아래는 Tranposed Convolution(또는 Deconvoltuion이라고도 불림)의 예시입니다.
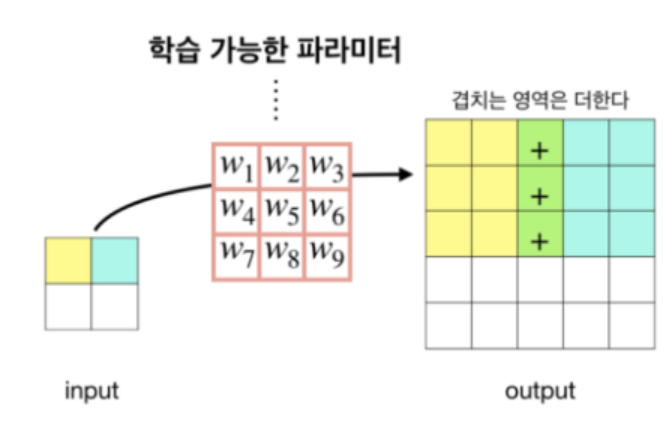
(위의 그림과 Input의 픽셀을 filter를 통해 map의 크기를 키운 뒤, 겹치는 영역은 서로 더하는 형식의 방식을 활용하기도 합니다.)
- Skip Architecture
* 이미 소실된 정보를 Interpolation 또는 Transposed Convolution을 활용하더라도 이미지의 정보 중 소실된 Detail들을 재현하기에는 재한이 있는 방법들입니다. 이를 보완하기 위해 고안된 방법이 Skip Architecture입니다.
* 이를 보완하기 위해, 단계별로 Upsampling 된 feature map에 Down sampling 과정에서 도출된 feature map을 더하는 방법을 통해 위치 정보 손실을 최소화하자는 것이 Skip Architecture의 아이디어 입니다.
이를 본 논문에서는 아래와 같은 표로 정리했습니다.
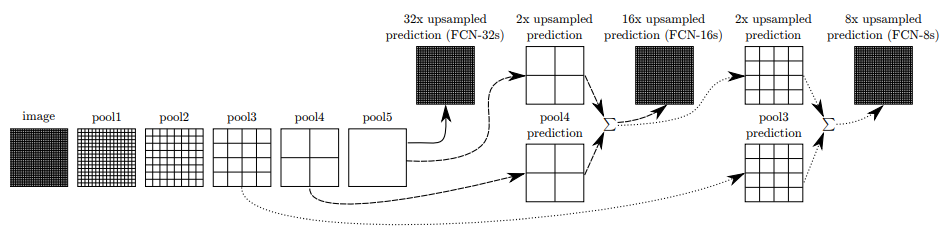
위에서는 FCN-32s, FCN-16s, FCN-8s라는 모델을 제시해 그 결과를 제시하고 있으며 아래와 같이 각 모델들의 결과가 점점 Ground Truth에 가까워지는 모습(이미지의 디테일이 원본과 더 유사해지는 모습)을 보이게 됨을 알 수 있습니다.

1) FCN - 32s

* 이는 Skip Architecture를 적용하지 않은 방법입니다. 5번의 convolution block을 통과하여 이미지 맵의 크기가 1/32로 줄어든 맵을 Upsampling을 활용해 한번에 원본의 크기로 복원한 방법입니다.
(1개의 convolution block에는 2x2 pooling layer가 1개씩 있고, 이를 거치면 이미지의 크기가 절반씩 줄어듭니다)
* 이렇게 만들어진 segmentation map은 위 결과(Pixelwise Accuracy와 IU 결과)에서 보듯, Ground Truth에 비해 경계선을 나누는 디테일이 부족한 모습이 보입니다.
2) FCN-16s

* 5번의 pooling을 거친 feature map을 1번의 2x upsampling 과정을 거친 맵과 4번째 pooling 과정을 통해 도출된 feature map을 더해줍니다. (위 그림에서 2x2로 나뉘어진 up sampling 과정의 맵과 down sampling 과정의 맵을 더해주는 것입니다)
* 이 과정을 통해서 만들어진 맵을 16배로 Upsampling 해주어 원본 이미지의 크기로 feature map을 만들어 줍니다.
* 이렇게 만들어진 segmentation map은 위 결과(Pixelwise Accuracy와 IU 결과)에서 보듯, FCN-32s에 비해 더 디테일한 부분이 살아 있지만 아직 Ground Truth에 비해 경계선을 나누는 디테일이 부족한 모습을 보입니다.
3) FCN-8s
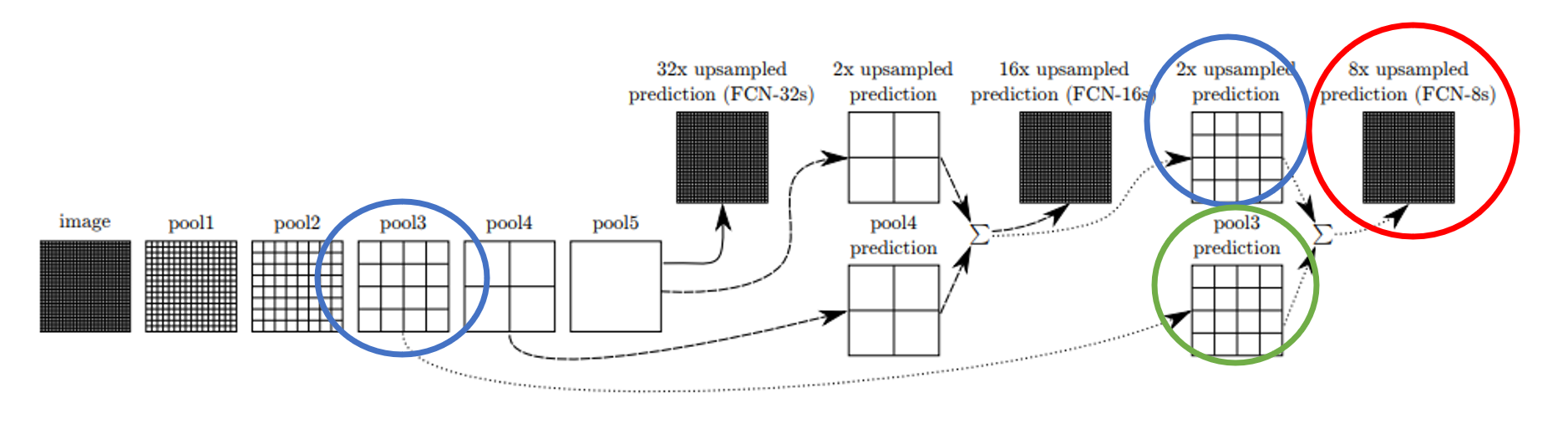
* 이번에는 5번의 Pooling을 거친 feature map을 2번의 2x Upsampling 과정을 거친 맵과 3번째 Pooling 과정을 통해 도출된 feature map을 더해줍니다. ( 위 그림에서 4x4로 나뉘어진 Upsampling 과정의 맵과 Down sampling 과정의 맵을 더해주는 것입니다.)
* 이 과정을 통해 만들어진 맵을 8배 Up sampling 하여 원본 이미지의 크기로 feature map을 만들어줍니다.
* 이렇게 만들어진 segmentation map은 위 결과(Pixelwise Accuracy와 IU 결과)에서 보듯, FCN-32s과 FCN-16s에 비해 더 디테일한 부분이 살아 있음을 알 수 있습니다.
2. 정리
- 해당 논문은 기존의 Image Classification의 구조를 변형하여 Image Segmentation에 활용할 수 있게 했다는 점에서 큰 기여를 가지고 있습니다. 이는, 기존에 ImageNet이라는 대량의 학습 데이터로 학습된 모델들의 정보를 Segmentation에도 활용할 수 있다는 점에서 큰 의의를 가지고 있습니다.
* 이를 위해 마지막 Fc Layer가 아닌 1x1 Convolution Layer를 활용해 Pixel 단위로 Class 정보를 나타낼 수 있게 하였습니다.
- 또한, Skip Architecutre를 활용하여 Convolutional Block을 거치면서 이미지 크기가 작아진 Down Sampled 된 feature map을, 다시 원본 크기의 형태로 복원하는 Upsampling 과정을 거치는 동안 발생하는 이미지의 지역정보 손실이라는 문제를 해결하였다는 점에서 큰 의의를 찾을 수 있습니다.
* 이에 대한 아이디어에 착안하여 Image Segmentation에 큰 기여를 한 U-Net 모델이 나오게 된 배경 논문 이기도 합니다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with 파이썬] 크로스 엔트로피(Cross Entropy) (0) | 2023.11.03 |
|---|---|
| [딥러닝 with 파이썬] (논문 리뷰)SegNet이란? (1) | 2023.11.01 |
| [딥러닝 with 파이썬] 배치(Batch)란? / 배치정규화(Batch Normalization) (1) | 2023.10.29 |
| [딥러닝 with 파이썬] U-Net 모델 구현하기 (Semantic Segmentation) (0) | 2023.10.28 |
| [딥러닝 with 파이썬] Segmentation 평가지표 (Pixel Accuracy, IOU, Dice Coefficient(F1 score), Precision & Recall 등) (0) | 2023.10.27 |




댓글