
이번에 알아볼 논문은 25년 1월 22일 따끈따끈하게 나와서 큰 파장을 주고 있는
"DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning"
이라는 논문이 되겠습니다.

1. DeepSeek-R1 : 들어가기 전
"DeepSeek-R1"은 강화 학습(Reinforcement Learning, RL)을 통해 대형 언어 모델(LLM)의 추론 능력을 향상시키는 방법론을 제안하고 있습니다. 이 논문은 LLM의 reasoning(추론) 능력을 개선하는 데 있어 RL의 강력한 잠재력을 보여주었습니다.
본격적으로 논문 리뷰를 하기 전에 기존에 LLM을 학습하는 방식인 Self-Supervised Learning 기반 방법과, DeepSeek-R1에서 제안하는 방법에 대해서 간략히 비교해보겠습니다.
1) Self-Supervised Learning(SSL) 기반 학습 방식
- SSL은 대량의 비라벨(unlabeled) 데이터에서 자체적으로 학습 신호를 생성하여 모델을 학습하는 방식입니다. 주로 데이터의 구조를 기반으로 한 예측 문제(Pretext Task)를 통해 학습이 이루어집니다.
- 특징
* 일반화된 학습: 광범위한 데이터 패턴을 학습하여 다목적 사용 가능.
* 라벨이 불필요: 대량의 비라벨 데이터를 활용하여 확장 가능.
* 사전 학습 단계: 주로 특정 태스크에 직접적으로 최적화되기보다는 사전 학습(pretraining)으로 활용됨.
* LLM에서의 적용: SSL은 언어 모델이 방대한 텍스트 데이터를 기반으로 문맥이나 패턴을 이해하도록 학습합니다. 대표적으로, GPT와 같은 모델은 SSL로 사전 학습되며, 이후 특정 태스크에서 미세 조정(fine-tuning)됩니다.
ex) GPT: Pretext Task로 다음 단어 예측(Next Word Prediction)을 사용.
예: "오늘 날씨가 매우" → 모델이 "좋다"를 예측.
BERT: Masked Language Modeling(MLM)을 사용하여 랜덤으로 가린 단어를 예측.
예: "나는 [MASK]에 갔다" → "학교"를 예측.
2) Reinforcement Learning(RL) 기반 학습 방식의 개념
- 강화 학습(RL)은 보상 신호(reward signal)를 활용하여 모델이 특정 작업에서 성능을 최적화하도록 학습하는 방법입니다. 여기서 모델은 환경과 상호작용하며 행동(policy)을 학습하고, 각 행동에 대해 보상을 받아 다음 행동을 더 나은 방향으로 조정합니다.
- 특징
* 목표 지향적: 특정 작업에서 성능을 직접적으로 개선하도록 보상을 설계.
* 데이터 효율성: 적은 데이터로도 보상을 기반으로 학습 가능.
* 지속적 상호작용: 모델이 환경(데이터)과 상호작용하면서 스스로 학습.
* LLM에서의 적용: RL은 모델이 '출력의 품질'을 기준으로 학습하게 만듭니다. 예를 들어, 모델이 논리적으로 일관된 답변을 생성하거나, 수학 문제를 풀 때 정답을 내놓는 경우 높은 보상을 받습니다.
ex) DeepSeek-R1: LLM은 <think> 태그 안에 추론 과정을 작성하며, 답이 정확하면 높은 보상을 받음.
예: "문제: 2x + 5 = 15. <think> 양변에서 5를 뺍니다. x = 5. </think> 답변: 5"에서 정확한 풀이 과정과
답을 보상으로 강화.
ChatGPT: RLHF(Rewarded Learning from Human Feedback)를 활용하여 사람의 피드백에 기반해
모델 출력을 개선. 잘못된 답변(불친절한 응답 등)에 대해 낮은 보상을 부여하며 학습.
LLM을 학습시킬때 이 두가지 학습 방식에 대한 차이를 요약정리해보면 아래표와 같습니다.
| 특징 | RL 기반학습 | SSL 기반 학습 |
| 목적 | 특정 태스크(수학, 코딩 등)에서 성능 최적화 | 광범위한 데이터에서 일반적 언어 패턴 학습 |
| 학습 신호 | 보상(reward)을 기반으로 행동(poliycy) 학습 | 데이터에서 생성된 예측 문제(Pretext task)로 학습신호 생성 |
| 데이터 의존성 | 적은 양의 고품질 데이터로도 학습 가능 | 대량의 비라벨 데이터 필요 |
| 유연성 | 특정 작업에 맞게 즉각적으로 학습 | 태스크에 맞춰 별도로 Fine tuning이 필요 |
| 모델 행동의 제어가능성 | 보상 설계를 통해 모델 출력 품질을 직접적으로 개선 가능 | 사전 학습 단계에서는 모델의 출력 품질을 간접적으로 제어 |
| 예시 | ChapGTP(RLHF), AlphaGo, DeepSeek-R1 | GPT, BERT, RoBERTa |
3) 예시를 통한 LLM 학습 간 RL 방식과 SSL 방식의 차이점 확인
예시 1) 수학 문제 풀이
- RL 기반 학습:
*모델이 수학 문제 풀이 과정을 직접 생성.
* 잘못된 풀이 단계에서 낮은 보상을 받고, 정확한 풀이를 통해 높은 보상을 얻음.
* 결과: 모델이 점차 추론 과정(Chain of Thought)을 학습하여 논리적인 풀이를 생성.
- SSL 기반 학습:
* 대량의 수학 관련 데이터를 기반으로 학습.
* 학습된 모델은 기존 데이터에서 본 패턴에 따라 정답을 예측하지만, 풀이 과정이 명확하지 않을 수 있음.
* 결과: 정답률은 높을 수 있으나, 풀이 단계가 명확하지 않아 추론 능력이 부족.
예시 2) 고객 서비스 챗봇
- RL 기반 학습:
* 고객의 긍정적 피드백이 보상으로 작용. 모델이 친절하고 정확한 응답을 생성하도록 학습.
* 결과: 실시간 상호작용과 피드백을 통해 대화 품질 지속 향상.
- SSL 기반 학습:
* 기존 대화 데이터로부터 문맥 패턴을 학습.
* 결과: 특정한 응답을 잘 생성하지만, 실시간 피드백 반영은 어려움.
2. DeepSeek-R1 : 논문 리뷰
1) DeepSeek-R1
- DeepSeek-R1은 LLM의 추론 능력을 강화하기 위해 혁신적인 접근법을 제안합니다. **자기 지도 학습(Self-Supervised Learning)**이 주로 대량의 비라벨 데이터와 사전 과제를 사용해 일반적인 데이터 패턴을 학습하는 데 초점을 맞춘 반면, **강화 학습(RL)**은 명시적 피드백 신호를 통해 특정 태스크에서의 성능을 직접적으로 최적화합니다. RL은 모델이 작업별 목표(예: 정답 정확성, 논리적 일관성)에 따라 출력을 개선하도록 유도합니다.
2) 주요 내용
- DeepSeek-R1-Zero: RL만을 사용해 학습된 모델로, 감독 학습 데이터를 전혀 사용하지 않음.
- DeepSeek-R1: 다단계 학습과 Cold Start 단계를 통해 추론과 가독성을 개선한 강화형 모델.
이 논문은 Reflection과 Self-Verification 같은 자율 추론 행동을 강화하기 위해 RL을 활용하며, 기존의 데이터 중심 감독 학습 접근법(SSL 등)과 차별화를 두고 있습니다.
3) 주요 Contributions
a) 대규모 RL 후속 학습 : DeepSeek-R1-Zero는 초기 감독 학습 없이 RL을 직접 적용하여 다음과 같은 강력한 추론 패턴을 학습합니다
* 자체 검증(Self-Verification): 출력 결과를 재검토하여 정확성을 평가.
* 반사(Reflection): 이전 추론 단계를 다시 살펴보고 개선.
* 연쇄 추론(Chain-of-Thought, CoT): 문제 해결을 위한 단계별 상세 설명 생성.
b) DeepSeek-R1의 향상된 학습 파이프라인
* DeepSeek-R1은 4단계 학습 파이프라인을 통합합니다:
* Cold Start: 긴 CoT 예제를 포함한 소량의 고품질 데이터로 초기 RL 학습 안정화.
* Reasoning-Oriented RL: 코딩, 수학, 논리 문제 등 특정 태스크를 중심으로 RL 수행.
* Supervised Fine-Tuning(SFT): Rejection Sampling을 활용해 고품질 추론 데이터를 선별.
* Reinforcement Learning for All Scenarios: 다양한 태스크에서 인간 선호도를 반영하도록 최적화.
c) 소형 모델로의 지식 전이(Distillation)
* DeepSeek-R1의 추론 능력은 Qwen 및 Llama 시리즈와 같은 소형 모델로 증류됩니다. 이를 통해 소형 모델에서도 고성능 추론이 가능하며, 확장성과 접근성을 입증합니다.
3) 방법론
- DeepSeek-R1-Zero: 순수 RL 학습
* DeepSeek-R1-Zero는 GRPO(Group Relative Policy Optimization) 알고리즘을 사용하여 RL을 적용합니다.
*보상 모델링(Reward Modeling):
정확도 보상(Accuracy Rewards): 규칙 기반 방식으로 정답을 검증.
형식 보상(Format Rewards): 구조화된 추론 프로세스를 준수할 경우 보상.
학습 템플릿(Training Template):
모델이 <think> 태그 안에 추론 과정을 명시적으로 기록하도록 설계.
* 예시 : "방정식의 해를 구하라 : X^2 = 16"
<think> 방정식을 풀기 위해 양변의 제곱근을 취합니다. x = ±4 </think>
답변: ±4
* 성과
AIME 2024 벤치마크에서 RL만으로 Pass@1 정확도가 **15.6% → 71.0%**로 상승.
모델이 스스로 추론 전략을 개발하는 "Aha Moments" 경험.
- Cold Start 및 다단계 학습
* DeepSeek-R1은 초기 RL 학습의 불안정을 해결하기 위해 Cold Start 데이터를 사용합니다
* 고품질 데이터: 명확하고 가독성 높은 추론 예제로 구성.
* Rejection Sampling: 품질이 낮은 데이터를 걸러내고 고품질 데이터를 선택.
4) 실험결과 (벤치마크 대비 성능)
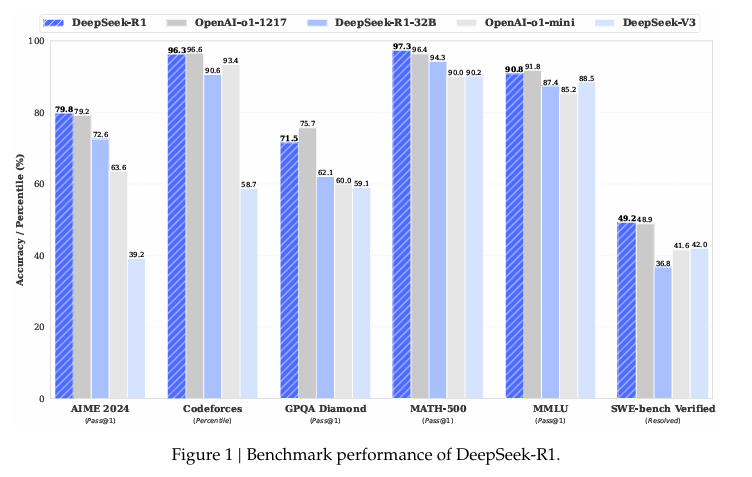
각각의 성능 테스트에서 OpenAI의 GTP 01 series에 대비해서 좋은 성능을 보이고 있음.
- AIME 2024 성능
* RL 학습 후 Pass@1 정확도가 **15.6% → 71.0%**로 상승.
* 추론 과정의 가독성과 정확성이 모두 개선.
- "Aha Moments" 발견
* 모델이 스스로 문제 해결 전략(예: 재검토, 대안 탐색)을 학습하며 전환점(Aha Moments)을 경험.
- Distillation 성능
* Distilled 모델(Qwen-32B)은 Pass@1 성능에서 **72.6%**를 달성하며, 작은 모델에서도 높은 성능을 보임.
'딥러닝 with Python' 카테고리의 다른 글
| [개념정리] FLOPS란? FLOPS(Floating Pont Operations Per Second) (0) | 2025.02.18 |
|---|---|
| [딥러닝 with Python] GRPO란? (Group Relative Policy Optimization) (0) | 2025.01.30 |
| [딥러닝 with Python] NCE란?(Noise Contrastive Estimation) (1) | 2024.12.15 |
| [딥러닝 with Python] GraphSAGE를 활용한 논문 분류(Node Classification) (1) | 2024.12.09 |
| [딥러닝 with Python] LangGraph란? (0) | 2024.12.07 |




댓글