
1. Latent Diffusion Models (LDMs)
- Latent Diffusion Models는 이미지 생성에서 효율성과 품질을 모두 고려한 방법을 말합니다.
- 이때 두 가지 주요 학습 단계를 거치게 되는데, "Semantic Compression"과 "Perceptual Comperssion"입니다.

1) Semantic Compression
* Semantic Compression은 데이터를 추상적인 형태로 표현하여 그 핵심적인 의미를 인코딩하는 단계로, 원래 이미지가 가지고 있는 맥락이나 구조를 최대한 보존하면서도 세부적인 요소는 생략하는 방식을 말합니다.
* 이 단계에서 이미지의 중요한 특징을 학습하며, 이미지의 전반적인 의미를 유지하는 방향으로 압축을 합니다.
2) Perceptual Compression
* Perceptual Compression은 높은 주파수의 세부 요소를 제거하여 시각적으로 중요한 정보를 중심으로 압축하는 단계입니다.
* 이를 통해 고해상도 이미지의 모든 세부 요소 대신, 이미지의 전체적인 느낌과 중요한 시각적 정보를 유지하는데 초점을 맞추게 됩니다. 이를 통해 고빈도의 정보가 사라지지만 이미지는 원본과 유사한 시각적 특성을 가지게 됩니다.
-일반적인 Diffusion Model에서는 이 두 단계는 특히 고해상도 이미지를 다룰 때 많은 시간과 계산 자원을 소모하는 문제점이 있는데요
* 특히, Perceptual Compression의 경우, 자원소모가 크고 생성 속도가 느려지는 한계로 작용합니다.
- 이를 해결하기 위해 AutoEncoder를 활용하였습니다. Auto Encoder는 이미지의 고주파 세부정보를 제거하면서, 전체적인 시각적 의미를 유지하는 역할을 하는데요.
- 이때 Auto Encoder를 활용시 다음과 같은 장점이 생기게 됩니다.
* Inductive Bias 보존 : 원래 이미지의 의미와 고유한 특징을 잘 반영하도록 정보를 압축하기에 Inductive Bais가 보존이 됩니다.
* 효율성 향상 : Diffusion Model 자체에서 직접 High Frequency 요소를 제거하지 않아도 되니, 생성 과정의 효율성이 높아지게됩니다.
- Transformer와 Cross Attention의 활용
* Stable Diffusion 모델은 텍스트 기반 조건에 맞는 이미지를 생성할 때 매우 효과적이며, 이를 위해 Transformer 기반의 Text Encoder와 Cross Attention Layer를 활용합니다.
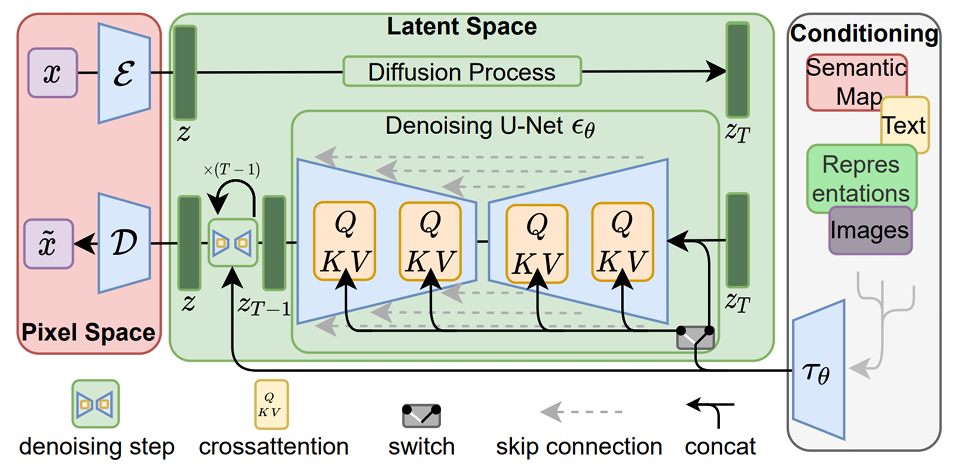
1) Text Encoder Block
* 이는 Transformer 기반의 텍스트 인코더를 사용하며, CLIP 의 텍스트 인코더를 활용해 텍스트 정보를 임베딩합니다.
* 이 임베딩은 텍스트의 의미를 잘 표현하여, 이후 U-Net의 Denoising 과정에서 이미지 생성에 필요한 조건 정보로 활용됩니다.
2) Cross Attention Layer
* Stable Diffusion의 U Net 구조에는 Corss Attention 레이어가 포함되어 있으며, 텍스트 정보와 이미지 생성을 효과적으로 연결해줍니다.
* Cross Attention은 주어진 텍스트 임베딩을 기반으로, 이미지를 생성하는 각 단계에서 텍스트 조건을 반영하도록 도와줍니다.
* 위 그림에서의 Cross Attention은 Q, K, V로 구성된 블록들이며, Query는 이미지의 Latent representation, Key와 Value는 텍스트 임베딩인 tau theta입니다.
이를 통해 전반적인 이미지 생성 과정을 요약해보면

* 먼저 Pixel Space에서 이미지를 Latent space로 임베딩
(이때 Auto Encoder를 통해 입력 이미지를 압축하여 임베딩 후 학습된 weight를 Frozen)

* 변환된 z 는 Diffusion Process를 통해 점진적으로 노이즈를 제거하는 과정에 들어가게 되는데, 이 과정이 Denoising U-Net이고 이 과정에서 Cross Attention을 통해 텍스트 조건을 반영하여 이미지가 점차 노이즈가 제거된 상태로 만들어감
(이때는 Classifier Free Guidance를 활용)
* 최종적으로, 디코더인 D를 통해 Latent representation z를 다시 pixel space의 이미지로 변환하여 최종 이미지 생성
과 같습니다.
- 이때의 손실함수는

'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with Python] Self Supervised Learning(SSL) (2) : Pretext 활용 (3) | 2024.11.15 |
|---|---|
| [딥러닝 with Python] Self-Supervised Learning(SSL) (1) (0) | 2024.11.14 |
| [딥러닝 with Python] Weakly Supervised Learning 이란? (1) | 2024.11.13 |
| [딥러닝 with Python] 디퓨전 모델(Diffusion Model) (3) / Classifier Guidance (0) | 2024.11.12 |
| [딥러닝 with Python] 디퓨전 모델(Diffusion Model) (2) DDIM (0) | 2024.11.11 |




댓글