
1. 인공신경망(Artificial Neural Network / ANN)
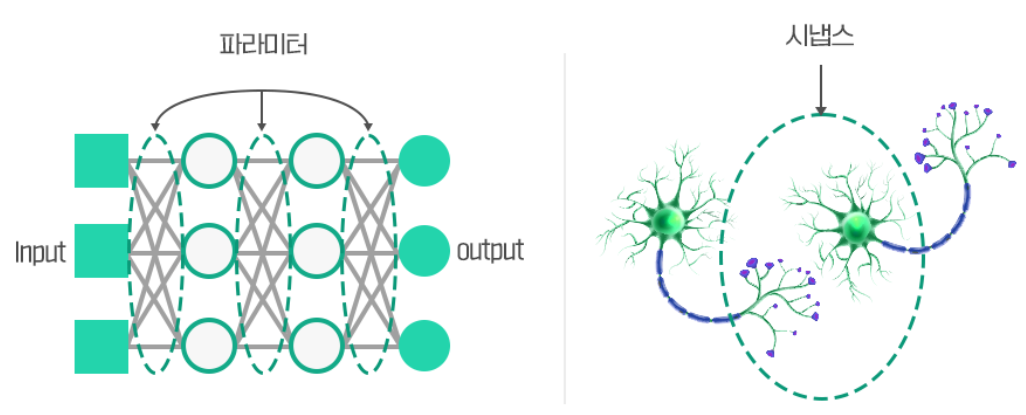
1) 인공 신겨망의 개념
- 인공신경망이란, 의미있는 표현(Respresentation)들을 도출할 수 있는 여러 층들을 활용해 주어진 데이터로부터 Representation을 배우는 네트워크로, 사람의 뇌의 구조에 영감을 받아서 만들어진 네트워크입니다.
- 깊은 층(Deep layers)들을 활용해 복잡한 표현들을 학습해낼 수 있으며
- 특히, ReLU와 같은 비선형함수들을 활용해 비선형적인 표현들까지도 학습할 수 있는 구조입니다.
2) ANN의 구성
- 어떻게 연결할 것인가?
* Dense layer(일반적인 MLP) / Convolutional (Convolutional kernel 등), Recurrent(RNN 및 해당 계열의 LSTM, GRU, SSM 등), Pooling(Min, Max, Avg pooling 등), Flattening(각 element를 한개씩 다 쭉 펼쳐놓는) 등 다양한 구성요소들을 활용해서 전체적인 형상을 구조를 말합니다.
- Loss functions
* 학습을 위해 각 epoch간 발생하는 결과물(Predictions)에 대해 어떻게 평가할지를 의미하니다.
* Mean Squared Error(회귀), Cross Entropy(분류) 등이 대표적입니다.
- Optimizer
* 어떻게 학습 간 각 네트워크의 weight를 업데이트할 것인지를 의미합니다.
* 학습률(Learning rate)의 개념을 적용해 점차 weight를 업데이트하며, 이때 Scheduling을 적용해서 보다 효율적으로 학습률을 적용합니다.
* Stochastic gradient descent, momentum, RMSProp, Adam 등 다양한 방법들이 제시되어 왔습니다.

[출처 : [Deep Learning] Optimizer | 6mini.log ]
스케쥴링과 관련해서는 제 지난 포스팅을 참조하시면 되겠습니다.
[개념 정리] 스케쥴러란? Scheduler (딥러닝 학습)
3) 데이터 전처리와 가중치 초기화
- 데이터 전처리는 머신러닝의 feature engineering 정도까지는 아니지만, 학습간 gradient vanishin이나 exploding과 같은 학습간에 부정적인 영향을 끼치는 부분을 없애기 위해 기본적으로 합니다.
- 대표적으로, zero centering, normlization 등이 있습니다.

- Weight initialization은 신경망 학습을 시작할 때 각 층의 가중치를 특정값으로 초기화하는 과정으로, 이를 통해 모델 학습의 수렴 속도와 성능에 긍정적인 영향을 미치기에 활용됩니다.
- 대표적으로, Zero initialization(모든 가중치를 0으로 초기화), Random initialization(모든 가중치를 무작위로 초기화), Xaiver Initialization(활성화 함수가 선형 또는 sigmoid인 경우 활용하며, 이전 층의 노드수에 기반하여 가중치를 분산), He Initialization(ReLU와 같은 비선형 활성화 함수에 적합한 방법이며, 이전 층의 노드수의 제곱근으로 가중치를 나눠 설정), Lecun Initialization(Tanh와 같은 활성화 함수에 적합한 초기화 방법)
등 다양한 방법들이 제시되어 왔습니다.
4) Generalization
- Generalization이란, AI모델이 학습용 데이터 뿐만 아니라 새로운 데이터에 대해서도 잘 작동하는 능력을 의미합니다. 이는 학습 데이터에만 잘 작동하는 Overfitting(과적합) 문제를 해결하기 위함이기도 하며, 학습 데이터와는 다른 도메인에서의 데이터에서도 학습 능력이 잘 발휘할 수 있도록 하기 위함이기도 합니다.
- 이를 위해서는
a) 보다 좋은 고품질의 데이터를 많이 얻는 방법
b) Data Augementation
c) Weight Decay(학습하는 가중치 업데이트 방식에 L2 Regularization 등의 규제 적용)
d) Dropout (학습간 랜덤하게 일부 노드의 가중치를 0으로 만들어서 없애버림)
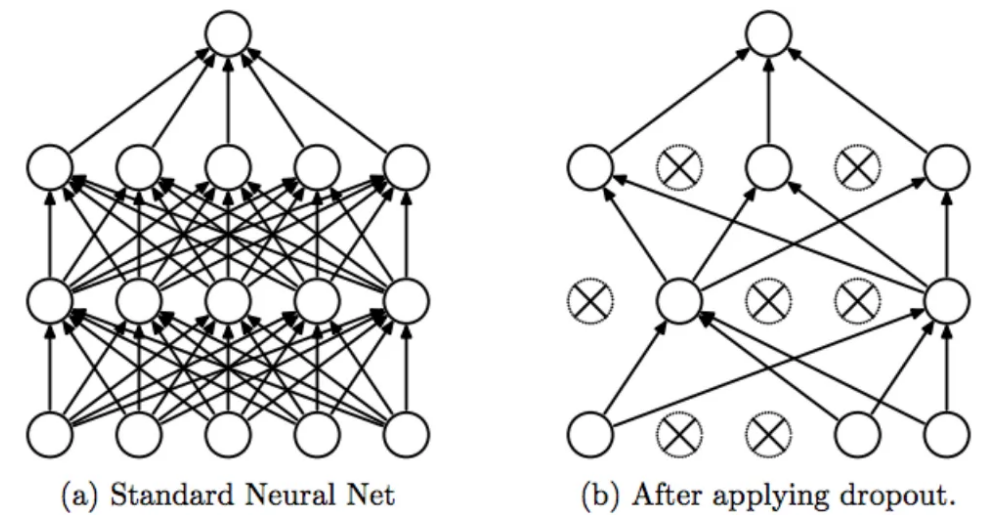
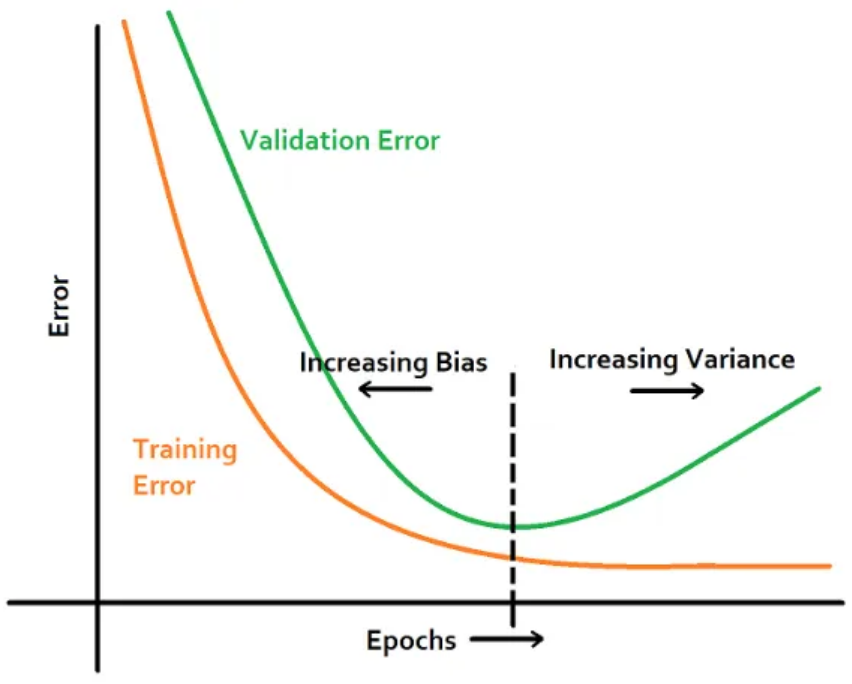
e) Early Stopping(학습된 모델로 Validation set의 loss가 정해진 숫자이상 업데이트 되지 않으면 학습을 중단, 이를 통해서 하이퍼 파라미터 튜닝을 함)
등이 적용되고 있습니다.
2. Data Augmentation in Vision task
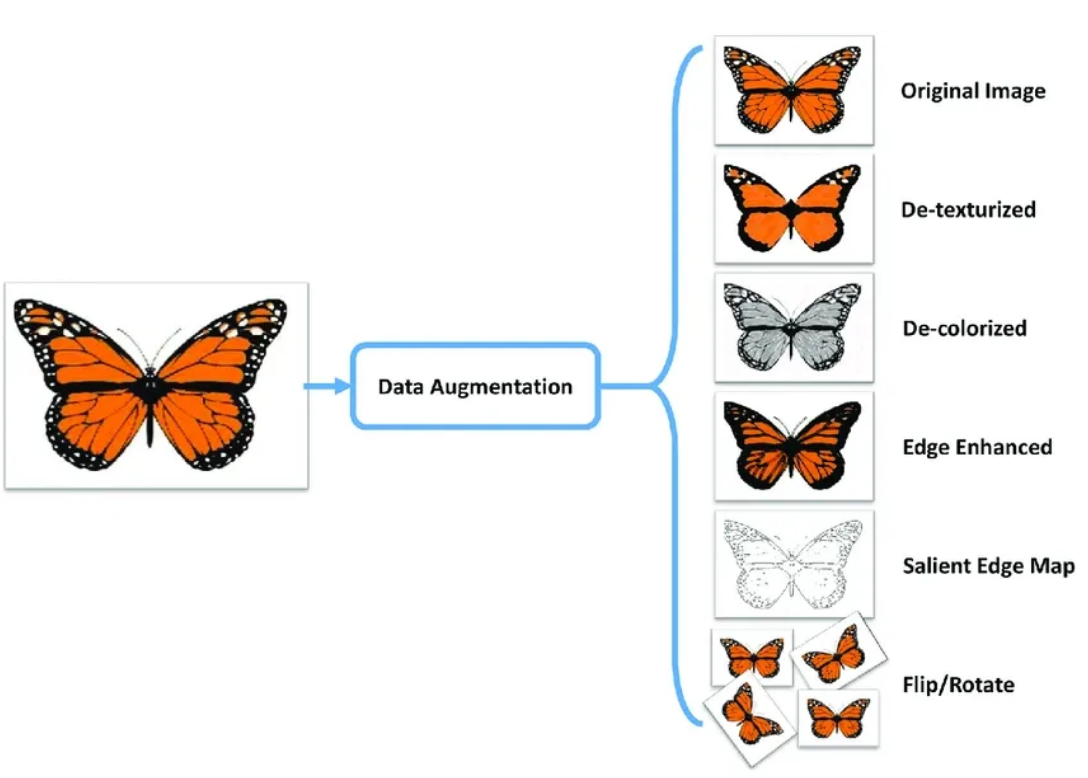
- Data Augmentation은 학습용 데이터가 불충분할 경우 데이터를 augment할 경우 결과가 더 좋아짐을 다양한 실험을 통해서 증명되어 온 기법입니다.
- 이를 통해 학습 데이터의 다양한 변이 형태 (형태 변이, 색깔 변이 등등)이 나오게 되어 학습 데이터 수는 더 증가하게 되고, 이를 바탕으로 모델은 데이터의 다양한 패턴을 더 정확하게 분석할 수 있기에 보통 학습에 긍정적인 영향을 끼치는 경우가 많습니다.
- 또한, 기본적인 crop, translation, rotation, stretching과 같이 원본 데이터만을 가지고 증강하는 기법뿐만 아니라 Vision Task 에서는 Mixup / Cutout / CutMix / Augmix 도 활용하고 있습니다.

* Mixup 이란, 학습 데이터로부터 추출된 랜덤한 페어의 데이터를 서로 다른 가중치를 주어서 합쳐 새로운 데이터를 만드는 방법을 말합니다. 이를 통해 학습 간 네트워크가 단순한 선형적인 패턴만을 학습하지 않도록 규제를 걸어주는 방법입니다.
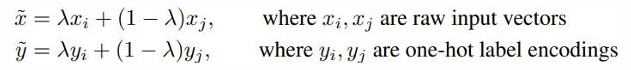
* Cutout은, 학습 이미지의 일부분을 랜덤하게 잘라내버리는 방법으로 학습 데이터 중 Occlusion이 생길 경우 잘 학습해내지 못하는 경우가 생기는데 이에 착안해서 처음부터 학습 시킬때 마치 Occlusion이 되어 있는 것처럼 데이터의 일부를 잘라내버릴 경우 학습 모델이 더 일반화된 특징을 학습할 수 있어 더 좋은 Generalized 된 모델이 나오게 됩니다.
* CutMix는, Cutout에서 한발 더 나아간 기법으로 Cutout이 단순히 일부분을 잘라내서 버렸다면, CutMix는 버린 부분만큼 다른 이미지에서 가져와서 서로를 합성시켜 학습데이터를 만드는 방법입니다. 이렇게 더해진 패치는 학습 모델에게 사진의 일부분으로부터 물체를 인식하기위한 능력을 배양시킴으로써 보다 정확한 localization 능력을 향상시켜줄 수 있게 됩니다.
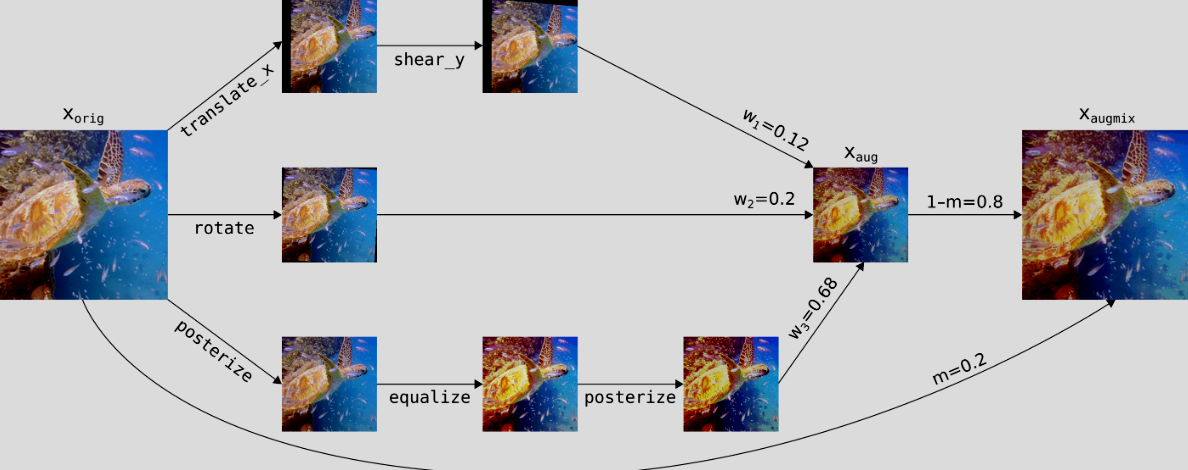
* AugMix 는 각 이미지들의 변이를 만든 뒤 이들을 선형적으로 결합해 변형된 이미지를 만드는 방법입니다.
이는 Mixup과 비슷해보이지만, Mixup은 다른 이미지 2개를 합성한 것에 비해 AugMix는 동일한 이미지를 활용했다는 차이점이 있습니다.
* Random Erasing은 CNN에서 활용되는 Augmentation 방법 중 하나로, 학습데이터의 일부분을 랜덤하게 지운 뒤 해당 부분에 random 한 noise를 추가하는 방법을 말합니다. 이 역시 Occlusion 된 데이터를 더 잘 구분해낼 수 있는 능력을 만들어주는 학습 데이터 셋을 만드는 방법이라고 보시면 되겠습니다.

- 이와 같은 Augmentation은 다음과 같은 장단점이 있는데요
* 장점 : 딥러닝에 적합한 방법 중 하나이며, 네트워크를 튜닝하는 방법보다 쉬우며, 현재 네트워크의 성능을 향상시키는 유용한 방법 중 하나라는 것입니다.
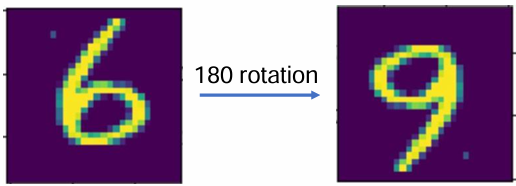
* 단점 : 해당 데이터에 대한 도메인 지식이 필요하다는 부분인데요. 아래 그림과 같이 숫자 6이라는 이미지를 180도 회전을 시키게 되면 9라는 결과물이 나오게되어 전혀 다른 클래스의 데이터를 만들어버린다는 오류가 생기게됩니다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with Python] 순환 신경망(Recurrent Neural Network) (1) | 2024.11.03 |
|---|---|
| [딥러닝 with Python] 합성곱 신경망(Convolutional Neural Network) (1) | 2024.11.02 |
| [개념 정리] Linear probing이란? (0) | 2024.10.31 |
| [개념정리] ELBO란? Evidence Lower Bound란? (0) | 2024.10.30 |
| [개념 정리] 스케쥴러란? Scheduler (딥러닝 학습) (0) | 2024.10.29 |




댓글