
이번에는 트랜스포머(Transformer) 모델에 대해서 알아보겠습니다.
너무나 유명한 논문이죠 "Attnetion is All You Need"를 바탕으로 포스팅을 구성해보았습니다.
1. Transformer
- 2017년 NeurIPS에 발표된 논문 "Attention is All You Nedd"에서 제안한 아키텍처의 이름인 Transformer입니다.

- 해당 모델은 어텐션(정확히는 Multi Head Self Attention)을 활용해서 모델의 성능 및 학습/추론 속도를 향상 시킨 아키텍처입니다. 해당 논문은 자연어 처리(NLP)에서 나오게 되었지만, 이를 바탕으로 다양한 Sequential data의 처리 및 이미지 데이터에서도 트랜스포머를 기반으로한 모델들이 나오게 되었으며, 그 유명한 GPT도 Transformer의 구조를 하고 있습니다.
- 트랜스포머의 아키텍처는 아래와 같습니다.
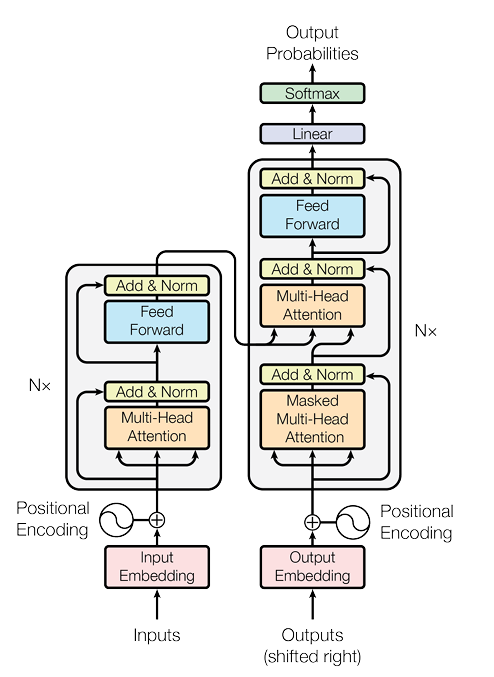
- 이를 조금 더 크게 나누어서 보면 Encoder와 Decoder, 그리고 Positional Encodeing 부분 정도로 나누어 볼 수 있습니다.

- 해당 논문에서 제시한 트랜스 포머는 6개 블록으로 구성된 인코더와 디코더로 이루어져 있으며, 이를 통해 나온 파생 아키텍처들은 이 숫자를 해당 Task에 맞춰 수정하고 있습니다.
* 이때, 모든 인코더와 디코더의 내부 블록은 동일한 똑같은 구조를 취하고 있습니다.

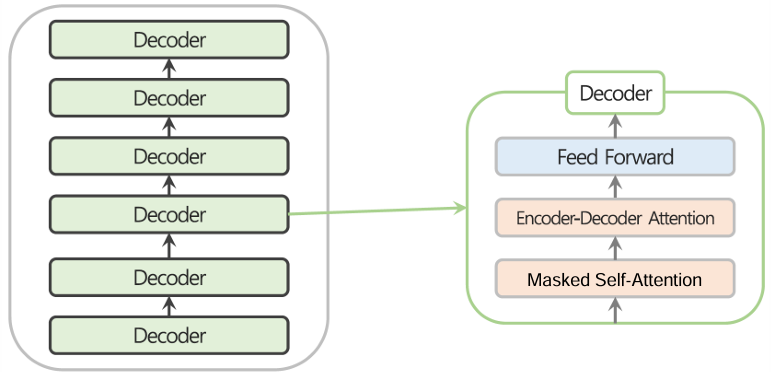
- 이때 인코더와 디코더의 구성은 거의 동일한데, 차이점을 뽑자면
* 인코더는 Masking을 하지 않았고, 디코더 부분에서는 Masking을 했다는 것입니다.

* 이러한 차이로 인해, 인코더는 다양한 데이터들을 임베딩할때 유용하며 이로 통해 나온 파생 모델이 BERT이고, 디코더 부분에서는 Masking Starategy로 인해 생성하는 로직을 배우게되어 이로 인해 나온 파생 모델인 GPT가 있습니다.
- 하지만 여기서 인코더가 모두 동일한 구조라고 할지라도 서로 Weight를 Sharing하지는 않는다는 부분에 대해서는 인지해야 합니다.
- 또한, 트랜스포머에서 자세히 보아야 할 것은 Positional Encoding입니다.
- 입력 데이터가 MLP레이어와 Self Attention을 통해 연산이 되다보니 그 순서를 고려하는 부분이 없었데요. 이를 위해 인코더 또는 디코더 블록에 들어가기 전에 위치 정보를 명확히 하기 위해 Positional Encoding을 진행해줍니다.
* 트랜스포머에서 제안한 포지셔널 인코딩 방식은 고정된 포지셔널 인코딩이며, Sine과 Cosin 함수의 변이형을 활용해서 포지셔널 인코딩을 했습니다.

이를 시각화해보면 다음과 같으며, 임의의 고정된 Offset k에 대해 PE(pos + k)는 PE pos의 선형 함수로 표현될 수 있으므로, 상대적인 위치를 기준으로 Attention 학습이 용이하게 만들어줍니다.


- 위 아키텍처에서 보았듯, 이렇게 나온 PE를 임베딩 된 인풋에 직접 더해주는 방식으로 위치 정보를 주입해주는 것입니다.
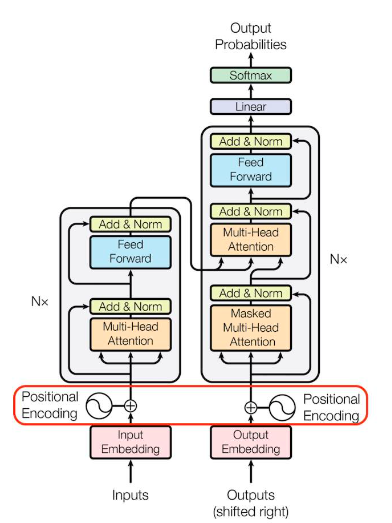
- 이렇게 Input 데이터를 임베딩 후 포지셔널 인코딩을 더해준 다음에는 인코더 또는 디코더로 들어가게 됩니다.


- 이때 위에서 보는 것처럼, Attention(정확히는 Multi Head Self Attention)을 통과한 뒤 학습의 안정성을 위해 Skip connection과 Layer normalization이 진행되고, Feed Forward 네트워크(일반적인 MLP Layer)를 통과 한뒤 역시 Skip Connection과 Layer Normalization이 진행되는 인코더 블록을 여러개(해당 논문에서는 6개) 거치게 됩니다.
- 이제 논문의 핵심 아이디어 중 하나인 Multi Head Self Attention입니다.

- Self Attention의 핵심은 원본 임베딩을 Query, Key, Value로 linear Projection 후 다음과 같은 연산으로 Self Attention Score를 구해서 Input Data 전체에서 특정 단어가 다른 단어들과 어떤 연관성이 있는지를 수치화 하는 것입니다.

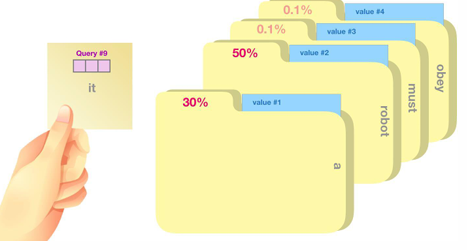
* 이때, Query는 현재 단어의 Representation이라고 보시면 되겠으며, Key는 해당 단어의 label이라고 보시면 되겠고, value는 그 label안에 있는 실제 단어의 Representaiton이라고 보면 되겠습니다.
이는 마치 아래 그림처럼, Query라는 질문을 하면, 여러 문서에서 label 중 연관성 있는 label인 Key를 찾고 그 Key안에 속해있는 정보인 Value를 가져오는 것이라고 보면 되겠습니다.

* Self Attention은 이러한 Attention 과정을 Self로, 즉 본인 데이터를 활용해서 한다는 것이고
Multi head self attention은 긴 시퀀스를 여러개로 나누어서 다른 머리(아키텍처)로 연산한다는 것입니다.
- 과정을 자세히 알아보면
1) 인코더의 인풋 벡터를 활용해 Linear projection을 통해 Query, Key, Value 벡터를 만들어냅니다. 이때 원본 논문에서는 64dim을 활용했습니다.
2) Query 단어와 다른 모든 단어들의 관계, 즉 Attention score를 계산해냅니다.이는 위 식에서 Q와 Transposed 된 K와의 Dot product 연산으로 표현됩니다.

3) 2)에서 계산된 스코어에 원본 차원의 squared root로 나누어 줍니다.
4) 이 결과들을 통합해서 softmax에 보내 distribution을 만듭니다.

5) 이제 이 계산된 Softmax 값을 Value에 곱해줍니다. 이 과정을 통해서 해당 단어와 관련이 있는 단어와의 관계성은 더 높여주고, 관련 없는 단어와의 관계성은 줄여주는 과정을 거치게 됩니다.
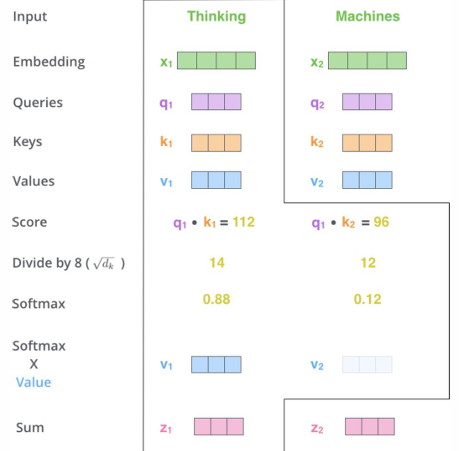
6) 5) 과정을 거쳐 계산된 값들을 전체 더해줍니다.

* 이 전 과정을 요약하면 아래와 같습니다.

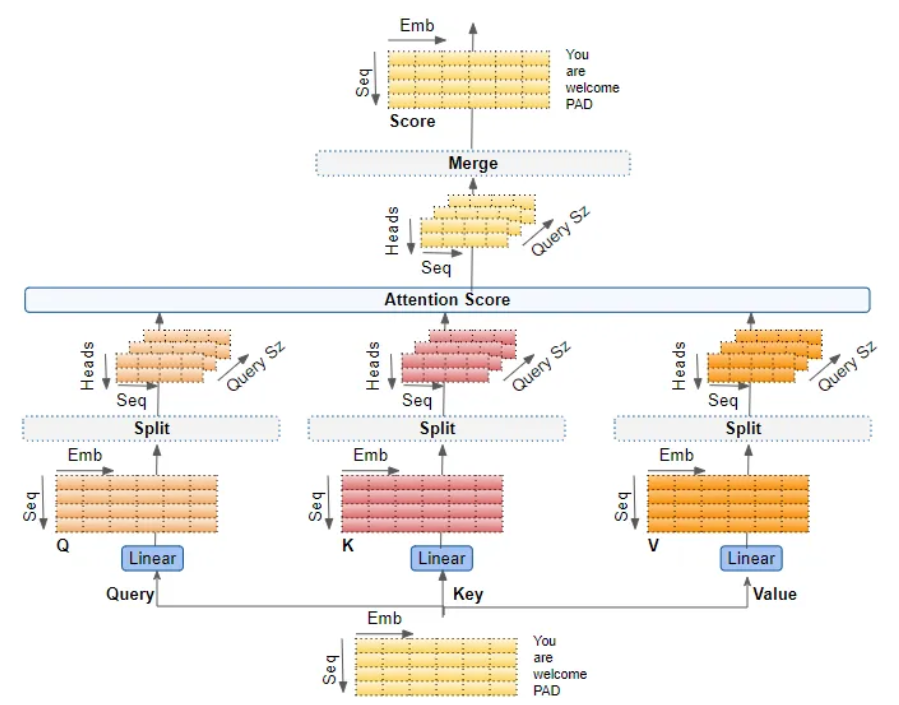
- 이때 Mutli Head Attention이란, 다른 Head가 다른 관계성을 배울 수 있다는 사실에 착안해서 앞서 알아본 Self Attention을 나누어 다양한 Head로 학습하여 결과를 내놓는 것을 말합니다.
- 아래 그림을 통해 확인해보면, Multi Head Attention은 Sequence를 나누는 것이 아닌 Embedding 차원을 나누는 것입니다. 즉, 인풋 토큰의 임베딩을 512차원이라고 하고 8개의 헤드로 분할해서 학습한다면, 각 헤드가 64차원씩을 담당하게 되는 것입니다.
- 각 헤드는 서로 다른 Q, K, V 행렬을 학습해 다양한 관점에서 Attetnion Score를 계산하게 되고, 이것들을 다시 Concatenate하여 원래의 Embedding 차원을 회복하게 됩니다. 그리고 이것을 마지막으로 선형 레이어를 통해 선형 변환을 적용한 것을 최종 결과물로 만들어줍니다.
- Decoder 부분에서 특이하게 봐야할 점은 Masking Strategy이고 이는 생성을 할때 과거 정보만을 활용해 미래를 예측하게 해야한다는 점 때문입니다. 이를 활용해 첫번째 Masked Multi Head Attetion을 진행합니다.


- 또한, 두번째 Mutli Head Attention에서는 Query는 디코더의 이전 레이어로부터 도출하고, Key와 Value는 인코더로부터 도출되어 Multi Head Attention을 함으로써 학습을 진행한다는 것입니다.
이러한 트랜스포머의 가장 큰 장점은 Scalability로
모델의 사이즈와 학습 데이터의 수를 늘릴 수록 그 성능이 향상되는 것입니다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with Python] 비전 트랜스포머(Vision Transformer / ViT) (2/2) (0) | 2024.11.08 |
|---|---|
| [딥러닝 with Python] 비전 트랜스포머(Vision Transformer / ViT) (1/2) (0) | 2024.11.07 |
| [딥러닝 with Python] 어텐션 (Attention Mechanism) (0) | 2024.11.04 |
| [딥러닝 with Python] 순환 신경망(Recurrent Neural Network) (1) | 2024.11.03 |
| [딥러닝 with Python] 합성곱 신경망(Convolutional Neural Network) (1) | 2024.11.02 |




댓글