

1. Mixture of Experts(MoE)란?
- Mixture of Experts(MoE)란, 대규모 모델을 효율적으로 확장하는 기법 중 하나로, 기존 Dense 모델 대비 더 적은 연산량으로도 뛰어난 성능을 달성할 수 있는 기법을 말합니다.
1) 모델 크기와 성능의 관계
- Transformer의 등장을 통해서 Scalability에 대한 가능성이 입증되어 점차 모델들은 더 커지고 더 많은 데이터를 학습하게되었습니다. 즉, 더 큰 모델이 더 나은 성능을 보인다는게 정설이 되었습니다.
- 하지만, 고정된 컴퓨팅 예산 내에서 모델을 키운다는 것은 쉬운일이 아닙니다.
- 특히, Dense 모델을 훈련할 때 모델이 클수록
* 더 많은 연산량 (FLOPs)가 필요하게되고
* 훈련 시간 및 비용이 기하급수적으로 증가하게되며
* 메모리 요구사항이 증가하는 문제가 발생하게 됩니다.
[개념정리] FLOPS란? FLOPS(Floating Pont Operations Per Second)
[개념정리] FLOPS란? FLOPS(Floating Pont Operations Per Second)
이번에는 인공지능 모델의 연산 성능 평가 시 중요한 기준으로 사용되는 FLOPS(Floaintg Point Operations Per Second)에 대해서 알아보겠습니다. 1. FLOPS란? FLOPS(Floating Point Operations Per Second)?- FLOPS(Floating Po
jaylala.tistory.com
2) MoE를 통해 해결할 수 있는 문제
- MoE는 위와 같은 계산 비용과 메모리 요구사항 등의 문제를 해결하면서도, 모델의 크기를 효과적으로 확장할 수 있는 방법을 제시합니다.
- 이때, MoE의 핵심 아이디어는
* 일부 레이어(Feed Forward Network, FFN을)를 여러 개의 전문가(Experts)로 대체하는 것입니다.
* 이를 통해 각 입력 토큰을 적절한 전문가에게 Routing하여 연산량을 줄이는 것입니다.
- 결과적으로, MoE 모델은 동일한 계산 자원 내에서 더 큰 모델이나 데이터셋을 활용할 수 있게되는 것이며, Dense 모델보다 빠르게 동일한 성능을 달성할 수 있게되는 것입니다.
3) MoE의 구성 요소 및 동작 방식
- MoE 구성요소는 크게 두 가지 핵심 요소인, 전문가 네트워크(Experts Network) 와 게이트 네트워크(Gating Network)입니다.

3-1) 전문가 네트워크(Experts Network 또는 Experts)
- MoE에서 FFN 레이어 대신 여러개의 Experts 네트워크를 사용하는데요
- 각 Experts는 독립적인 신경망(보통 FFN)이며, 입력 토큰을 처리하는 역할을 합니다.
- 보통 8~16개의 Experts로 구성하여 특정 입력에 맞게 활성화하도록 합니다.

출처 : https://developer.nvidia.com/ko-kr/blog/applying-mixture-of-experts-in-llm-architectures/
LLM 아키텍처에 Mixture of Experts(MoE)를 활용하기
Mixture of Experts(MoE) 거대 언어 모델(LLM) 아키텍처는 최근 GPT-4와 같은 독점 LLM은 물론 Mixtral 8x7B의 오픈 소스 출시와 함께 커뮤니티 모델에서도 등장하고 있습니다. Mixtral 모델의 강력한 상대적 성
developer.nvidia.com
3-2) 게이트 네트워크(Gating Network)
- 이 Gating Network(또는 Routing Network)는 어떤 입력이 어떤 Experts에게 할당될지를 결정하는 역할을 해줍니다.
- 아래 그림 처럼 More 토큰은 FFN2라는 Experts에게, Parameters라는 토큰은 FFN1에게 Routing되어 지게 됩니다.
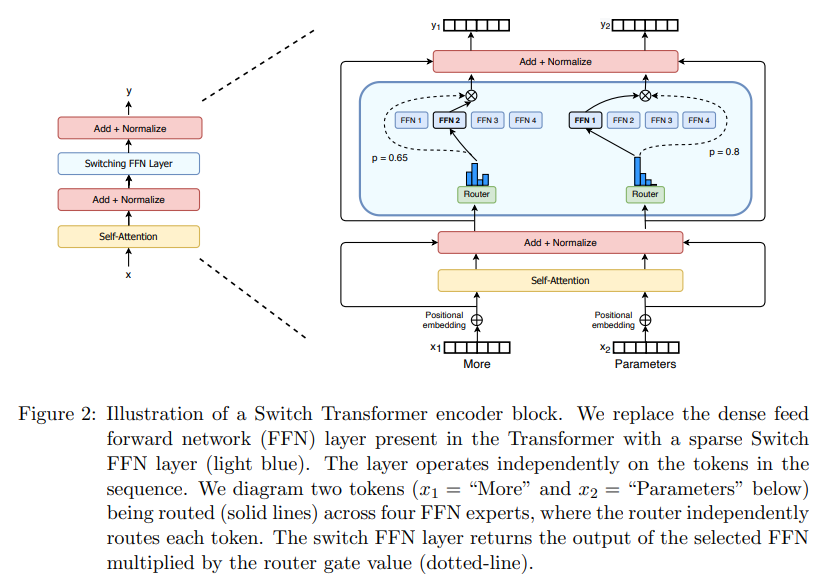
- 이때 Routing 방식은, Hard하게 특정 FFN에게만 할당될 수도 있지만 Soft하게 여러 FFN에 비율을 통해 할당될 수도 있습니다.
4) MoE의 장점과 단점
- Moe의 장점은 아래와 같습니다.
1) 계산량 절감 : Dense 모델 대비 더 적은 FLOPs로 동일한 성능 달성
2) 빠른 추론(Inference) 속도 : 일부 전문가만 활성화되므로 연산량이 줄어듦
3) Scaling 용이 : 파라미터 수를 쉽게 늘릴 수 있어 LLM에 적합
- 이에 반해, MoE의 단점은 아래와 같습니다.
1) Fine tuning 시 과적합 위험 : MoE는 Pretraing 단계에서는 효율적일 수 있으나, Finetuning 시 일반화 성능이 낮아지는 문제가 발생할 수 있음
2) 추론 시 메모리 사용량 증가 : Inference 시 일부 전문가만을 사용하기에 속도가 빠를 수 있으나 결국 모든 전문가들을 VRAM에 할당해야하기에 결국 전체 모델의 크기만큼이 메모리 사용량이 필요함
3) Routing 불균형 문제 : 일부 Experts들에게만 집중적으로 할당이 되는 문제가 발생할 수 있음.
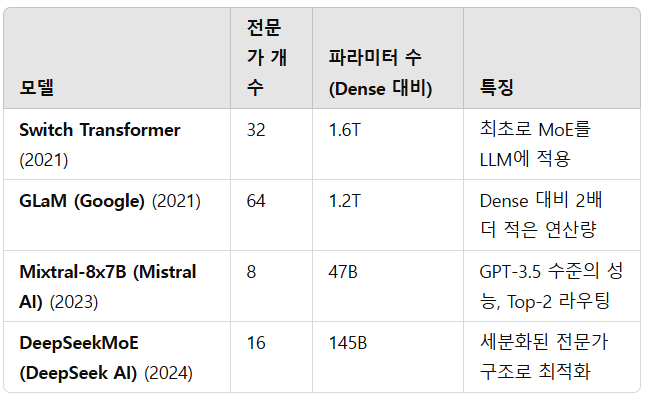
5) 대표적인 MoE 모델




댓글