
이번에는 Invariance를 활용해 Self Supervised Learning을 하는 방법에 대해서 알아보겠습니다.
1. Invariance?
- Inavraicne란, 모델이 입력 데이터의 특정 변환에 영향을 받지 않, 일관된 출력을 유지할 수 있는 성징을 의미합니다.
- 다양한 데이터 변환에 대해 안정성을 유지하는 것이 목표이며, 모델이 학습해야 될 주요한 특징이 왜곡되거나 변화되게하여 실제 세계에서 만나게 될 다양한 조건에서 변환된 데이터로부터 일반화된 특징을 도출할 수 있도록 하기 위함입니다.
- 대표적인 Inavraince는
1) Translation Invariance (위치 불변성) : 모델이 이미지 내 객체의 위치 변화에 민감하지 않도록 하는 것
2) Rotation Invariance(회전 불변성) : 모델이 이미지나 객체가 회전해도 같은 예측을 하도록 하는
3) Scale Invariance(크기 불변성) : 모델이 객체의 크기 변화에 관계없이 동일하게 인식할 수 있도록 하는 것
4) Temporal Invariance(시간 불변성) : 데이터가 시간에 따라 변화해도 특정 패턴이 존재할 때 모델이 이를 인식하도록 학습하는 것
5) Color Invariance(색상 불변성) : 모델이 색상 변화에도 불구하고 객체를 잘 인식할 수 있게 하는 것
6) Deformation Invariance(변형 불변성) : 이미지나 텍스트가 왜곡되거나 변형되어도 모델이 동일한 출력을 유지하는 것
등이 있습니다.
- 이러한 Invariance에 기반한 Self Supervised Learning 모델들은 다음과 같이 크게 3가지 정도로 구분해볼 수 있습니다.
1) Clustering & pseudo labeling
* 데이터를 K개의 그룹으로 클러스터링 후 해당 클러스터를 클래스로 하는 Pseudo label을 부여
* 해당 Pseudo label을 Self supervised classifier에게 Distillation
2) Consistency regularization
* 유사한 샘플들이 Latent space 상에 더 가까운 위치에 놓이도록 학습
3) Contrastive Learning
* Latent space 상에 유사한 샘플들은 더 가깝게, 다른 샘플들은 더 멀게 놓이도록 학습
2. 다양한 Invariance 기반 SSL 모델들
- Instance Discrimination

* 각 샘플들은 고유한 클래스를 갖는다는 아이디어를 바탕으로, 각각의 샘플(Instance)들이 서로 구분되는 Represnetation을 도출합니다.
* 그리고 이것을 Memory bank에 저장합니다.
* 여기서 Memory bank란 각 데이터 인스턴스에 대한 임베딩을 저장하고 이를 학습과정에서 참조할 수 있게 해주는 저장소의 개념입니다. 작동 방식은, 학습이 진행되는 동안 현재 학습되고 있는 Batch의 인스턴스와 Memory bank에 저장된 임베딩 간에 Contrastive Loss를 계산하며 이를 통해 모델은 학습 데이터의 전체적인 분포와 개별 인스턴스 간의 관계를 지속적으로 학습하게 되는 것입니다.
* 또한 Non parametric Softmax를 활용하는데, 이는 Memory bank에 저장된 인스턴스 임베딩을 파라미터로 정의하지 않고 직접 비교하여 확률을 계산하는 것입니다. 이를 식으로 표현해보면

* 이때 Parametric Softmax는 우리가 일반적으로 Classification에서 사용하는 아래와 같은 식을 의미합니다.
이 방식에서 모델이 각 클래스에 대한 파라미터인 가중치 벡터 w와 편향 b를 학습하게 되는 것입니다.

*Parametric Softmax와 Non parametric Softmax의 차이를 요약해보면 아래와 같습니다. 즉, Non parametric Softmax는 모델로부터 나온 임베딩을 별다른 변형없이 그대로 Memory bank의 임베딩과 dot product 연산들을 하여 이루어지는 softmax인 것입니다.
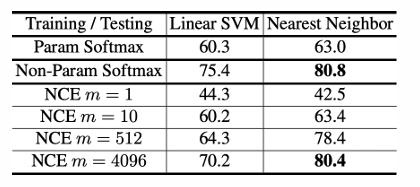
* 그리고 해당 방법론에서는 Parametric Softmax와 NCE(Noise Contrastive Estimation / 다중 분류 문제를 한 세트의 이중 분류 문제로 치환)과의 결과 비교를 해보았고 결과론적으로 Non parametric Softmax의 결과가 가장 좋았다고 하고 있습니다.
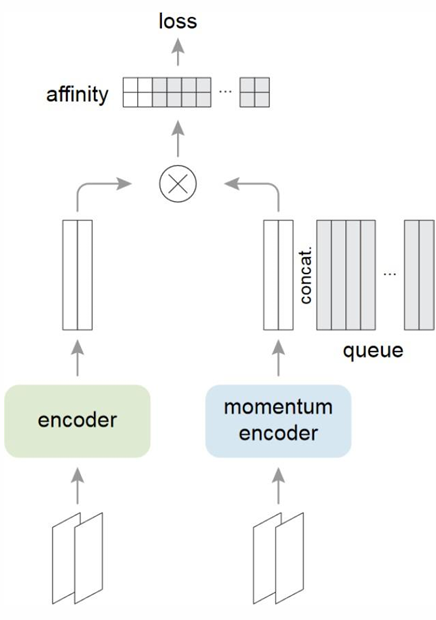
- Momentum Contrast(MoCo)
* Moco는 Contrastive Learning에서 중요한 negative sampels를 효율적으로 관리하고 활용하기 위해 Memory Queue 및 Momentum Encoder를 결합하여 학습하는 방식으로,
Memory Queue와 Momentum Encoder의 업데이트를 활용해 많은 수의 negative samples를 효율적으로 유지하고 이를 contrastive learning에 활용하는 방법입니다.
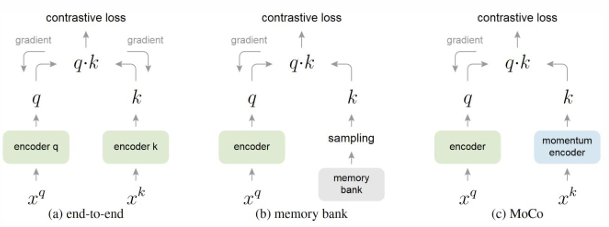
* 아래 그림은 기존에 알아봤던 Memory Bank와 MoCo에서 활용된 Memory Queue의 차이점을 나타내고 있습니다.
Memory bank는 샘플링을 통해서 필요한 negative samples를 뽑아내고 이를 Contrastive Learning에 활용하지만, 메모리 사용량이 매우 크고 학습과정에서 임베딩이 계속 업데이트 되기에 일관된 임베딩을 가지고 학습을 진행했다고 보기 어렵습니다.
하지만, Memory Queue는 고정된 크기의 Queue를 사용해 최근 몇 개의 인스턴스 임베딩만 유지하는 구조로, FIFO 방식(First In, First Out)으로 새로운 인스턴스가 들어오면 가장 오래된 인스턴스가 Queue에서 빠져나가는 방식으로 업데이트가 됩니다.

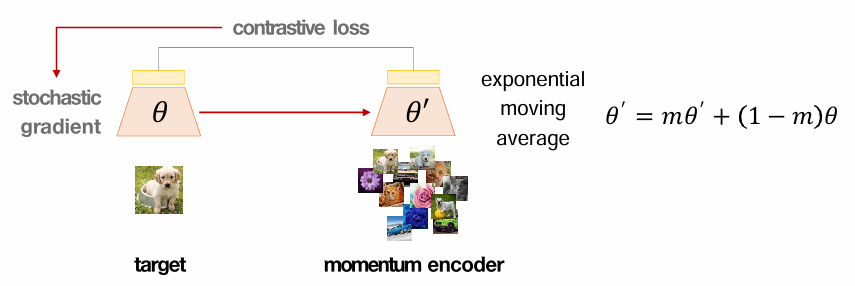
* 다음으로 알아볼건 Momentum Encoder입니다.
아래 그림에서 왼쪽은 target encoder이고, 오른쪽은 momentum encoder입니다. target encoder는 일반적인 encoder라고 보시면 되겠고, momentum encoder는 학습과정에서 파라미터가 모멘텀 방식으로 천천히 업데이트 되는 방식입니다. 기존에 학습된 파라미터와 이번에 새롭게 들어온 파라미터의 비중을 조절해가면서 Queue의 임베딩을 업데이트하는 것입니다.
이를 활용하게 되면, Memory Queue의 임베딩이 천천히 업데이트가 되므로 안정적이고 일관적인 임베딩이 유지된다는 장점이 생기게됩니다. 이때 업데이트 하는 방식은 EMA(Exponential Moving Average) 입니다.
* 이 업데이트 과정을 다른 방식들과 비교해보면, 차이점이 보이게 됩니다.
* 이때 MoCo의 Objective 함수는 아래와 같이 정의할 수 있습니다.

* 이때 Affinity(유사도)는 Query와 Key 임베딩 사이의 값을 의미하며, 그 뒤에 있는 concat 부분은 각 query와 해당하는 positive key, 그리고 queue에 저장된 다양한 negative key들을 하나의 벡터로 이어 붙이는 과정을 의미합니다.

* 이를 바탕으로 실험한 결과는 아래와 같으며
momenum의 경우 0.999 일때가 가장 좋았고
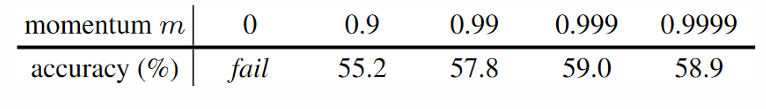
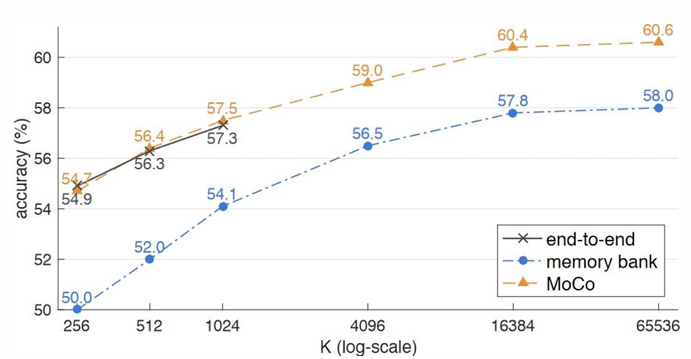
MoCo를 사용했을때가 가장 결과가 좋았습니다.




댓글