
텍스트 데이터를 분석해 추천수와 같은 수치를 예측하는 것은 자연어 처리(NLP)와 회귀 분석이 결합된 분야입니다.
이번 포스팅에서는 지난번에 알아본 TF-IDF를 활용해 청와대 국민청원 데이터셋에서 추천수를 예측하는 방법을 소개하고자 합니다.
1. 프로젝트 목표 및 데이터셋 소개
이번 프로젝트의 목표는 청와대 국민청원 데이터셋 (Korean Petitions) 데이터셋에서 "청원 제목(title)"과 "청원 본문(content)" 텍스트를 분석하여, 추천수를 예측하는 모델을 구현하고자 하는 것입니다.
이를 위해
1) TF-IDF를 활용해 텍스트 데이터를 벡터화하고
[머신러닝 with Python] TF-IDF를 활용한 텍스트 분류
2) 직관적인 해석력을 위해 선형 회귀계열 모델들(Linear Regression, Ridge, LASSO, Elastic Net)을 학습시킵니다.
이때, 최적의 하이퍼 파라미터를 찾기위해 GridSearch CV를 사용하겠습니다.
3) 최종적으로는 Test 데이터 셋에서 R-squared와 MAPE(Mean Absolute Percentage Error)를 활용해 모델의 성능을 평가하고자 합니다.
활용하고자 하는 데이터셋인 청와대 국민청원 데이터 셋은
2017년 8월부터 2019년 3월까지의 데이터를 모은 것이며 데이터의 구조는 아래와 같습니다.
https://ko-nlp.github.io/Korpora/ko-docs/corpuslist/korean_petitions.html
청와대 국민청원 · Korpora
청와대 국민청원 청와대 국민청원 데이터는 lovit@github 님이 공개한 청와대 국민청원 데이터(2017.08 ~ 2019.03)입니다. 데이터 정보는 다음과 같습니다. author: lovit@github repository: https://github.co...
ko-nlp.github.io
2. 파이썬을 활용한 분석
먼저 활용할 라이브러리를 불러와줍니다. (필요시 pip install Korpora 를 통해서 Korpora 라이브러리를 설치해서 데이터를 불러와줍니다)
from Korpora import Korpora
import pandas as pd
import pandas as pd
import numpy as np
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.pipeline import make_pipeline
from sklearn.metrics import r2_score, mean_absolute_percentage_error
이후 데이터를 로드해줍니다.
# 데이터 로드
korpus = Korpora.load("korean_petitions")
# 데이터 추출
titles = korpus.get_all_titles() # 청원 제목
contents = korpus.get_all_texts() # 청원 본문
recommendations = korpus.get_all_num_agrees() # 추천 수
# 데이터프레임 생성
df = pd.DataFrame({'title': titles, 'content': contents, 'recommendation_count': recommendations})
# 데이터 확인
print("데이터프레임 예시:")
df.head()
데이터수가 많은 관계로 1/10 데이터만을 바탕으로 실험을 진행하겠습니다.
# 데이터의 1/10 (10%) 샘플링
df = df.sample(frac=1/10, random_state=42) # 10% 샘플링
df.info()
이제 데이터를 전처리해줍니다.
HTML 제거, 특수문자 및 숫자제거, 지나치게 긴 단어 제거, 불용어를 제거해줍니다.
# 확장된 불용어 리스트
stop_words = [
"이", "그", "저", "것", "수", "등", "을", "를", "은", "는", "의", "에", "으로",
"그리고", "하지만", "또는", "안", "못", "그냥", "너무", "더", "뭐", "왜", "또",
"때문에", "중", "에서", "라고", "보다", "때", "처럼", "같이", "모든", "많은",
"다른", "어떤", "이런", "저런", "그런", "합니다", "하고", "그리고", "그렇지만",
"하지만", "또한", "따라서", "그러므로", "즉"
]
# 전처리 함수 정의
def preprocess_text(text):
# HTML 태그 제거
text = re.sub(r"<[^>]*>", "", text)
# 특수문자 및 숫자 제거
text = re.sub(r"[^ㄱ-ㅎ가-힣a-zA-Z\s]", "", text)
# 지나치게 긴 단어 제거 (20자 이상)
text = " ".join([word for word in text.split() if len(word) < 20])
# 불용어 제거
words = text.split()
words = [word for word in words if word not in stop_words]
return " ".join(words)
# 전처리 적용
df['processed_content'] = df['content'].apply(preprocess_text) # 본문 전처리
df['processed_title'] = df['title'].apply(preprocess_text) # 제목 전처리
# 전처리 결과 확인
print("전처리된 데이터프레임:")
df[['processed_title', 'processed_content', 'recommendation_count']].head()

이제 title과 content를 병합해서 데이터셋을 만들고 train 과 test로 구분한 뒤 tfidf_vectorize를 진행해줍니다.
# 병합된 텍스트 생성
df['processed_text'] = df['processed_title'] + " " + df['processed_content']
# 2. 데이터 분리
X = df['processed_text']
y = df['recommendation_count']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# TF-IDF 벡터화 (최소/최대 빈도 설정)
tfidf = TfidfVectorizer(
max_features=1000, # 최대 5000개 단어
min_df=5, # 최소 5번 이상 등장한 단어만 포함
max_df=0.9 # 90% 이상의 문서에서 등장한 단어 제외
)
X_tfidf = tfidf.fit_transform(df['processed_text'])
# Train-Test Split
X_train_tfidf, X_test_tfidf, y_train, y_test = train_test_split(
X_tfidf, df['recommendation_count'], test_size=0.3, random_state=42
)
이제 train 데이터를 활용해 매핑된 tf-idf 맵을 확인해보겠습니다.
# TF-IDF 단어 목록 가져오기
tfidf_vocab = tfidf.get_feature_names_out()
# TF-IDF 벡터를 DataFrame으로 변환
X_train_tfidf_df = pd.DataFrame(X_train_tfidf.toarray(), columns=tfidf_vocab)
# TF-IDF 매핑 확인
print("TF-IDF 매핑 (일부):")
X_train_tfidf_df.head()
이때 매핑된 TF-IDF 중 평균 스코어가 높은 단어를 확인해보면 아래와 같습니다.
tfidf_mean = X_train_tfidf_df.mean().sort_values(ascending=False)
print("TF-IDF 평균 상위 10개 단어:")
print(tfidf_mean.head(10))

이제 Linear Regression, Ridge, LASSO, Elastic Net으로 모델을 학습 후 TEST 하겠습니다. Linear Regression을 제외하고는 GridSerach CV를 진행하겠습니다.
# 모델 정의 및 하이퍼파라미터 그리드 설정
models = {
"LinearRegression": LinearRegression(),
"Ridge": Ridge(),
"Lasso": Lasso(),
"ElasticNet": ElasticNet()
}
param_grids = {
"Ridge": {"alpha": [0.1, 1.0, 10.0]},
"Lasso": {"alpha": [0.1, 0.5, 1.0]},
"ElasticNet": {"alpha": [0.1, 0.5, 1.0], "l1_ratio": [0.2, 0.5, 0.8]}
}
# 모델 학습 및 그리드 서치
best_models = {}
for name, model in models.items():
if name in param_grids:
grid = GridSearchCV(model, param_grids[name], scoring="r2", cv=3)
grid.fit(X_train_tfidf, y_train) # TF-IDF 벡터화된 데이터를 사용
best_models[name] = grid.best_estimator_
else:
model.fit(X_train_tfidf, y_train)
best_models[name] = model
# 테스트 데이터 평가
results = []
for name, model in best_models.items():
y_pred = model.predict(X_test_tfidf) # TF-IDF 벡터화된 테스트 데이터
r2 = r2_score(y_test, y_pred)
mape = mean_absolute_percentage_error(y_test, y_pred)
results.append({"Model": name, "R-squared": r2, "MAPE": mape})
# 결과 출력
results_df = pd.DataFrame(results)
print("모델 성능 평가 결과:")
print(results_df)
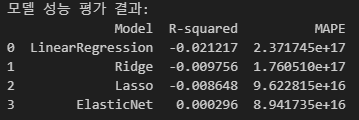
모델의 성능은 다음과 같습니다.
사실상 ElasticNet을 제외하면 평균치로 예측하는 것보다 못한 수준이고, ElasticNet도 그렇게 잘 학습이 되지 않았습니다.
보다 고차원의 Mapping과 비선형적인 관계로 Regression하는 모델이 필요할 것 같습니다.





댓글