
이번에는 실제 자료를 바탕으로 PDF Plumber의 활용성을 알아보겠습니다.
1. 실습 간 활용할 데이터 : 24년 네이버 반기 보고서
이번에 사용할 자료는 네이버의 2024년 반기 사업보고서 입니다.
https://kind.krx.co.kr/common/disclsviewer.do?method=search&acptno=20240318001166
[NAVER] 사업보고서(일반법인)
본 문서는 최종문서가 아니므로, 최종 정정문서를 반드시 확인하시기 바랍니다.
kind.krx.co.kr
공개된 자료입니다.
위 데이터는 총 442페이지이며 수백개의 표로 구성되어있는 자료 입니다.
2. PDF Plumber를 통해서 표 추출하기
표 추출을 위해서 코랩에서 PDF Plumber를 활용해 보았습니다.
[업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (2) (표 추출)
[업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (2) (표 추출)
지난 시간에는 PDFPlumber를 활용해서 pdf 파일 내의 이미지에 대해서 추출해보았는데요. 이번에는 pdf파일내의 표(Table)을 추출해보도록 하겠습니다 PDFPlumber에 대한 전반적인 내용은 지난 포스팅
jaylala.tistory.com
먼저 코랩을 열어준 뒤 라이브러리를 설치해줍니다.
이후
구글 드라이브에 업로드 된 pdf 파일의 경로를 입력해주고, 출력할 폴더를 입력해준 뒤 PDF를 읽어주면 되겠습니다.
아래와 같이 코드를 실행시키면 되겠으며, PDF에서 각 페이지별로 표를 추출한 뒤 파일은 csv 형태로 저장해주며, 몇 페이지의 몇번째 테이블(표)인지를 이름으로 구분하기 쉽게 지정해놓았습니다.
사용한 기능은 extract_tables 입니다.
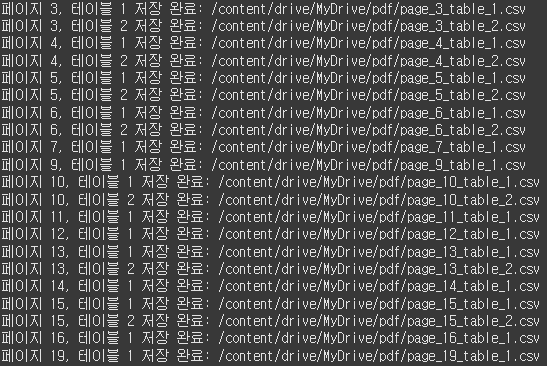
3페이지부터 표가 식별되어, 식별된 표들을 잘 저장해주었음을 확인할 수 있습니다.
(엑셀에서 작업이 필요하다면, csv가 아닌 .xlsx의 형태로 저장해주면 한글이 깨지지않고 잘 저장되고 엑셀이 잘 실행됩니다)
그렇다면, 실제로 저장된 파일과 원본을 비교해보겠습니다.
먼저 pdf상에서 3페이지의 첫번째 표입니다.

그리고 이를 인식해서 pdfplumber가 추출한 표입니다.
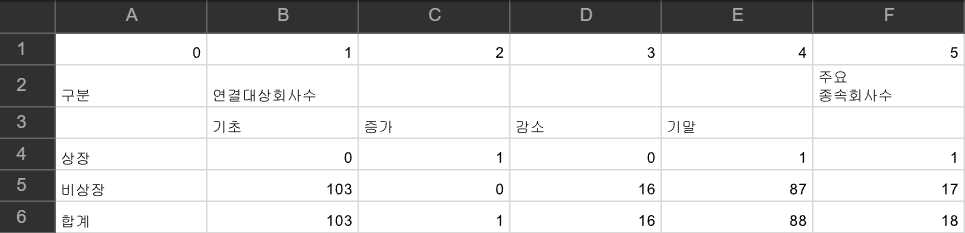
병합(Merging) 해야 될 셀들이 보이긴 하지만, 꽤나 정확하게 잘 추출한 것을 알 수 있습니다.
다음은 pdf상에서 3페이지의 두번째 표입니다.

그리고 다음은 pdf plumber를 통해 추출된 표입니다.
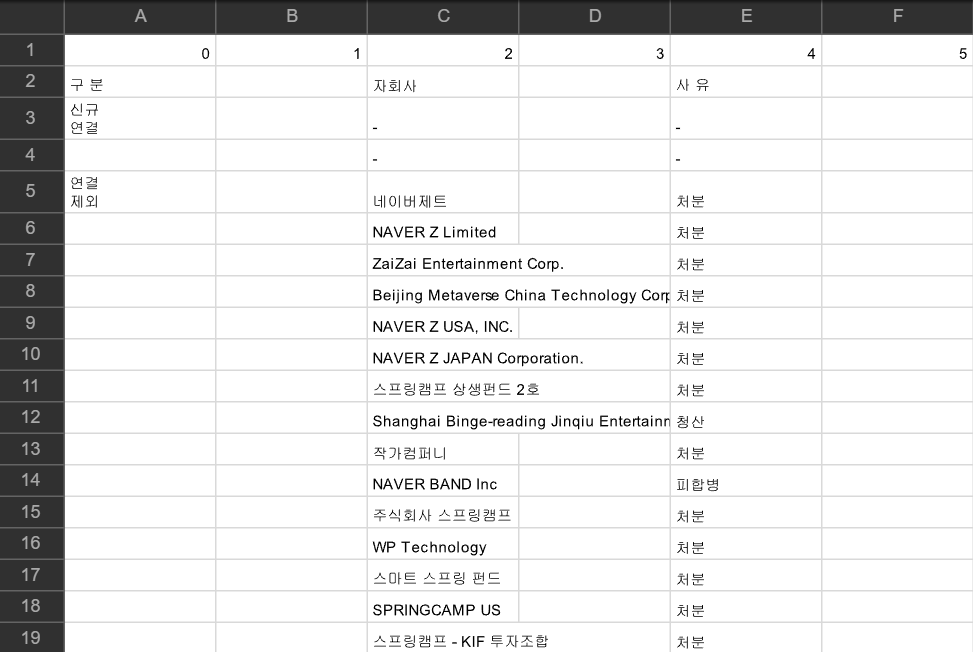
보시는 것처럼 표의 전반적인 내용들이 오류없이 잘 추출된 것을 알 수 있습니다. 물론, 엑셀에서 작업시에는 merging해야되는 부분이 있겠지만, 굳이 시각적으로 보여줄 필요가 없다면 잘 처리가 되었으며 인덱싱 처리만 하면 훌륭하게 잘 활용할 수 있음을 알 수 있습니다.
'업무자동화 with Python' 카테고리의 다른 글
| [업무자동화 with Python] 파이썬을 활용한 엑셀 자동화 (1) : 데이터 생성 + 필터링 + 보고서 생성 (0) | 2025.03.01 |
|---|---|
| [업무자동화 with Python] EasyOCR을 활용한 OCR해보기 (0) | 2025.03.01 |
| [업무자동화 with Python] Pytesseract를 활용한 OCR (Optical Character Recognition) (6) | 2024.11.06 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (4) (표 추출) (1) | 2024.10.22 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (3) (표 추출) (0) | 2024.10.21 |




댓글