
GraphSAGE(Graph Sample and aggreGatE)는 "Inductive Representation Learning on Large Graphs"(NIPS 17)라는 논문에 소개된 모델로, GNN의 한 종류이며, 대규모 그래프 데이터에서 효율적으로 노드의 임베딩을 학습하기 위해 설계된 방법입니다.
특히, GraphSAGE는 이웃 노드의 정보를 샘플링(Sample)하고 집계(Aggregate)하는 방식을 통해 그래프에서 노드의 표현을 학습하고, 이를 통해 매우 큰 데이터의 그래프에서 메모리와 계산 자원을 절약하며 학습할 수 있게 해주는 방식입니다.
Graph SAGE의 주요 개념과 특징에 대해서 간략히 알아보겠습니다.
1. GraphSAGE의 주요 개념과 특징
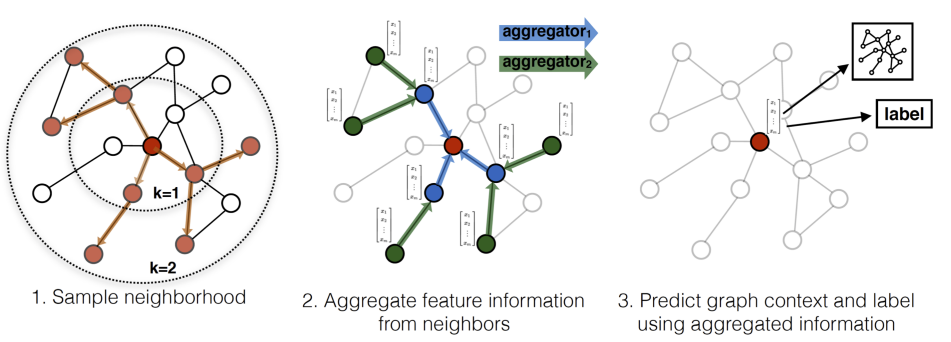
1) Sample neighborhood
대규모의 그래프에서 모든 이웃 노드 정보를 사용하는 것은 굉장히 비효율적일 수 있습니다. 예를 들어, 소셜 네트워크 그래프에서 수천명 이상의 친구들과 관계를 가지는 사용자들이 많이 있을텐데, 그래프 학습을 위해 이들 모두와의 관계를 계산하는 것은 과도한 연산량을 요구하게 됩니다.
이를 해결하기 위해 GraphSAGE는, 특정 노드의 Feature를 업데이트 하기위해 사용되는 이웃 노드를 무작위로 샘플링하는 방법을 활용합니다. 즉, 각 노드들의 Feature 정보를 업데이트 할 때 이웃 노드 들 중 일부만을 무작위로 샘플링하여 선택하고 이를 학습에 활용하는 것입니다.
2) Aggregate feature information form neighbors
이렇게 샘플링 된 이웃들(Neighbors)의 정보를 받아서 집계(Aggregate) 하게 됩니다.
이때, Aggregate 하는 방식은 다양한 방법들이 있으며 대표적으로
a) Mean Aggregation / b) LSTM Aggregation / c) Pooling Aggregation 을 활용하고 있습니다.
a) Mean Aggregation : 이웃 노드들의 feature 정보의 평균을 계산하는 겁니다. 이를 수식으로 표현하면 아래와 같습니다.

b) LSTM Aggregation : 샘플링 된 이웃들의 정보를 순차적으로 결합하기 위해 LSTM을 활용합니다. 이는 이웃들의 순서 정보(Sequential information)까지를 반영하며 학습 가능한 선형적인 조합이기에, 보다 복잡한 관계에 대해서도 잘학습할 수 있습니다.
[딥러닝 with Python] LSTM (Long Short Term Memory)
[딥러닝 with Python] LSTM (Long Short Term Memory)
[본 포스팅은 "만들면서 배우는 생성 AI 2판"을 참조로 작성했습니다] 이번에 알아볼 모형은 자기회귀 모델의 대표적인 모형인 LSTM입니다. LSTM은 Long Short Term Memory의 줄임말로 기존의 순환 신경
jaylala.tistory.com
c) Pooling Aggregation : 각 이웃 노드의 임베딩을 pooling 기반의 비선형 함수(max-pooling, mean-pooling 등)으로 변환하여 Aggregate합니다.
3) Predict graph context and label using aggregated information
위와 같은 방법으로 주변 노드들로부터 받은 정보를 Aggregate 한 뒤, 해당 노드의 정보를 업데이트 하게 됩니다.
각 노드들에 대한 원본 정보들은 Pre-processing 과정(학습 중인 노드라면 학습 과정 중 비선형 결합 등 포함)을 거쳐 의미있는 차원의 수치정보들로 변하게 되는데요. 이렇게 표현된 수치들을 임베딩 벡터라고 합니다.
우리가 업데이트하고자하는 노드의 정보도 임베딩되어있을 것이고, 앞선 과정을 통해 이웃 노드들의 임베딩 벡터의 정보들을 Aggregate하여 해당 노드의 정보를 업데이트 하는 과정은 아래 수식으로 표현할 수 있습니다.
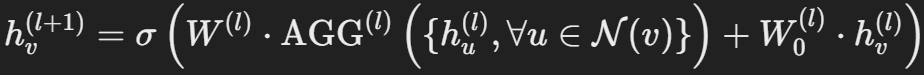

즉, 기존의 노드 정보에 학습 가능한 가중치 W0를 곱하고, 샘플링된 이웃 노드들의 정보가 Aggregate 된 것에 학습 가능한 가중치 Wl을 곱해서 더한 뒤 비선형 활성화 함수에 넣어 도출된 값을 새로운 노드의 값으로 반영하는 것입니다.
이와 같은 방식을 통해 Graph Representation을 구하여 다양한 Down stream task에 활용할 수 있는 것입니다.
2. GraphSage 장점 과 한계
GCN의 한계를 극복하기 위해 새롭게 제안된 GraphSAGE는 여러가지의 장점이 있지만 역시나 한계 또한 존재합니다.
[개념정리] Graph Convolutional Network란? GCN이란?
[개념정리] Graph Convolutional Network란? GCN이란?
[해당 포스팅은 "[기초개념] Graph Convolutional Network(GCN)"(GIST 발표자료) 를 참조했습니다. 링크: https://www.slideshare.net/slideshow/graph-convolutional-network-gcn/144158888#6 ]1. 그래프 기본개념 - 그래프는 일반적
jaylala.tistory.com
1) 장점
- 대규모 그래프를 처리 가능 : 이웃 샘플링르 통해 모든 이웃 정보를 사용하지 않고도 빠르고 효율적이게 그래프를 처리할 수 있습니다.
- 유연한 집계(Aggregate) 방법 : 다양한 집계 방법(Mean, LSTM, Pooling 등)을 사용해 그래프의 구조적 특성에 맞게 임베딩을 학습할 수 있습니다.
- 인덕티브(Inductive) 학습: 학습되지 않은 새로운 노드나 서브그래프에 대해 추론할 수 있는 학습 방식으로, 확장성 있는 모델을 의미합니다. 여기서 Inductive란 "귀납적인"이라는 뜻으로, 기존에 학습된 여러 사례들을 바탕으로 새롭게 등장하는 데이터에 대해 추론하는 방식을 의미합니다. 즉, 새롭게 노드가 추가되더라도, 해당 노드의 주변 노드 정보를 기반으로 연결성을 추론할 수 있기 때문에, 별도의 추가 학습 없이도 합리적인 노드 표현을 만들어낼 수 있다는 장점을 갖습니다.
- 메모리 효율성 : 대규모 그래프에서도 부분적인 샘플링을 통해 메모리와 계산 자원을 효율적으로 사용할 수 있습니다.
2) 단점
- 이웃 샘플링의 불확실성 : 이웃 노드를 무작위로 샘플링하기때문에 샘플링 과정에서 중요한 정보를 놓칠 수도 있습니다.
- 정확성 저하 : 전체 이웃을 사용하지 않기 때문에 작은 그래프에서는 GCN보다 성능이 떨어질수 도 있습니다.
'딥러닝 with Python' 카테고리의 다른 글
| [개념정리] ROCKET(RandOm Convolutional KErnel Transform) (시계열 특징 추출 / 시계열 분류) (1/2) (0) | 2024.10.13 |
|---|---|
| [개념정리] SiLU(Sigmoid Linear Unit) 활성화 함수 (1) | 2024.10.12 |
| [개념정리] Graph Convolutional Network란? GCN이란? (12) | 2024.09.28 |
| [개념정리] 그래프 신경망(Graph Neural Network / GNN) (3) (0) | 2024.08.02 |
| [개념정리] 그래프 신경망(Graph Neural Network / GNN) (2) (0) | 2024.08.01 |




댓글