
이번에 알아보 내용은 Vision Transformer입니다.
해당 모델은 "An Image is worth 16x16 words: Transformers for image recognition at scale" 이라는 논문에서 등장했습니다. 해당 논문은 2021년 ICLR에서 발표된 이후, 많은 후속 연구들이 쏟아지고 있으며 ViT를 Backbone으로 한 다양한 Architecture들이 나오면서 CV(Computer Vision) Task에서 CNN을 대체 또는 다른 방향성을 제시하는 솔루션으로 제안되고 있습니다.
1. Vision Transformer(ViT / 비전트랜스포머)
-기본적인 구조는 아래에 나와있는 모습을 바탕으로 알 수 있습니다.
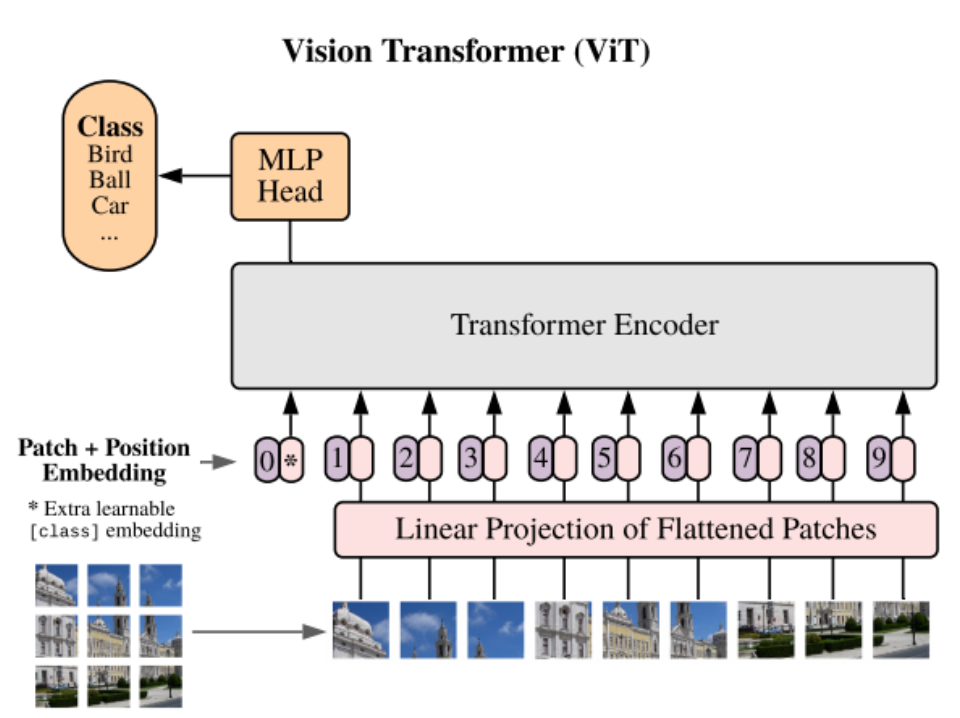
1) Image Patching (이미지 패치화)
- 처리 과정 : 입력 이미지가 머저 작은 패치들로 분할됩니다. 이 패치들은 일반적으로 모두 같은 크기를 가지며, 이미지는 위 그림 좌측에 나온 것 처럼 grid(격자) 패턴으로 나누어지게 됩니다.
ex. 224 x 224 픽셀의 이미지가 가로 14 / 세로 14 개의 격자로 나누어지게 된다면, 한 패치의 크기는 16x16의 크기를 갖게 됩니다.
- 목적 : Transformer는 시퀀스 데이터를 처리하는데 최적화되어있으므로, 이미지를 시퀀스처럼 처리할 수 있는 작은 단위로 변환하는 것입니다.
2) Patch Embedding (패치 임베딩)
- 처리 과정
a) Flatten Patches : n x n 형태의 각 패치는 n^2 x 1 의 형태처럼 한 개의 열로 펼쳐지게 됩니다.
* 예를들어, 패치의 크기가 16x 16이라면, 이는 Flatten Patches에 의해 256x1로 변환되게 됩니다.
b) Linear Projection(Low dimensional Projection) : Flatten 된 패치들은 1열의 형태를 가지게 되고, 이를 Linear Projection(선형 투영)하게 됩니다. 선형 투영 과정은 아래와 같이 데이터의 표현하는데 있어서 차원을 축소하기 위한 방법입니다. 이를 통해 원본 데이터의 의미는 최대한 보존하되 계산 비용(Computational Cost)를 줄일 수 있는 것입니다.
* 예를들어, 256x1로 flatten된 패치가 Input이고 Output이 512개의 노드를 가진 Linear projection이라면, 선형 변환(weight가 곱해지고, bias가 더해지는)을 거쳐 512개의 결과값으로 전환되게 됩니다.
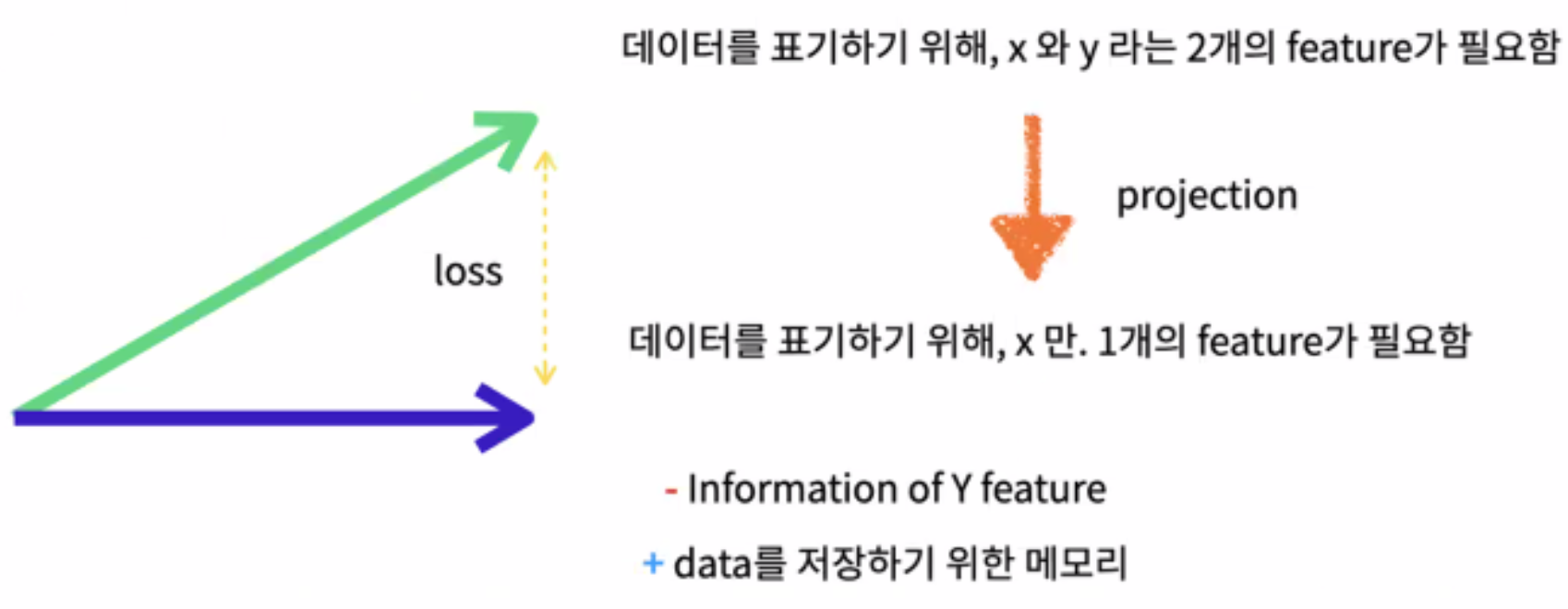
c) 위 과정은 패치의 원래 픽셀값을 모델이 이해할 수 있는 형식의 데이터로 Mapping 하는데 있습니다.
-목적 : 패치의 픽셀값을 고차원 공간에서의 포인트로 변환하여, 패치 간의 복잡한 관계와 패턴을 모델이 더 잘 학습하 수 있도록 해줍니디다.
3) 포지셔널 인코딩 (Positional Encoding) 추가
- 처리과정 : Transformer는 입력 시퀀스의 순서 정보를 내재적으로 이해하지 못하고 있기 때문에 각 패치 임베딩에 순서 정보인 Positional information을 인코딩 해주는 과정을 추가해줍니다. 이 인코딩은 각 패치의 위치 정보를 담고 있으며, 임베딩 벡터에 직접 더해지게 됩니다.

* 이때, trainable (학습 가능한) 포지셔널 인코딩이 패치에 더해짐으로써 추가됩니다.
* 포지셔널 인코딩 벡터는 다양하게 존재하나, 해당 논문에서 제안된 방법은 Sine(사인) 및 Cosine(코사인) 함수를 이용한 방식입니다.


*여기서 말하는 모델의 임베딩 차원의 크기는, 위에서 진행된 linear projection에서 결과값으로 output node의 개수를 의미합니다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 개념 정리] Inference? 딥러닝에서 Inference란? (0) | 2024.02.18 |
|---|---|
| [개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2) (1) | 2024.02.17 |
| [개념정리] Layer Normalization (0) | 2024.02.15 |
| [개념정리] 멀티헤드 셀프 어텐션(Multi-Head Self-Attention) (0) | 2024.02.14 |
| [개념정리] Self attention / 셀프 어텐션 (0) | 2024.02.13 |




댓글