
이번에 알아볼 개념은 멀티 헤드 셀프 어텐션(Multi-Head Self Attnetion) 입니다.
[개념정리] Self attention / 셀프 어텐션
지난번에 알아봤던, 셀프 어텐션이 조금은 차이나는 방식으로 여러번 적용되었다고 보시면 되겠습니다.
1. 멀티헤드 셀프 어텐션(Multi-Head Self Attention)
- 입력 시퀀스의 각 요소가 시퀀스 내 다른 요소들과 어떻게 관련되어 있는지를 알아보는 Self Attention을, 동시에 다양한 방식으로 모델링하는 방법을 말합니다.
- 즉, 여러개의 헤드(Head)로 분할하여 병렬로 Self Attention을 수행하는데요
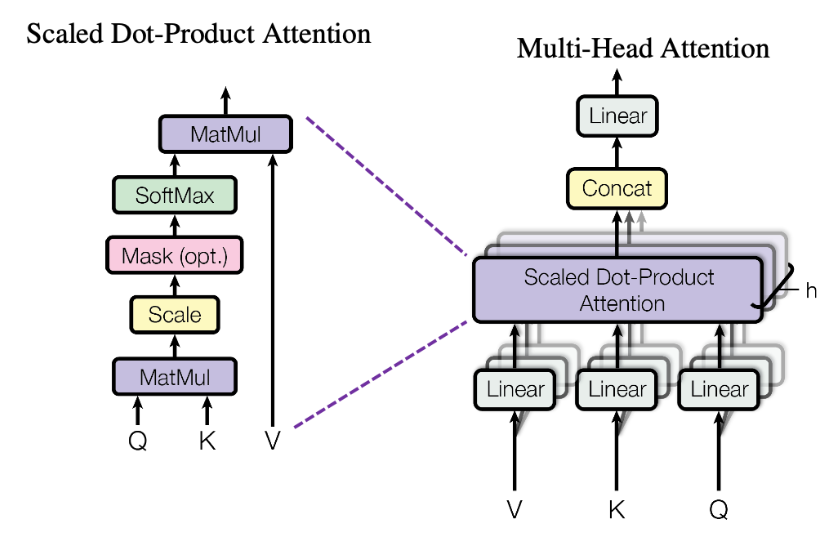
- 이렇게 병렬로 mult-hea를 사용하는 이유는, 여러 부분에 동시에 어텐션을 가할 수 있어 모델이 입력 토큰 간의 다양한 유형의 종속성을 포착하고 동시에 모델이 다양한 소스의 정보를 결합할 수 있게되기 때문입니다.
- 아래 예시를 통해 확인해 볼 수 있는데요.
[출처 : https://www.blossominkyung.com/deeplearning/transformer-mha#bc014d12-588a-420f-9d44-d453f6e5b998]
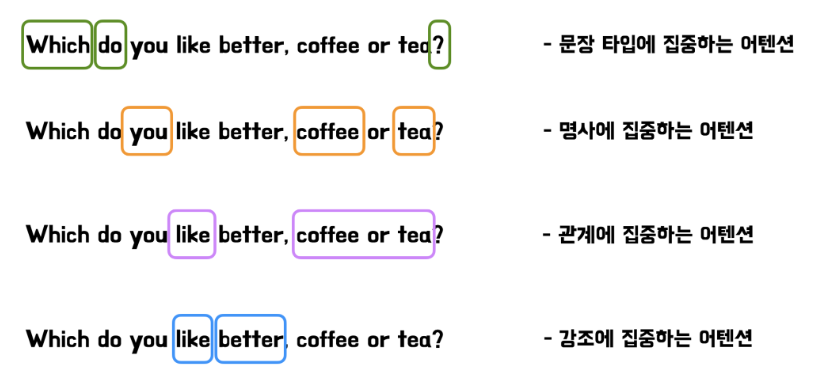
위 그림과 같이 한 head가 집중하는 부분이 다를 수 있고, 같은 문장 내 여러 관계 또는 다양한 소스 정보를 나타내는 정보들에 집중하는 어텐션을 줄 수도 있기 때문입니다.
즉, 입력 토큰 간의 더 복잡한 관계를 다룰 수 있어 다양한 유형의 종속성을 포착할 수 있으며, 표현력 또한 향상 될 수 있기 때문입니다.
- 계산과 관련해서는
일반적인 어텐션은 아래의 예시처럼, 4x4 크기의 문장 임베딩 벡터와 4x8 크기의 Q, K, V가 있을때, 이 과정을 통해서 도출되는 Attention value는 Value의 차원인 4x8과 동일하게 도출됩니다.

멀티 헤드 어텐션의 경우, 결과물이 동일하게 나오게 해기 위해 4x(8/h) 차원이 되도록 합니다.
( h= 헤드의 개수)
예를 들어 아래 예시처럼
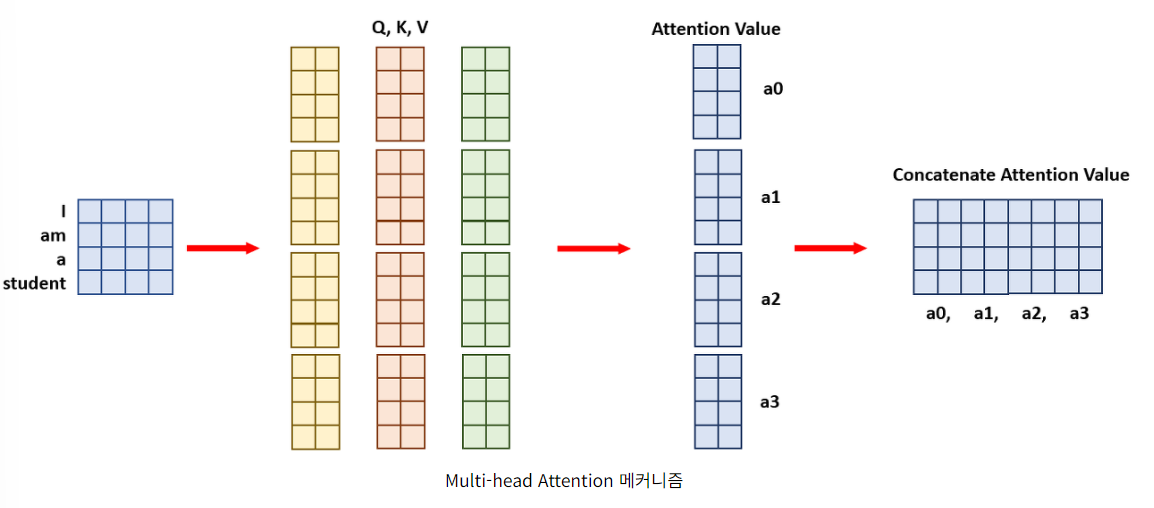
Q, K, V의 차원 4x8인 경우, 4개의 헤드를 사용할 때(h=4) Q,K,V는 4x2의 차원을 가지게 되고, Value의 차원은 각 헤드 별로 4x2이지만 전체 Attention value들을 Concate 하기때문에 총 4x8 차원이 유지되는 것입니다.
'딥러닝 with Python' 카테고리의 다른 글
| [개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2) (1) | 2024.02.16 |
|---|---|
| [개념정리] Layer Normalization (0) | 2024.02.15 |
| [개념정리] Self attention / 셀프 어텐션 (0) | 2024.02.13 |
| [개념정리] 어텐션(Attention)이란 (1) | 2024.02.12 |
| [논문리뷰] DeepLabV3+ / 이미지 분할(Image Segmentation) (1) | 2024.02.10 |




댓글