
이번에는 지난 시간에 알아본 컴퓨터 비전 방법 중 객체 검출(Object Detection)에 대해서 조금 더 자세히 알아보겠습니다.
[딥러닝 with 파이썬] 컴퓨터 비전에서의 이미지 분류(Image Classification), 객체 검출(Object Detection),
컴퓨터 비전(Computer Vision)이란, 기계가 이미지를 이해하고 해석하는 능력을 개발하는 분야입니다. 해당 분야에서는 3가지의 주요 방법론이 있는데요. 이는 이미지 분류(Classification), 객체 검출(Obj
jaylala.tistory.com
1. 일반적인 객체 검출의 과정 논리 구조
- 일반적인 객체 검출의 과정은 아래와 같은 로직을 따르며, 아래는 이를 기초로 설명을 드리겠습니다.
General process of object detection (general flow of object detection)

2. 객체 검출 과정
2-1. Specify Object Model(어떤 Object를 뽑을지에 대해 정하고, 이를 DB화)
- Object Detection의 첫 번째 단계는, 어떠한 Object를 Detection 할지 정의하고 그에 대한 feature를 정의하는 단계를 말합니다.
- 현재 Neural Network를 기반으로 한 모델들은, 모델 자체적으로 feature를 정해주지 않기 때문에 이와 같은 과정이 생략되기도 합니다.
- 하지만, 기존에 있었던 아래와 같은 방법들을 domain knowledge로 하여 learning-based detection에서 이용하려는 움직임이 있음
1) Statistical Template in Bounding Box
- 이 방법에서 object는 이미지 어딘가에 존재하고, feature는 bounding box의 coordinate에 대해 정의 됨
- 좋은 feature란?
a) 같은 object라면 비슷한 feature가 뽑혀야 함
b) 같은 object라면 주변의 환경에 구애받지않고 꾸준히 비슷하게 뽑혀야 함
c) flat이나 edge 같은 영역이 아닌, corner 같은 주변과 차별화되는 부분을 뽑아야 함
d) feature에 상응하는 descriptor를 달 수 있어야 함
(descriptor : 하나의 entity에 대한 정보를 명시하는 것)

* 위 이미지에서는 edge 밝기 변화가 일어나는 것에 따라 강력한 edge 방향들만 뽑아서 feature로 사용. 또한, feature 스스로를 descripotr로 이용. 이러면 같은 이미지를 보여줬을 때, 환경이 달라져도 비슷한 feature를 뽑아낼 수 있음.
2) Articulated parts (Articulated : 분절된)

* 사람의 얼굴이나 기계 같은 경우 정형화된 구조가 있음. 이런 경우 Object는 부분 요소들의 configuration이 됨 (configuration : 구성)
* 이러한 경우 이렇게 특징이 되는 구조들을 feature로 이용할 수 있음. (현재는 detection 보다는 pose estimation 또는 graphics 쪽에서 애니메이션을 위해 많이 사용됨)
3) Hybrid Template & body

* 앞서 설명한 방법과 deformation model이라는 모델을 합쳐서 자전거를 탐지
2-2. Generate Hypothesis
(1번에서 정의된 Object DB를 바탕으로, 이미지에서 Object의 후보군을 뽑고 Scoring하는 작업)
1) Sliding Window
- Scale을 고려해, 모든 pixel location에 대해 일정 크기의 patch만큼 돌아다니면서 검사

* 이미지에서 object를 탐색해내기 위해선, bouding box의 scale을 고정하고 이미지의 크기를 늘이거나 줄이는 방법을 활용하고 있음
ex) 128x128 크기의 이미지에 고정된 sclae을 가진 A라는 window를 적용하는 경우보다, 해당 이미지를 64x64로 줄인뒤 동일한 A라는 window를 사용하는 경우 더 큰 범위에서 Object를 탐색할 수 있음
-> (Window Scale이 고정된 상태에서) 이미지의 크기를 키우면 상대적으로 window크기가 작아지기 때문에 더 작은 크기의 Object를 탐색할 수 있음. 반대로, 이미지의 크기를 줄이면 보다 큰 크기의 Object를 탐색할 수 있음
-> 이 과정을 통해 DB에 가지고 있는 feature와 비슷한 사이즈로 candidate를 만들 수 있음

* 하지만, 이러한 방법을 활용할 경우 이미지를 늘렸을 때 overhead가 발생할 수 있음
(overhead : 처리 시간 및 메모리등이 추가적으로 사용됨을 의미)
-> 대신, patch의 사이즈를 줄이는 방법을 사용함
+ objectness를 추정할 수 있는 방법들이 있어서 이 영역만 가지고 candidate를 만들 수 있는 방법이 있음
2-3. Score Hypothesis
- Classifer를 이용해 진행
- learning-based object detecor라면, 위에서 도출한 각 patch마다 classifier를 이용해 object별 점수를 얻고, 이를 통해 분류 (고전 모델들은 SVM을 이용했었으나 현재는 다름)
2-4. Resolve Score
- Non-max Suppression
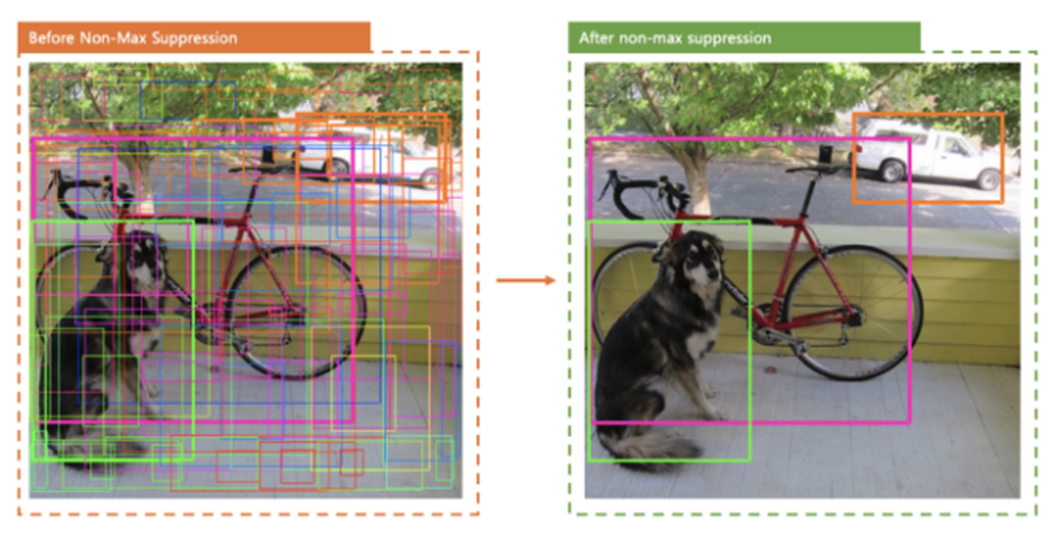
* sliding window를 통해 각 patch별로 scoring을 하면, 특정 이미지의 주변 patch들이 전부 높은 score를 갖게 됨. 이 중 가장 좋은 patch를 뽑기 위한 방법이 NMS(Non Max suppression)임
* NMS는, 특정 object 주변에 존재하는 bounding box 들을 score를 기준으로 sorting한 뒤 가장 점수가 높은 것 한 개만 남기고 나머지는 제거
* 이는 opimal한 solution이라 보기는 어려우며, Local Maximum을 찾아야 함
[이번 포스팅은 아래 블로그 내용을 참조하였습니다]
https://wikidocs.net/book/6651
한땀한땀 딥러닝 컴퓨터 비전 백과사전
[가짜연구소](https://pseudo-lab.com/) 스터디 활동으로 모인 스터디 러너분들이 **딥러닝 컴퓨터 비전에 쓰이는 기초적인 개념와 배경지식**을 정리한 백과…
wikidocs.net
'딥러닝 with Python' 카테고리의 다른 글
| Normalization / Batch Normalization / Layer Normalization (1) | 2024.01.27 |
|---|---|
| [딥러닝 with 파이썬] 분류(Classification)란? 사례 분류(Instance Classification) / 범주 분류(Categorical Classification) (2) | 2023.12.03 |
| [딥러닝 with 파이썬] 크로스 엔트로피(Cross Entropy) (0) | 2023.11.03 |
| [딥러닝 with 파이썬] (논문 리뷰)SegNet이란? (1) | 2023.11.01 |
| [딥러닝 with 파이썬] (논문리뷰) FCN이란? Fully Convolutional Network (이미지 분할 / Image Segmentation) (0) | 2023.10.31 |




댓글