
이번에 알아볼 신경망은 잔차 신경망, Residual Net(RESNET) 입니다.
잔차 신경망은 2015년에 처음 등장한 신경망으로, 복잡한 신경망 작업을 원활하게 만들었고 정확도 또한 높게 달성할 수 있었기에 기여점이 큰 신경망인데요
Residual Net에 대해서 한번 알아보겠습니다.
1. 잔차신경망, Residual Net(ResNet)이란 ?
1) 잔차신경망, ResNet(Residual Net)은 2015년 12월에 발표된 논문 "Deep Residual Learning for Image Recognition"에서 등장한 CNN 기반의 신경망 모델입니다.
https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
- ResNet은 잔차(Residual) 연결을 통해 최대한 유지하면서 잔차를 학습하는 방식을 사용하는 망입니다.
* 여기서 Residual, 잔차는, 입력과 출력의 차이를 의미합니다.
* 잔차 신경망에서 잔차는 입력과 출력의 차이를 나타내므로, 잔차가 작을수록 입력과 출력의 차이가 적다는 것을 의미하며, 해당 신경망이 입력 데이터를 잘 이해하고 있다는 것을 의미합니다.
- 이때 의문점이 드는데요. 기존에 정의되었던 잔차는 실제 y값과 모델을 통해 도출된 y값(=y_hat)의 차이로 정의되었는데, 여기선 정의된 잔차는 입력값이 x 와 출력값이 F(x)의 차이를 의미한다는 것이 의아한데요
* 이 이유는, 다층의 신경망의 학습이라는 점에서 찾을 수 있습니다. 다층으로 구성된 신경망 중간중간의 노드들은 목표가 되는 실제값을 알수가 없습니다. 오직 최종 노드에서의 목표가 되는 실제값만이 존재하죠. 그렇기에 중간 노드들의 목표값이 존재해야 하는데요. 이를 입력값인 x로 잡은 것입니다. 이에 대한 추가설명은 아래 그림과 그 해석을 통해서 알아보겠습니다.
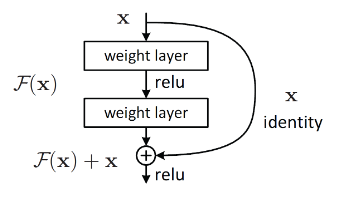
- 기존 딥러닝의 네트워크와 ResNet의 네트워크를 비교해보면 아래 그림으로 표현할 수 있는데요

* 기존 네트워크는 입력 x를 받고 weight layer를 거쳐 H(x)를 출력하는데, 이는 입력값 x를 타겟값 y로 매핑하는 함수인 H(x)를 얻는 것이 목적이기 때문입니다.
* ResNet에서 Residual Learning, 즉 잔차 학습은 H(x)를 얻는 것이 아닌, 출력인 H(x)와 x의 차이를 얻는 것을 목적으로 하고 있습니다.
* 여기서 Residual Functiong인 F(x) = H(x) - x를 최소화 시켜야하기에 결국 출력(H(x))과 입력(x)의 차이를 줄인다는 의미가 됩니다. 여기서 x의 값은 layer를 거친다고 달라지는 값이 아니기에, 결국 F(x)를 최소화 시킨다는 것은 H(x)의 값이 x의 값과 같아 지게 만드는 것을 의미합니다.
* 즉, 기존 네트워크의 H(x)는 알지못하는 최적의 값으로 H(x)를 근사 시켜야하기에 어려움이 있었는데, Residual Learning의 경우 H(x) = x 라는 최적의 목표값이 사전에 제공되기에 F(x)의 학습이 더 쉬워진다는 것입니다.
- 심층 신경망, Deep Neural Network의 경우 층이 깊어질수록 훈련이 어렵다는 단점이 생깁니다. 이는 기울기 소실(Gradient Vanishing)과 기울기 폭주(Gradient Explosion) 때문인데요
* 기울기 소실(Gradient Vanishing) : 기울기 소실은 심층 신경망의 오차 역전파간 정의된 오차(Loss) 함수에 대해 편미분을 한 값에 학습률(Learning rate)를 곱한 값을 기존의 가중치에 더해주는 업데이트가 이루어지는데, 이때 편미분 간 활성화 함수의 미분값이 1보다 작을경우, 업데이트 되는 값에 1보다 작은 값이 계속해서 곱해질 경우 결국 기울기가 소실되는 문제가 발생하게 됩니다.
* 기울기 폭주(Gradient Explosion)는 심층 신경망의 앞쪽 계층으로 갈수록 기울기가 점점 커지는 현상을 말하며, 기울기가 너무 커져 학습이 불안정해지거나, 심지어는 학습이 불가능해 지는 문제를 일으킬 수 있습니다.
- 이때 잔차 신경망, ResNet은 잔차 연결을 통해 입력에 대한 정보를 유지하면서 잔차를 학습하여 이로 인한 기울기 소실 또는 기울기 폭주 문제를 해결하였습니다.
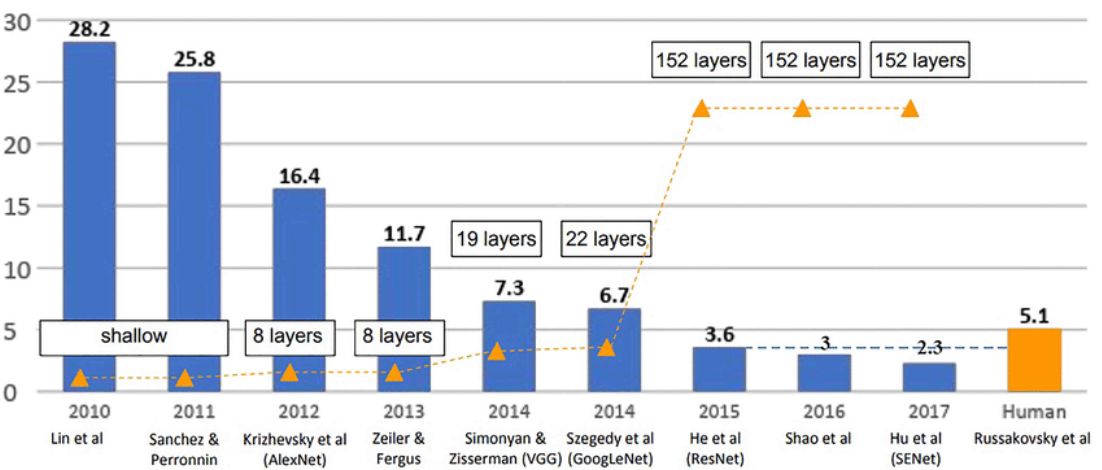
- 그렇다면, 이러한 Residual Learning의 효과는 어떨까?
* 아래에서 보듯 ILSVRC(Imagenet Large Scale Vision Recognition Challenge)의 2014년 우승자인 GoogleNet까지는 인간의 분류 오류 한계인 5%보다 높은 분류 오류인 6.7%를 보였다. 그 전년도인 2013년도의 VGG에서 조금 향상된 정도이다. 하지만, ResNet의 경우 3.6%라는 분류 오류를 기록하며 괄목한 만한 성과를 이루었다. 즉, 인간의 분류 오류 한계를 모델로서 깬 것입니다.ㅁㄴ
- 잔차블록, 즉 Residual Block은 스킵 커넥션(skip-connection)이라고도 불리는데, 이는 참조되지 않는 함수를 학습하는 대신 레이어의 입력인 x를 참조하여 잔차 함수를 학습하는 블록을 의미한다. 이를 그림화 시키면 아래와 같다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with 파이썬] PReLU란? Parametric ReLu란? (활성화함수, Activation Function) (0) | 2023.10.03 |
|---|---|
| [딥러닝 with 파이썬] ResNet(잔차신경망)의 개념 (2/2) / CIFAR-10 활용해서 이미지 분류모델 구현 (0) | 2023.10.01 |
| [딥러닝 with 파이썬] 분류(Classification) / MNIST 데이터 사용 (0) | 2023.09.29 |
| [딥러닝 with 파이토치] 파이토치로 사인(Sine) 함수 만들기 (0) | 2023.09.28 |
| [딥러닝 with 파이썬] 코랩에서 한국어용 Mecab 설치하기 (0) | 2023.09.20 |




댓글