
이번에는 SSL에서 Masking을 활용하는 대표적인 기법인 MAE(Masked Autoencoder)와 SimMIM(Simple Maskied Image Modeling)에 대해서 알아보겠습니다.
가장 직관적인 이해를 위해 Masking을 활용하는 다양한 모델들이 있지만 Vision Task에 대한 2개 모델을 설명을 위해 선정하였습니다.
1. 자기지도 학습(Self-Supervised Learning)에서 Masking 기법
- Masking은 데이터의 일부를 숨기거나 변혀앟여 학습 모델이 해당 부분을 예측하도록 유도하는 방식입니다.
- 이를 통해 모델이 데이터에 대한 더 유용한 표현을 학습할 수 있게 되는데요. 이를 정리해보면
a) 데이터의 효율성 : 일부 데이터를 감추고 나머지 데이터로 학습을 하게되므로, 같은 데이터셋에서 다양한 패턴을 학습할 수 있음
b) 일반화 능력 향상 : 특정 부분만 보면서 전체 구조를 이해해야 하므로, 모델이 데이터의 핵심 패턴을 효과적으로 학습함
- Masking 기법의 주요 유형은 크게 4가지로 볼 수 있습니다.
a) 랜덤 마스킹(Random Masking)
* 입력 데이터에서 일정 비율을 무작위로 제거하여 학습
* 특징 : 일반적인 Masking 방식으로 데이터 분포에 의존하지 않음.
b) 블록 마스킹(Block Masking)
* 연속된 구간을 한꺼번에 마스킹하는 방식
* 특징 : 연속된 단어를 마스킹(자연어 처리) 하거나 이미지의 특정 영역을 통째로 마스킹하여 복원(Inpainting) 하도록 학습
c) 점진적 마스킹(Progressive Masking)
* 처음에는 작은 비율을 마스킹하고, 점점 마스킹 비율을 증가시킴
* 특징 : 학습 초기에 쉽게 예측하도록 유도하고, 점차 난이도를 높여가며 학습 진행
d) 가중치 기반 마스킹(Importance - Based Masking)
* 중요한 특정 영역만 남기거나, 중요도가 낮은 부분을 마스킹
* 특징 : 중요도가 낮은 영역을 제거하면 더 강력한 특징을 학습할 수 있음
2. Masking을 활용한 주요 방법론 : MAE, SimMIM
2.1 MAE(Masked Autoencoder)
[ 논문 : "Masked Autoencoders Are Scalable Vision Learners" ]
- MAE는 비대칭적인 인코더-디코더 구조를 이용한 Masked Image Modeling(MIM) 방식의 모델입니다.
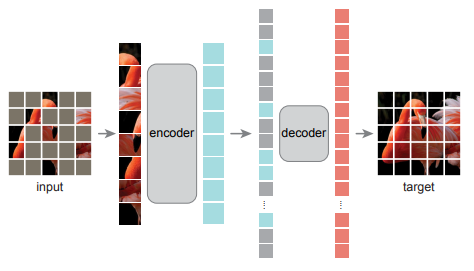
- MAE의 핵심 개념은 다음과 같은데요
1) 비대칭 구조 활용
* 인코더는 마스킹 되지 않은 패치만 처리하고, 디코더는 마스킹된 패치를 복원하는 역할을 함
2) 높은 마스킹 비율
* 전체 이미지 패치의 75%를 무작위로 마스킹하여 일부 정보만을 활용한 학습을 수행
3) 효율적인 표현 학습
* 마스킹된 데이터를 복원하도록 강제하면서 모델이 이미지의 중요한 특징을 효과적으로 학습
4) 연산량 절감
* 인코더가 전체 이미지가 아닌 일부 패치만을 처리하므로, 계산 비용이 줄어들어 대규모 데이터에서도 학습이 용이함
- MAE의 학습 목표는 아래와 같은 손실 함수를 최소화하는 것입니다.

* 즉, 마스킹 되지않은 패치를 MAE 모델의 입력으로 넣어서, 마스킹 된 패치를 예측하는 것이며, 예측과 실제 간의 차이를 L2 손실인 MSE(Mean Squared Error)를 활용하는 것입니다.
- 방법론에 대해서 정리해보면 다음과 같습니다.
1) 마스킹 기법
* 75%의 패치를 무작위로 제거합니다.
* 이를 통해 모델이 중요한 특징을 더욱 효과적으로 학습하도록 유도하는 것입니다.

* 그림의 왼쪽이 원본이고, 오른쪽으로 갈수록 각 비율로 Masking된 이미지와 MAE를 통해 복원된 이미지의 모습들입니다. 75%라는 비율은 이와 같이 다양한 비율을 적용해보면서 나온 비율이 되겠으며 그림에서 보시는 것처럼 75%가 복원을 잘 하면서도 효과적으로 데이터의 표현을 학습할 수 있는 비율로 보입니다.
2) 인코더
* ViT 를 활용한 인코더 입니다.
* 마스킹되지 않은 패치들만 입력으로 넣어주어, 연산량을 대폭 감소시켜주면서도 강력한 표현을 학습하도록 유도합니다.
3) 디코더
* 인코더의 출력 벡터에 마스킹된 패치의 정보를 추가하여 원본 이미지를 복원합니다.
* 인코더보다는 상대적으로 가벼운 형태의 디코더를 활용합니다.
* 이때 디코더는 일반적인 ViT 형태의 디코더입니다.
4) 손실 함수
* 손실함수는 픽셀 수준의 Mean Squared Error를 활용합니다.

- 실험 결과를 확인해보겠습니다.
먼저, 마스킹 비율에 대한 실험입니다.
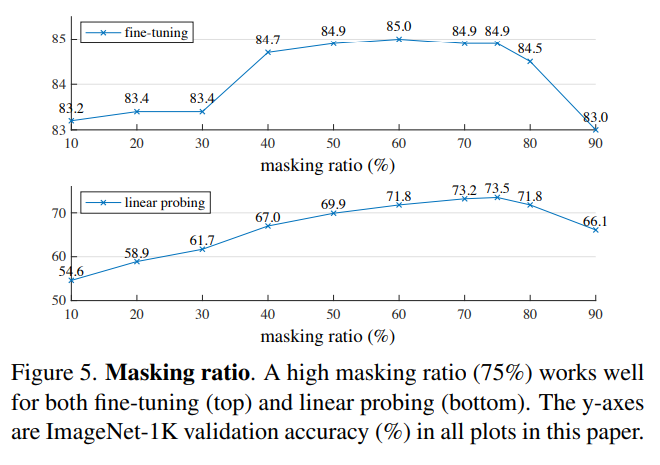
위의 결과는 각기 다른 마스킹 비율로 MAE를 학습시킨 뒤, ImageNet 데이터를 활용해 분류 결과를 나타낸 것입니다.
분류결과는 전체 클래스에 대한 평균 Accuracy를 의미합니다.
이 중 위 그래프는 fine tuning(MAE로 ViT를 학습시킨 뒤, ViT의 끝단에 선형 분류기를 추가하여 ImageNet 1K 데이터에 대한 분류 Task로 재학습한 결과) 결과이며
아래 그래프는 linear probing(MAE로 ViT를 학습시킨 뒤, ViT의 끝단에 선형 분류기를 추가한 뒤 ViT의 학습된 파라미터는 고정하고 선형 분류기만 학습이 가능하도록 만듦)을 한 결과입니다.
위 두 결과를 모두 종합했을 때, 75% 정도가 가장 최적의 결과로 보입니다.
다음 실험 결과는 다른 SSL 기반 방법론들과 비교한 결과이며, 인코더의 크기를 달리하여(ViT-B, ViT-L, ViT-H, ViT-H448) 실험한 결과입니다.
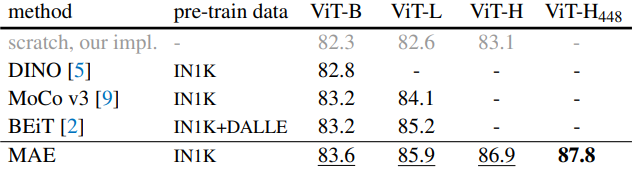
자기지도학습은 1N1K 데이터를 위주로 진행했으며, 보여지는 수치는 ImageNet 1K 데이터에 대한 분류 정확도를 의미합니다.
다음은 COCO 및 ADE20K 데이터에 대한 segmentation 결과이며 역시 좋은 결과를 보임을 알 수 있습니다.

전반적으로 MAE의 결과가 우수함을 알 수 있습니다.
- MAE 모델에 대한 결과 및 의의를 종합해보면
a) 비대칭적인 구조로 인해 연산량을 절감한 효율적인 구조를 가지고 있으며
b) 다양한 다운스트림 태스크(분류, 세그멘테이션 등)에서 우수한 성능을 보임을 알 수 있습니다.
2. 2 SimMIM (Simple framework for Masked Image Modeling)
[ 논문 : " SimMIM: a Simple Framework for Masked Image Modeling " ]
SimMIM은 MAE보다 더욱 간단한 Masked Image Modeling 기법입니다.
- 핵심 특징을 알아보면
1) 대칭 구조 활용 : 마스킹 된 패치도 인코더에 직접 입력되며, 복잡한 디코더 없이 처리
2) 더 단순한 복원방식 : MAE와 달리 디코더 없이 인코더가 직접 마스킹된 영역을 예측하도록 학습
3) 빠른 학습 속도 : 연산량을 줄이고, 학습 속도를 증가시켜 효율성을 극대화
4) 픽셀 복원 기반 학습 : MSE 손실을 사용하여 마스킹된 부분을 복원하도록 유도
이때 학습의 목표가 되며 최소화 시키고자 하는 손실함수는 아래와 같습니다.

* 즉, 마스킹된 패치를 입력에 넣어서 인코더가 직접 예측 값을 만들고 그 예측값이 실제 마스킹된 패치와의 비교를 통해 그 차이가 최소화되도록 한다는 것입니다.
* 이때 사용하는 손실함수는 픽셀 단위의 l1 loss인 Mean Absolute Error 입니다.
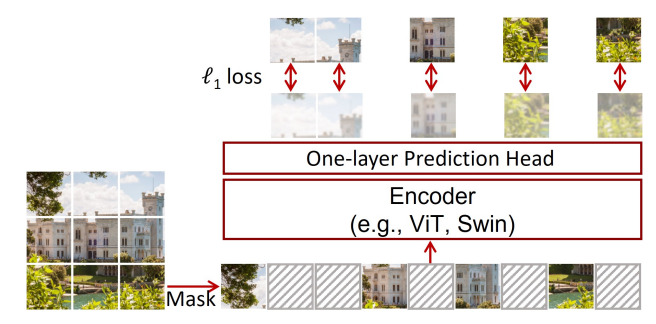
- 방법론을 정리해보면 아래와 같습니다.
1) 마스킹
* 60 ~ 80%의 패치를 무작위로 마스킹을 합니다.
* 이때 서로 연관되어 마스킹하는 것이 아닌 정말 독립적으로 마스킹을 랜덤하게 적용하는 것입니다.
아래 예시는 논문에서 제시한 60%로 고정하여 랜덤으로 마스킹한 모습이며, 다른 점은 마스킹되는 패치의 크기가 다르다는 점입니다.

2) 인코더
* SimMIM도 역시 인코더는 ViT를 활용합니다.
* 이때 마스킹된 패치도 함께 입력으로 받습니다.
3) 디코더
* 단순한 선형 디코더를 활용합니다.(MLP 형태)
* 복잡한 복원 과정없이 예측을 수행합니다.
4) 손실함수
* 손실함수는 픽셀 기반 L1 손실을 활용합니다.
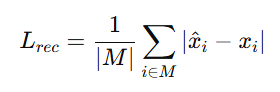
결과를 확인해보면
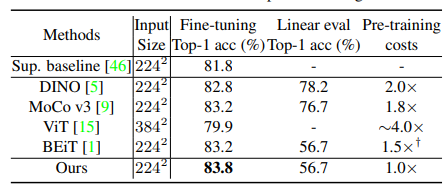
단순한 supervised 방법만을 적용했을때보다
simmim 방법으로 pretrain 인코더를 활용해 다시 Imagenet 데이터로 finetune을 했을때 전반적으로 성능이 좋아지며, 특히 제안하는 모델인 SimMIM(Ours)가 좋은 것을 알 수 있습니다.
하지만, fine tune 없이 simimim으로 pretrain된 인코더를 활용해 단순한 linear probing을 적용했을때의 경우 에는 성능이 좋지는 못해보입니다.
대신 ssl을 활용한 pretraining cost인 연산량이 가장 작은 것을 알 수 있습니다.
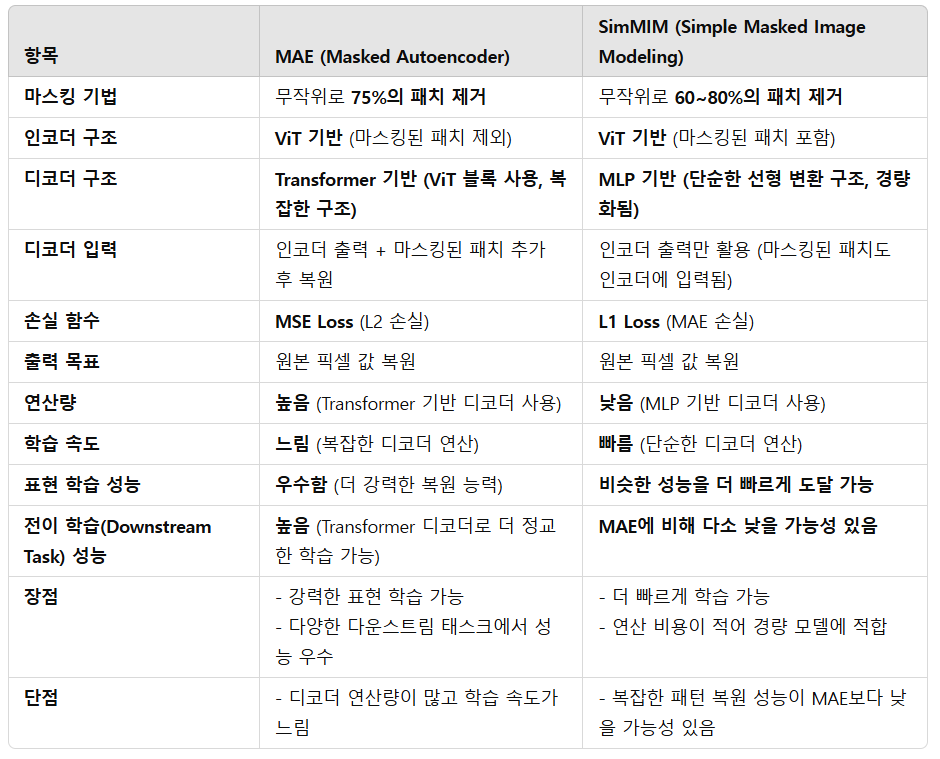
앞서 알아본 MAE와 SimMIM의 차이점을 아래와 같이 표로 정리해볼 수 있습니다.




댓글