
이번 포스팅은 SSL(Self-Supervised Learning, 자기지도학습)에 대해서 알아보는 포스팅의 시리즈입니다.
지난번에 알아본 방법들은,
* Pretext task
[딥러닝 with Python] Self-Supervised Learning (1) : Pretext Task
[딥러닝 with Python] Self-Supervised Learning (1) : Pretext Task
1. Self-Supervised Learning(SSL)이란?- SSL(자기지도 학습)은 레이블 없이 데이터를 학습할 수 있는 대표적인 학습기법으로, 최근 AI연구에서 큰 주목을 받고 있는 방법입니다. - 특히 딥러닝 모델이 사전
jaylala.tistory.com
* Contrastive Learning(대조학습)
[딥러닝 with Python] Self-Supervised Learning (2) : 대조학습(Contrastive Learning)
이었는데요
이번에는 Invaince라는 개념을 중심으로 활용한 방법론에 대해서 알아보겠습니다. 물론 앞서 알아본 논문들도 불변성(Invariance)라는 개념을 활용했지만,
이번에 포스팅 할 내용은 불변성이라는 개념을 대조학습이 아닌 방식으로 활용한 방법들에 대해서 집중하고자 합니다.
1. 불변성(Invariance)을 활용한 자기지도학습(Self-Supervised Learning) - 비대조학습(Non-Contrastive Learning)을 중심으로
- 최근 딥러닝에서 레이블이 없는 데이터를 활용하는 자기지도학습(Self-Supervised Learning, SSL)이 주목을 받고 있으며, 그 중 특정한 변환(Augmentation)에 대해 불변성을 학습하는 방법은 중요한 개념입니다.
- 일반적으로 대조학습(SimCLR, MoCo 등)의 방식이 많이 연구되었지만, Contrastive loss 없이도 좋은 성능을 내는 Non-Contrastive Learning 기법들도 많이 등장했습니다.
- 이때 불변성(Invariance)란, 주어진 입력 데이터에 다양한 변환(Augmentation)을 가하더라도 본질적인 의미를 유지하는 특성을 학습하는 것을 의미합니다.
- 자기지도학습에서는 이미지의 회전, 색상 변화, 크롭핑 등의 변환을 적용한 후, 변환 전 후의 데이터가 같은 표현 공간(Embedding Space)에서 가깝게 유지되도록 학습하게됩니다.
-이를 수식을 바탕으로 표현해보면,
입력 데이터 x 에 대해 두 개의 변환 t1, t2 ~ T 를 적용 했을 때,
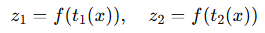
가 성립합니다.
- 여기서 f()는 신경망의 인코더 (예 : ResNet )입니다.
- 불변성 학습의 목적은 아래와 같습니다.

- 이때 대조학습에서는 z1과 z2를 가깝게 만들면서 동시에 다른 샘플들과는 멀어지도록 학습하지만,
오늘 알아볼 비대조학습(Non-Contrastive Learning) 기반의 방법론들은, Negative sample 없이 Positive Pair만을 활용해서 학습을 진행하는 방법을 말합니다.
- 이때 비대조학습(Non-Contrastive Learning)의 개념은 아래와 같습니다.
* 대조학습의 경우 Positive Pair는 가깝고, Negative Pair는 멀어지게 학습을 해야하지만, 이는 충분한 Negative sample이 필요한 방식이기에 학습이 진행되는 Batch가 커져야 한다는 제약조건이 붙게 되고 이를 통해 batch의 크기나 메모리사용량이 커지게 되는 문제가 발생합니다.
* 그렇지만, 비대조학습의 경우, 오직 Poisitive Pair에 대해서만 학습을 진행하며, 추가적인 정규화 기법(Regularization)을 통해 Collapse(모든 표현이 동일한 벡터로 수렴하는 문제)를 방지하는데요
* 비대조 학습의 핵심 요소는
a) 두 개의 변환된 샘플의 표현이 가깝도록 학습
b) 하지만, 완전히 같아지는 Collpase를 방지하기 위해 Eigenvalue Regularization(고유값 정규화), Asymmetric Architecture(비대칭적인 네트워크 구조), Predictor Network(추가적인 예측기 네트워크 활용) 등의 방법을 활용해
오직 Positive Sample만을 가지고 풍부한 표현을 학습하는 방법을 말합니다.
- 다음 챕터에서는 비대조학습에서 대표적인 방법인 BYOL(Bring Your Own Latent)와 Barlow Twins에 대해서 알아보고자 합니다.
2. BYOL(Bring Your Own Latent)와 Barlow Twins
2.1 BYOL(Bring Your Own Latent)
- 먼저 알아볼 방법론은 BYOL 입니다.
- " Bootstrap Your Own Latent A New Approach to Self-Supervised Learning"(NeurIPS 2020) 에 등장한 방법입니다.
- BYOL의 핵심 아이디어는
1) 같은 이미지에 대해 두개의 변환을 적용해 Representation을 학습
2) 하나는 Studnet Network(Online), 다른 하나는 Teacher Network(Target)로 설정하여 학습을 진행
3) Teacher Network는 EMA(Exponential Moving Average) 방식으로 업데이트되어 점진적으로 안정된 Representation을 형성
4) Stop-Gradient Trick을 사용해 Collapse를 방지
입니다.
- BYOL의 주요 아키텍처는 다음과 같습니다.
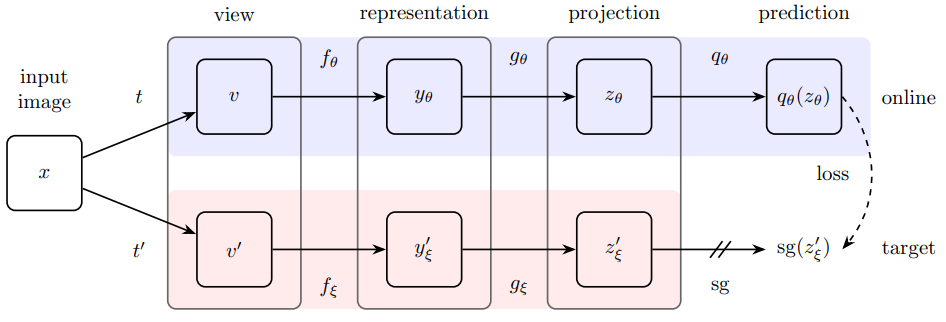
- 위 그림을 바탕으로 단계별로 BYOL을 설명하겠습니다.
1) 데이터 변환 및 View 생성
* 입력 이미지 x 에대 두개의 랜덤 변환인 t와 t'을 적용해 두 개의 view를 만듭니다.
* 이를 통해 v (= t(x)) 와 v' (=t'(x)) 가 나오게 됩니다.
2) Represneation 학습
* 각 View를 서로 다른 네트워크를 통해 Representation으로 변환합니다.
* f_θ 는 Online / f_ξ는 Offline인 Target Network(Teacher Network)입니다.

여기서 θ는 학습되는 가중치이고, ξ는 θ의 EMA(Exponential Moving Average) 업데이트 버전입니다.
[딥러닝 with Python] 딥러닝에서 Online과 Offline 학습
[딥러닝 with Python] 딥러닝에서 Online과 Offline 학습
딥러닝에서 학습 방식은 Online learning(Online 학습) 과 Offline Learning(Offline 학습)으로 나뉩니다. 이 두 개념은 데이터 처리방식과 학습 과정에서의 접근 방식에 따라 차이가 있습니다. 이번 포
jaylala.tistory.com
3) Projection Head 적용
* Representation을 Projection head 인 g를 통해 변환합니다.
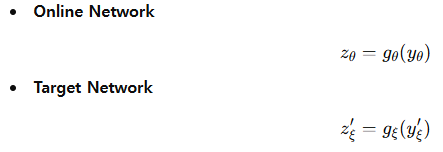
4) Prediction 및 Loss 계산
* Online Network에는 추가적인 Predictor인 q를 사용해 Target Representation을 예측하도록 만들어줍니다.
* 하지만 Target Network의 Representation인 z'ξ는 Stop-gradient를 적용해 학습되지 않도록 합니다.
* 그리고 두 벡터간의 유사도를 최소화하는 Loss를 계산해줍니다.

5) Teacher Network 업데이트
* Teacher Network의 가중치 는 Online Network의 가중치 θ\theta 를 EMA 방식으로 업데이트 합니다.

- 이렇게 BYOL은 대조학습 없이도 Collapse 현상을 방지할 수 있는 메커니즘을 가지고 있는데요. 그 이유는 아래와 같습니다.
a) 비대칭 네트워크 구조 : Online Network와 Teacher Network를 분리하여 학습
b) Stop-Gradient 적용 : Teacher Network는 학습되지 않고 Online Network만 학습
c) EMA 업데이트 : Teacher Network는 EMA 방식으로 점진적으로 업데이트되므로 안정적인 Representation 형성
- 기존의 Contrastive Learning과 BYOL을 비교해보면 아래와 같습니다.

2.2 Barlow Twins
- 다음으로 알아볼 방법론은 Barlow Twins입니다.
- 논문 " Barlow Twins: Self-Supervised Learning via Redundancy Reduction "(ICML 2021) 에 등장한 방법입니다.
- Barlow Twins의 목표는 두 개의 변환된 이미지 표현이 서로 같아지도록 하는 것과 동시에, 각 feature 간 정보 중복(Redundancy)를 줄이는 것인데요
- Barlow Twins의 핵심 아이디어는 다음과 같습니다.
1) 같은 이미지에 대해 두 개의 변환을 적용하여 Representation을 학습
2) 두 Representation을 비교하여 서로 유사하도록 만들면서도, feature 간 상관성이 낮아지도록 학습
3) Negative Pair 없이도 효과적인 학습이 가능하며, Batch Size 의존성을 줄이고 Collapse 현상을 방지하도록 합니다.
- Barlow Twins의 아키텍처는 아래와 그림과 같습니다.
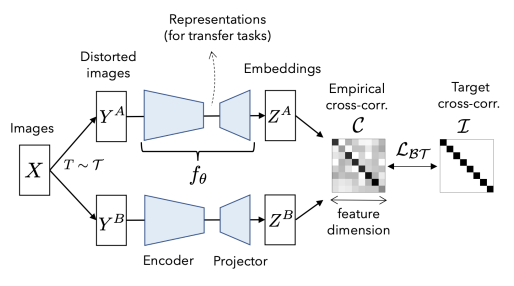
- 이를 바탕으로 Barlow Twins의 학습 방법을 단계별로 설명드리겠습니다.
a) 데이터 변환 및 View 생성
* 입력 이미지 X에 대해 두 개의 독립적인 변환 T ~ T를 적용해 두 개의 View를 생성합니다.
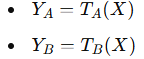
* 각각 다른 변환이 적용된 이미지를 네트워크에 입력하여 Representation을 학습합니다.
b) Representation 학습
* 각 View를 동일한 인코더에 통과시켜 Feature Representation을 얻습니다.
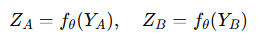
* 인코더를 통과한 Representation을 Projection head를 통해 변환하여 최종 Feature embedding을 얻습니다.
c) Cross-Correlation Matrix 계산
* 배치 단위로 Representation 간의 상관 행렬(Cross-Correlation Matrix) C를 계산합니다.

* 이 행렬의 목표는 아래와 같은데요
대각 성분은 1에 가까워야하는데, 이는 같은 feature는 같은 정보를 가져야 한다는 의미이고
비대각 성분은 0에 가까워야하는데, 이는 다른 feature 간 상관관계가 없어야 한다는 것이며 이는 정보 중복(Redundancy)를 제거해야 한다는 것입니다.
이 의미가 직관적으로 다가오지 않을수도 있는데요. 이를 설명하기 위한 예제는 아래와 같습니다.

d) Barlow Twins Loss 계산
* Barlow Twins의 최종 목표는 Cross-Correlation matrix인 C가 단위 행렬인 I에 가깝도록 만드는 것입니다.

이 Loss를 최소화하면 Representation이 서로 유사해지면서도 정보 중복이 최소화된 Representation을 학습할 수 있게 됩니다.
- Barlow Twins가 똑같은 샘플을 다르게 Augmentation하는, 즉 Positive Sample만을 활용해서 학습을해도 Collapse가 발생하지 않는 원리는 다음과 같습니다.
a) Cross-Correlation Matrix 정규화
* 단순한 MSE Loss를 활용하면 모두 동일한 값으로 수렴하는 Collapse 문제가 생길 수 있으나, 상관 행렬을 단위 행렬로 정규화하면 각 Feature 간 정보 분포가 다양하게 유지되며 Collapse가 방지가 됩니다.
b) Feature 간 정보 독립성 유지
* 대조 학습에서는 Representation 간 거리를 조절하는 방식으로 Collapse를 방지하지만, Barlow Twins는 Feature 간 상관성을 줄이는 방식으로 Collapse를 방지합니다.
이를 통해 Negative Sample 없이도 Representation 간의 다양성이 유지되며, 의미있는 표현 학습을 할 수 있습니다.
- Barlow Twins와 기존의 대조학습을 비교해보면 아래와 같습니다.

2.3 BYOL과 Barlow Twins의 비교
- 두 방식은 아래와 같은 공통점을 가지고 있습니다.
* 자기지도학습 방식의 일종
* Negative Sample 없이 학습함
* Projection head가 필요 (Encoder의 Representation 능력의 품질을 높이기 위함)
* Batch size 의존성 낮음
- 하지만 다음과 같은 차이점이 존재합니다.
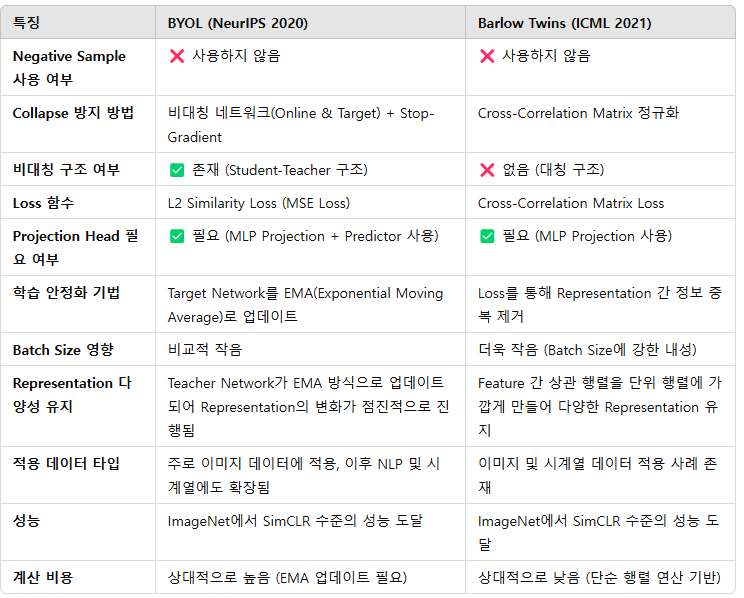
- 이 두 방식 중 어떤 방식을 사용해야 할지 고민 된다면 아래 내용을 참조하면 되겠습니다.
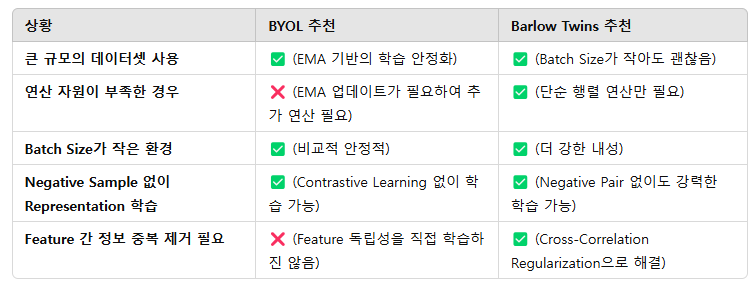
즉, BYOL은 연산량이 상대적으로 많지만 강력한 Representation을 학습할 수 있고, Barlow Twins는 연산량이 적고 Batch Size에 더 강한 내성을 지니게 됩니다.
* 연산량과 자원이 충분하다면 BYOL을
* 구현의 간단성과 연산 자원의 효율성을 추구한다면 Barlow Twins를 추천드립니다.




댓글