
- Vision-Language Models(VLM)은 이미지와 텍스트를 동시에 이해하고 처리하는 모델로, 대표적으로 Flamingo [Alayrac et al., 2022], MM1 [McKinzie et al., 2024] 등이 있습니다.

- 이러한 모델들이 높은 성능을 보이기 위해서는 고품질의 멀티모달 데이터가 필수적이며, 이를 보장하기 위해서는 체계적인 Data Curation(데이터 정제 및 선별 과정)이 필요합니다.
- 이때, Data Curation은 단순한 데이터 수집을 넘어, 노이즈 제거, 데이터 정리, 라벨링 및 품질 평가 등의 과정을 포함합니다. 특히, VLM에서는 텍스트와 이미지의 **연계성(Alignment)**을 유지하면서, 학습에 적절한 데이터를 구축하는 것이 핵심 과제입니다.
- 이번 포스팅에서는 Data Curation에 대한 전략과 중요성을 다루고자합니다.
1. Interleaved Data Curation: VLM을 위한 필수 과정
- VLM의 성능을 높이기 위해서는 Interleaved Data(텍스트와 이미지가 자연스럽게 섞인 데이터)가 필수적입니다.
- Flamingo 및 MM1과 같은 모델들은 이러한 데이터를 활용하여 Few-Shot Learning 성능을 향상시킨 것으로 보고되었다.
- Interleaved Data Curation에는 크게 두 가지 접근 방식이 있습니다.
1) 자연 발생적(자연적인) Interleaved 데이터
- 대표 데이터셋: OBELICS [Laurençon et al., 2023]
" OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents "
- 웹 문서에서 텍스트와 이미지가 함께 포함된 데이터를 그대로 유지하면서 수집한 데이터셋

- 주요 처리 과정
* Common Crawl을 활용한 데이터 수집 (영어 텍스트 중심)
* 중복 제거 및 HTML 문서 전처리 (유용한 DOM 노드만 유지)
* 이미지 필터링 적용 (로고 제거, 불필요한 이미지 삭제)
* 텍스트 품질 필터링 (잘못된 문장 및 의미 없는 데이터 제거)
*장점: 자연스럽고 현실적인 멀티모달 컨텍스트 제공
*단점: 데이터 품질이 일정하지 않으며, 정제 과정이 복잡함
2) 합성(Synthetic) Interleaved 데이터
- 대표 데이터셋: MMC4 [Zhu et al., 2023]
" Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text "
-텍스트 데이터에 추가적으로 이미지를 매칭하여 인위적으로 멀티모달 데이터 생성

- 주요 처리 과정:
* 텍스트 코퍼스 수집 (인터넷에서 수집된 방대한 텍스트 데이터)
* 이미지-텍스트 매칭 (CLIP 기반 유사도 점수를 활용하여 가장 적절한 이미지와 연결)
* 데이터셋 구성 (다양한 도메인에 대해 멀티모달 데이터 구축)
* 장점: 방대한 텍스트 코퍼스를 멀티모달 데이터로 확장 가능, 스케일링에 유리
* 단점: 자연스럽지 않은 조합이 발생할 가능성이 있으며, 실제 웹 문서에서 발생하는 문맥적 정보 부족
2. VLM 학습을 위한 데이터의 품질 평가
- VLM의 성능을 좌우하는 중요한 요소는 데이터의 품질입니다.
- 하지만 이 품질은 주관적인 요소가 포함되어 있어 일관적으로 정의하기가 매우 어려운데요.
- 기존 연구에서는 텍스트, 이미지, 정렬(Alignment) 등 다양한 측면에서 데이터의 품질을 평가하는 방법을 제안하고 있습니다.
1) 텍스트 품질평가
- QuRating [Wettig et al., 2024]: 텍스트의 논리적 일관성과 가독성을 평가하는 시스템
" QuRating: Selecting High-Quality Data for Training Language Models "
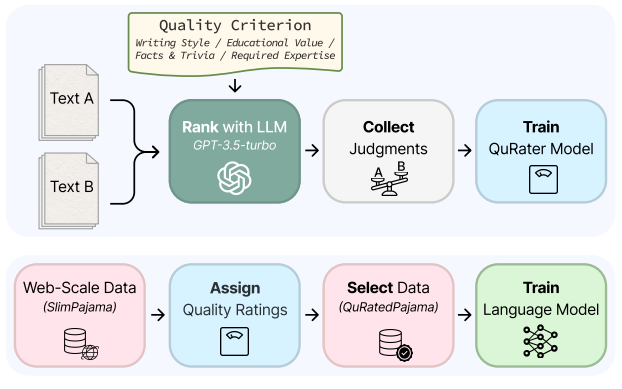
- Data-efficient LMs [Sachdeva et al., 2024]: 데이터 효율성을 고려한 텍스트 필터링 방법
" How to Train Data-Efficient LLMs "

- 텍스트 품질 기반 필터링(Sharma et al., 2024): 잘못된 텍스트를 걸러내어 최적의 서브셋 생성
2) 이미지 품질평가
- VILA [Ke et al., 2023]: 이미지의 시각적 품질을 정량화하는 방법론
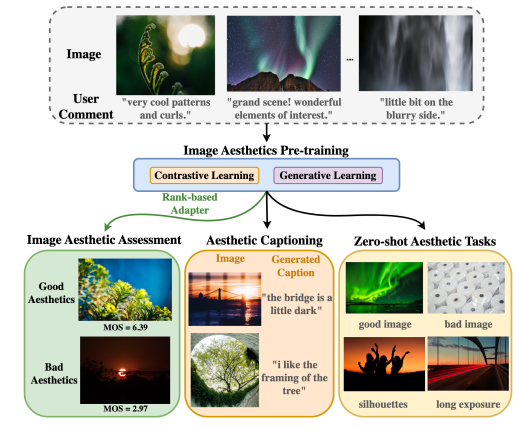
- LAION-aesthetics [Schuhmann, 2023]: 이미지 데이터셋의 미적 품질을 평가하고 필터링
3) 텍스트-이미지 정렬 평가(Alignment)
- CLIP 기반 평가 [Radford et al., 2021]: 텍스트-이미지 매칭의 일관성을 평가
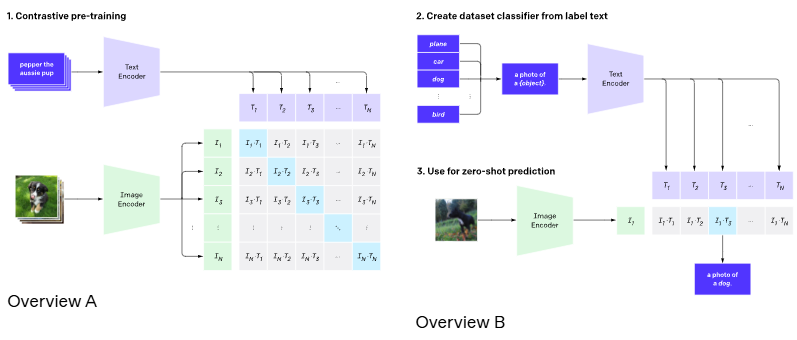
- Alignment 평가 기법 [Xu et al., 2024; Gao et al., 2024]: 텍스트와 이미지 간의 의미적 연계를 정량화하는 모델
'딥러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] Prophet 모델 구현하기(시계열 예측) / Peyton Manning 웹 트래픽 데이터 활용 / [Google 코랩] (0) | 2025.03.02 |
|---|---|
| [Deep Learning with Python] 그래프 신경망(GNN)과 기존 신경망의 차이 (0) | 2025.03.02 |
| Contrastive Learning 기초 : EBM, NCE, InfoNCE (0) | 2025.02.28 |
| [딥러닝 with Python] Self-Supervised Learning (1) : Pretext Task (0) | 2025.02.28 |
| [딥러닝 with Python] Pix2Pix란? (0) | 2025.02.27 |




댓글