
이번에 알아볼 것은 Contrastive Learning에서 핵심 개념인
EBM(Energy Based Model), NCE(Noise Contrastive Estimation), 그리고 InfoNCE의 개념에 대해서 자세히 알아보고 이를 정리해보도록 하겠습니다.
1. EBM(Energy Based Model), NCE(Noise Contrastive Estimation), 그리고 InfoNCE
1) EBM(Energy Based Model)
- 에너지 기반 모델(EBM)은 확률론적 프레임워크를 제공하며, 에너지 함수 를 이용해 실제 데이터에는 낮은 에너지를 할당하고 비실제 데이터에는 높은 에너지를 할당합니다
- 이때 에너지를 정의하기 위해 볼츠만 분포(Boltzmann Distribution)을 활용합니다.
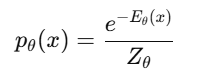
여기서 Z_theta는 정규화 항(Partition Function)으로 아래와 같이 정의됩니다.

- 각 데이터별로 볼츠만 분포가 계산이 될 것이고, 학습의 목표는 이 에너지들을 최소화시키는것입니다. 여기서 모델의 매개변수인 theta를 추정하기 위해서는 Negative Log Likelihood로 정의된 아래와 같은 함수를 최소화시켜야합니다.

- 이때 Gradient는 다음과 같이 계산이되며
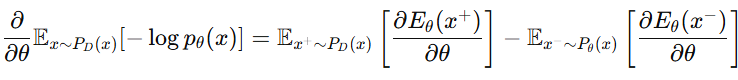
- Negative sample인 x- 를 직접 샘플링 하는 것은 계산적으로 너무 비용이 크기에, 이를 근사하는 방법으로 추정하고 있습니다.
여러 기법들이 있지만 대표적으로 MCMC 샘플링, Score matching, 그리고 다음에 소개할 NCE 기법이 있습니다.
2) NCE(Noise Contrastive Estimation)
- NCE는 위에서 정의된 밀도를 추정하는 대신, 학습을 이진 분류 문제로 변환하는 기법이 되겠습니다.\
- 모델의 분포에서 Negative smaple에 대해 샘플링을 하는대신, 노이즈 분포에서 샘플을 추출하는 학습을 하는 것입니다.

- 이때 u가 실제 데이터라고 한다면, u'은 실제 데이터에 노이즈를 추가한 데이터라고 보시면 되겠습니다.
- 여기서 Positive sample은 원본 데이터들이고, Negative Sample은 Noise가 추가된 샘플들입니다.
-이를 통해 모델은 실제 데이터와 노이즈 데이터를 구별하는 역할을 수행하게 되는데요. 이때 정의된 Loss function은 Binary Cross Entropy(BCE) 형태로 정의하면 됩니다.


- 이때, 우리가 학습시키고자하는 네트워크 마지막 단에 이진 분류를 해야하는 분류기를 달아야하며 해당 분류기 또한 학습해야될 파라미터를 가지고 있습니다.
- 이는 우리가 학습시키고자하는 네트워크가 Overfitting되지 않도록 해주는 역할을 할 수도 있지만, Underfitting 되게 할 수도 있습니다.
- 즉, 학습에 의도치 않은 변수가 추가되었다고 볼 수 있습니다.
3) InfoNCE : NCE의 확장된 방법
- InfoNCE는 NCE의 확장된 형태로, Non-parametric Softmax 방식을 사용하여 positive와 negative sample 간의 관계를 정의합니다.
- 여기서 비모수적이라는 것은 positive와 negative의 관계를 Distance (유클리디안 Distance 또는 Cosine Similarity) 기반의 방법들을 활용하여 계산하여 이를 기준으로 각 샘플을 구분하기에
결국 이를 위해 학습해야 될 파라미터가 없어지는 것입니다.
- 여기서 Positive sample은 원본에서 Augmentation 기법(Rotation, color jittering 등)이 적용된 샘플이고, Negative Sample은 그 밖의 모든 샘플입니다.
- 이는 이진 분류 대신, 모델이 poisitive sample 간의 유사도를 극대화 하고 negative sample과의 거리를 증가시키도록 학습되는 것인데요. 아래는 Cosine similairty를 기반으로 구성된 Loss function입니다.
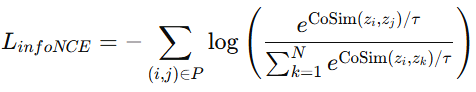

- 이 InfoNCE는 SimCLR 방법에서 사용된 것으로 유명합니다.
* 아래는 SimCLR 논문(" A Simple Framework for Contrastive Learning of Visual Representations ")에 첨부된 방법론 그림과 손실함수입니다.

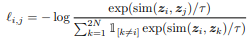
2. NCE와 InfoNCE 비교
- InfoNCE가 그 후에 나왔다고해서 무조건 더 좋은건 아닙니다. 이 둘은 장점과 단점이 존재합니다.
- VLM에서 유명한 CLIP 모델은 2021년에 나와서 InfoNCE를 바탕으로 학습이 진행되었지만, 2023년에 나온 SigLIP 논문은 NCE를 활용해 더 낮은 비용으로 더 좋은 0-shot performance를 보이기도 했는데요.
- 이 둘에 대한 특징을 비교한 표는 아래와 같습니다.

- 위를 간단히 요약해보면
* NCE는 명시적인 노이즈 분포를 필요로 하지만 계산 비용이 낮고 미니배치 크기에 덜 의존하며
* InfoNCE는 Contrastive Learning에 최적화된 방식으로 Positive sample 간의 관계를 강화하고 Negative sample과의 차이를 극대화하지만 큰 미니배치가 필요하여 계산비용 높다는 단점이 있습니다.
* 명시적 노이즈 분포란 학습 과정에서 negative sample을 어떤 방식으로 뽑을지 미리 설정하는 것을 의미하며, Language와 CV에서 다음과 같은 예시를 들 수 있습니다.

'딥러닝 with Python' 카테고리의 다른 글
| [Deep Learning with Python] 그래프 신경망(GNN)과 기존 신경망의 차이 (0) | 2025.03.02 |
|---|---|
| [딥러닝 with Python]Vision-Language Models(VLM)와 Data Curation의 중요성 (0) | 2025.03.01 |
| [딥러닝 with Python] Self-Supervised Learning (1) : Pretext Task (0) | 2025.02.28 |
| [딥러닝 with Python] Pix2Pix란? (0) | 2025.02.27 |
| [딥러닝 with Python] GIN 알아보기(Graph Isomorphism Network) (0) | 2025.02.27 |




댓글