
이번에는 지난번에 알아본 Prophet 모델을 활용해서 SCHD의 주가를 분석해보겠습니다.
[머신러닝 with Python] Prophet 모델 알아보기(시계열 예측)
[머신러닝 with Python] Prophet 모델 알아보기(시계열 예측)
이번에는 시계열 예측(Time Series Forecasting) 모델 중 라이브러리 형태로 쉽게 구현 가능하면서도 효과적인 Prophet 모델에 대해서 알아보겠습니다. Prophet은 (구) Facebook ( 현: Meta) 에서 만든 시계열
jaylala.tistory.com
1. Prophet 모델을 활용해서 SCHD 주가 분석하기
1.1 SCHD란?

SCHD는 미국 배당주 중심의 상장지수펀드 ETF로 배당 성장이 지속 가능한 기업들을 추종하는 ETF입니다.
SCHD에 대한 기본정보를 알아보면 아래와 같습니다.

해당 ETF의 투자 전략 및 특징은 아래와 같습니다.

2. Prophet 모델을 활용한 SCHD 주가 예측
- 해당 모델링은 구글 코랩을 활용했습니다.
- 먼저 pyplot에서 한글을 사용하기 위해 nanum 폰트를 설치하고 설정해줍니다.
!apt-get install -y fonts-nanum
!fc-cache -fv
!rm -rf ~/.cache/matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 나눔 폰트 경로 확인
font_path = "/usr/share/fonts/truetype/nanum/NanumGothic.ttf"
# 폰트 설정
font_manager.fontManager.addfont(font_path)
plt.rc('font', family='NanumGothic') # 나눔고딕 설정
plt.rcParams['axes.unicode_minus'] = False # 마이너스 기호 깨짐 방지
- 이제 prophet과 yfinance를 설치해줍니다.
# Colab 환경에서 prophet 및 yfinance 설치
!pip install prophet yfinance
- 이후 분석에 사용할 라이브러리를 설치해줍니다.
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from prophet import Prophet
- 이제 yfinance 라이브러리를 활용해서 데이터를 로드가 기본 분석을 진행해보겠습니다.
# 1️⃣ 데이터 로드 및 기초 분석
ticker = "SCHD"
df = yf.download(ticker, start="2011-01-01") # SCHD는 2011년부터 거래 시작
df = df.reset_index()
# 데이터 기본 정보 확인
df.describe()

- 해당 데이터의 결측치가 있는지 확인해봤지만 없네요
# 결측치 확인
print(df.isnull().sum())
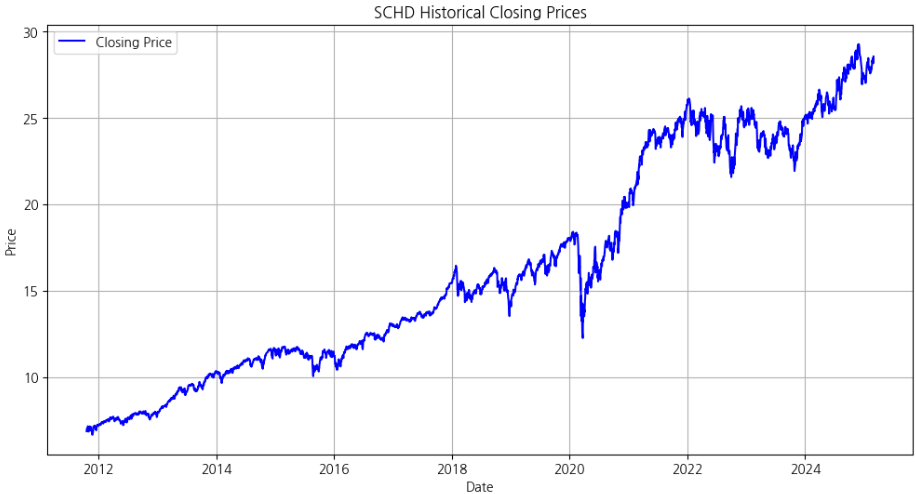
- 실제로 SCHD의 전체 데이터가 잘 로드되었는지 시각화해보겠습니다.
# 🔹 시계열 데이터 시각화
plt.figure(figsize=(12, 6))
plt.plot(df["Date"], df["Close"], label="Closing Price", color="blue")
plt.title(f"{ticker} Historical Closing Prices")
plt.xlabel("Date")
plt.ylabel("Price")
plt.legend()
plt.grid()
plt.show()
* 2025년 2월 28일까지 데이터가 아래 구글에서 검색한 데이터와 매칭해봤을때 동일함을 확인할 수 있습니다. 이상이 없네요
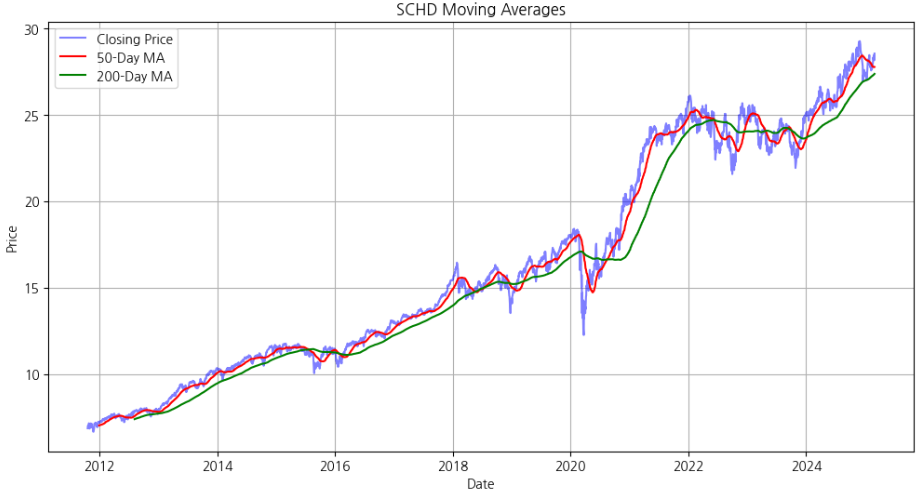
- 이제 분석에 활용할 기본 트렌드인 50일 및 200일 이동평균선을 추가해줍니다.
* 이동 평균의 공식은 아래와 같습니다.

# 🔹 이동 평균 추가 (트렌드 파악)
df["50MA"] = df["Close"].rolling(window=50).mean()
df["200MA"] = df["Close"].rolling(window=200).mean()
plt.figure(figsize=(12, 6))
plt.plot(df["Date"], df["Close"], label="Closing Price", color="blue", alpha=0.5)
plt.plot(df["Date"], df["50MA"], label="50-Day MA", color="red")
plt.plot(df["Date"], df["200MA"], label="200-Day MA", color="green")
plt.title(f"{ticker} Moving Averages")
plt.xlabel("Date")
plt.ylabel("Price")
plt.legend()
plt.grid()
plt.show()
- 이제 데이터가 잘 로드된 것을 확인했으니 Prophet 모델로 분석해보겠습니다.
* 먼저 안정적 학습을 위해 y 값을 log scale로 변환시켜주고(추후에 다시 돌릴 예정), 데이터를 모델이 fit 시킵니다.
# 2️⃣ 데이터 변환 및 Prophet 전처리
df = df[["Date", "Close"]]
df.columns = ["ds", "y"] # Prophet의 형식에 맞춤
# 🔹 로그 변환 (안정적인 예측을 위해)
df["y"] = np.log(df["y"])
# Prophet 모델 생성 (Baseline Model)
model = Prophet()
model.fit(df)
* 이후 트렌드와 seasonality 하이퍼 파라미터를 기본값으로 조절해주고, weekly seasonality도 반영해주겠습니다. 이때 90일 주기인 분기당 계절성을 추가해주고 미래 예측을 수행해보겠습니다.
예측은 1개월, 3개월, 6개월, 12개월 입니다.
# 3️⃣ 다양한 하이퍼파라미터를 고려한 모델링
# 🔹 추가적인 seasonality와 hyperparameter 튜닝
advanced_model = Prophet(
changepoint_prior_scale=0.05, # 트렌드 변화를 조절
seasonality_prior_scale=10.0, # 계절성 조절
weekly_seasonality=True,
daily_seasonality=False
)
# 🔹 계절성 추가 (분기별)
advanced_model.add_seasonality(name="quarterly", period=90, fourier_order=5)
# 모델 학습
advanced_model.fit(df)
# 4️⃣ 미래 예측 수행
future_days = [30, 90, 180, 365] # 1개월, 3개월, 6개월, 12개월 예측
future_df = advanced_model.make_future_dataframe(periods=max(future_days))
forecast = advanced_model.predict(future_df)
# 5️⃣ 결과 시각화 및 분석
# 🔹 각 예측 기간별 개별 그래프 생성
forecast_periods = [30, 90, 180, 365]
colors = ["blue", "orange", "green", "red"]
plt.figure(figsize=(12, 12))
for i, days in enumerate(forecast_periods):
forecast_subset = forecast[forecast["ds"] <= df["ds"].max() + pd.Timedelta(days=days)]
plt.subplot(2, 2, i+1) # 2x2 형태로 서브플롯 구성
plt.plot(df["ds"], np.exp(df["y"]), label="Actual Price", color="black", alpha=0.5)
plt.plot(forecast_subset["ds"], np.exp(forecast_subset["yhat"]), linestyle="dashed", color=colors[i], label=f"Forecast ({days} days)")
plt.fill_between(forecast_subset["ds"], np.exp(forecast_subset["yhat_lower"]), np.exp(forecast_subset["yhat_upper"]), color=colors[i], alpha=0.2)
plt.xlabel("Date")
plt.ylabel("Price")
plt.title(f"Forecast for {days} Days")
plt.legend()
plt.grid()
plt.tight_layout()
plt.show()
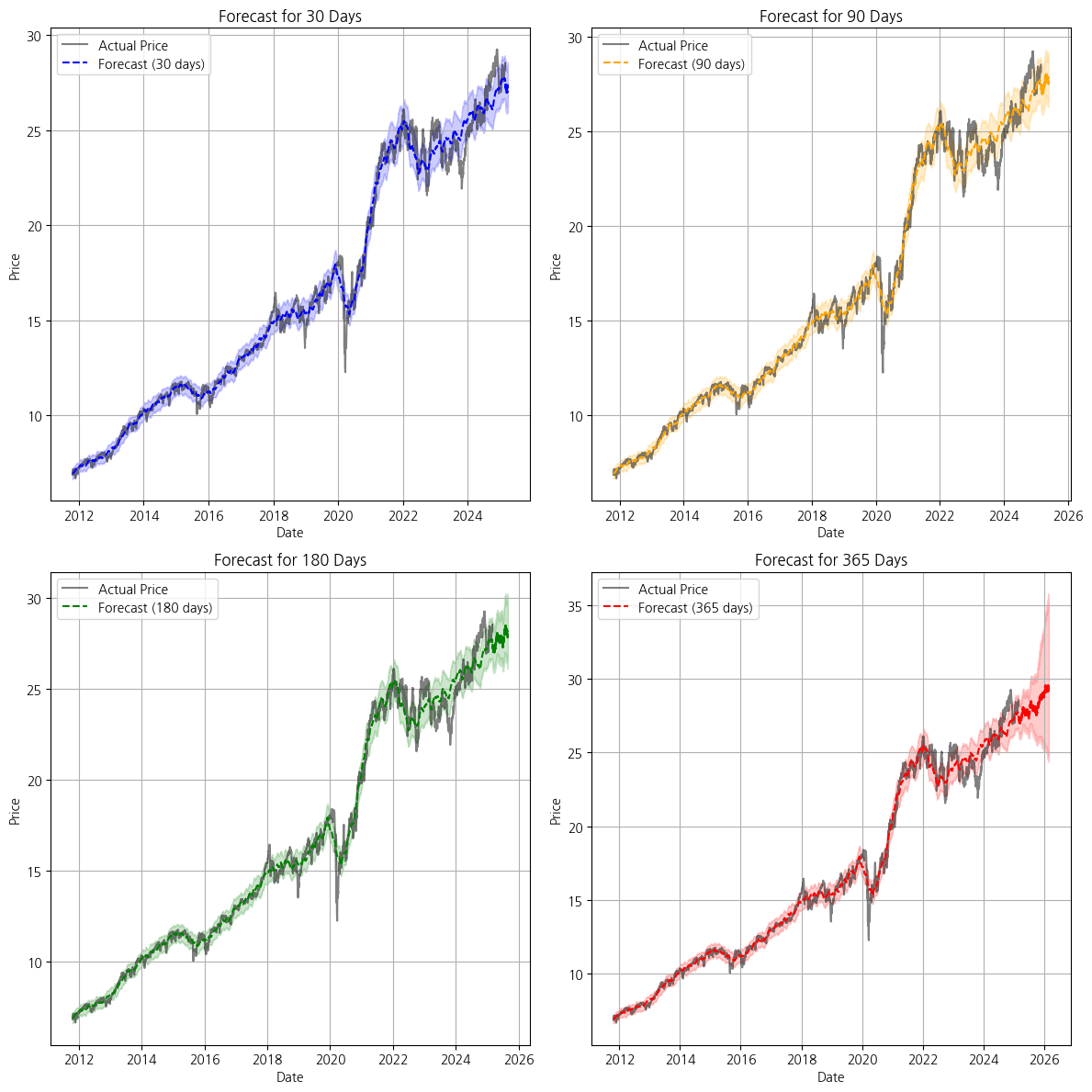
* 결과를 보시면 단기 예측인 30~90일에서 실제 줓가와 예측 주가가 거의 일치함을 볼수 있지만, 예측 텀이 길어질수록 신뢰구간이 점점 벌어지게 됨을 알 수 있습니다.
* 즉, 해당 모델의 설정으로는 30~90일 정도의 단기 에측에서의 활용에는 어느정도 괜찮음을 알 수 있습니다.
- 다음은 예측의 잔차를 분석해보겠습니다.
# 🔹 잔차 분석 (Residuals Plot)
df_forecast = forecast[["ds", "yhat"]].set_index("ds")
df_actual = df.set_index("ds")
merged_df = df_actual.join(df_forecast, how="inner")
merged_df["Residuals"] = np.exp(merged_df["y"]) - np.exp(merged_df["yhat"])
plt.figure(figsize=(12, 5))
sns.histplot(merged_df["Residuals"], kde=True, bins=30, color="red")
plt.axvline(merged_df["Residuals"].mean(), color="black", linestyle="dashed", label="Mean Residual")
plt.title("Residuals Distribution")
plt.xlabel("Residuals")
plt.legend()
plt.show()
* 이때 잔차인 Residuals은 아래와 같이 정의되며, 모델의 실제값과 예측값의 차이를 의미합니다.
Residual=Actual Price−Predicted Price
* 아래 그래프를 보면 중심이 0 근처에 위치하고 전반적으로 대칭인 모습을 보이는데요
* 잔차의 평균이 0 근처이고 정규분포에 가까우며, +- 2를 벗어나지 않기에 예측을 어느정도 신뢰할만하다고 볼 수 있습니다.
* 단, 약간의 과소 예측 경향이 있음을 알 수 있습니다.

- 다음은 해당 모델이 분석한 SCHD 데이터의 트렌드 및 계절성을 분석해서 시각화해보겠습니다.
# 🔹 트렌드 및 계절성 분석
fig = advanced_model.plot_components(forecast)
plt.show()
* 장기적인 트렌드는 점차 상승하고 있음을 나타내고 있고
* 한 주내에서 월~금요일까지 대부분 유사한 형태를 보이지만 상대적으로 수요일이 조금 더 낮은 경향성을 보이고
* 연 단위로 보았을때 10월 즈음에 가장 평가가 낮게 되고, 1월에 평가가 높게 형성됨을 알 수 있습니다.
* 분기별로 보았을때 분기 시작 후 절반 정도까지는 저평가를, 나머지 절반에서는 상대적으로 고평가를 받는다고 볼 수 있네요

- 해당 분석에 있어서 하이퍼파라미터 설정을 달리하면 결과가 바뀔수도 있으니 위 내용은 참고정도만 하는게 좋을 것 같습니다.




댓글