
이번에는 지난번에 알아본 여러 AutoML 라이브러리 중 TPOT을 활용해 Iris 데이터에 대한 분류를 진행해보고자 합니다.
1. TPOT이란?
- TPOT은 자동화된 머신러닝, 즉 AutoML의 도구로, 데이터를 전처리하고 최적의 머신러닝 모델과 하이퍼파라미터를 튜닝할 수 있는 라이브러리입니다.
- 자세한 내용은 아래 포스팅을 참조하시면 되겠습니다.
[머신러닝 with Python] AutoML이란? (AutoML의 정의, 종류 등)
[머신러닝 with Python] AutoML이란? (AutoML의 정의, 종류 등)
AutoML은 머신러닝 모델 개발 과정을 자동화하여 효율성을 극대화하는 도구입니다. 모델 선택, 하이퍼파라미터 튜닝, 데이터 전처리 등을 자동으로 처리하기에 머신러닝의 진입 장벽을 낮추어주
jaylala.tistory.com
2. TPOT을 활용한 Iris 데이터 분류
Scikit learn 라이브러리에 내장되어있는 Iris 데이터를 활용해서 분류를 진행해보겠습니다.
[머신러닝 with 파이썬] PCA / 주성분 분석 / 차원축소 /iris 데이터 활용
[머신러닝 with 파이썬] PCA / 주성분 분석 / 차원축소 /iris 데이터 활용
이번에 알아볼 것은 차원축소 알고리즘의 대표적인 PCA(주성분 분석)에 대해서 알아보겠습니다. Tabular type의 데이터에서 차원을 축소한다는 것은 곧, 변수의 개수(또는 피처의 개수)를 줄인다
jaylala.tistory.com
Iris 데이터에 대한 설명은 위 포스팅을 참조하시면 되겠습니다.
먼저, 라이브러리를 설치해줍니다. tpot과 scikit-learn을 설치해줍니다.
다음으로, TPOT을 활용해 분류작업을 진행해주겠습니다. 데이터는 Iris 데이터이고 사이킷런에 내장된 데이터를 활용해보겠습니다.
유전 알고리즘을 바탕으로 하이퍼 파라미터를 최적화함을 알 수 있으며, 5번째 Generation까지 진행되었음에도 Best CV 스코어는 0.9833입니다.
결국 도출된 최적의 모델은 MultinomialNB(다항 나이브 베이즈)와 Logistic Regression의 조합입니다.

테스트 데이터에 대한 분류 결과는 100%가 나오게 되었습니다.
이때 활용된 MultinomialNB(다항 나이브 베이즈)는 주로 범주형 데이터를 처리하는데 적합한 방법으로, 데이터를 사전에 전처리할 때 MultionmialNB를 활용하였습니다.
이때 alpha=10인데 이는 라플라스 스무딩 파라미터 값ㅅ이고, 값이 클수록 확률 분포를 더 균등하게 만들어줍니다. 또한, fit_prior=False의 의미는 사전 확률을 학습 데이터로부터 추정하지 않도록 설정하는 것으로, 이는 데이터의 클래스 분포를 무시하고 고정된 사전확률을 활용한다는 것입니다.
다음으로, 분류기로 활용된 모델은 Logistic Regression으로 C=25의 의미는 규제 강도에 대한 역수를 의미하고 값이 작을수록 더 강한 규제를 의미하는데 25라는 꽤 큰 값이 선택되었기에 규제가 상당히 약함을 알 수 있습니다.
dual=False의 의미는 데이터가 작거나 희소하지 않을 경우 선형 Solver를 사용하도록 한다는 것이고, Penalty =l2는 L2 정규화를 사용해 모델의 가중치를 최소화하면서 과적합을 방지하기 위한 정규화 기법을 의미한다는 것입니다.
그렇다면 분류된 결과를 시각화 해보도록 하겠습니다.
먼저 Confusion Matrix를 활용해 시각화 해보겠습니다.
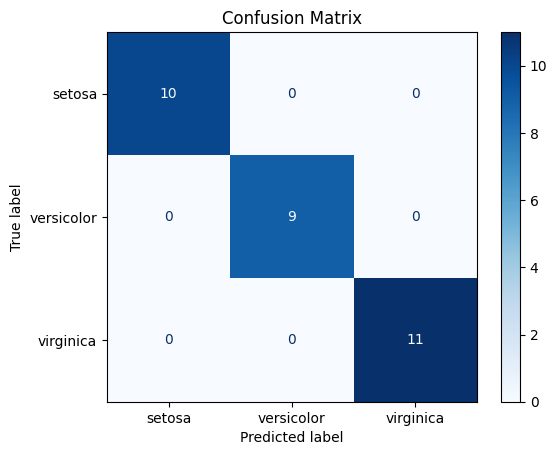
실제 레이블과 예측 레이블이 정확히 일치함을 알 수 있습니다.
다음은 ROC Curve입니다.

모든 클래스에 대해 1이라는 AUC Score가 도출되었습니다.
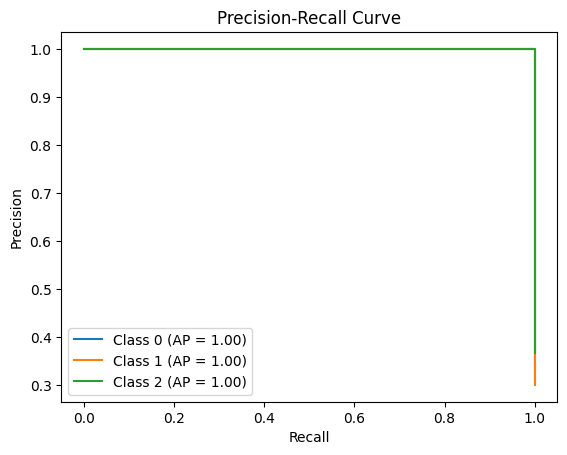
다음은 Precision-Recall Curve이고, 역시나 정확하게 잘 나옴을 알 수 있습니다.
'머신러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] Prophet 모델로 SCHD 주가 분석하기 (1) | 2025.03.07 |
|---|---|
| [머신러닝 with Python] Prophet 모델 알아보기(시계열 예측) (0) | 2025.03.01 |
| [머신러닝 with Python] 유전 알고리즘이란? TPOT에서 최적화 활용(AutoML) (0) | 2024.12.11 |
| [머신러닝 with Python] AutoML이란? (AutoML의 정의, 종류 등) (0) | 2024.12.10 |
| [머신러닝 with Python] LDA란?(Latent Dirichlet Allocation란?) / 토픽 모델링을 위한 기법 (1) | 2024.12.02 |




댓글