
[해당 포스팅은 "만들면서 배우는 생성 AI 2탄"을 참조했습니다]
1. 변이형 오토인코더(VAE, Variational Auto Encoder)란?
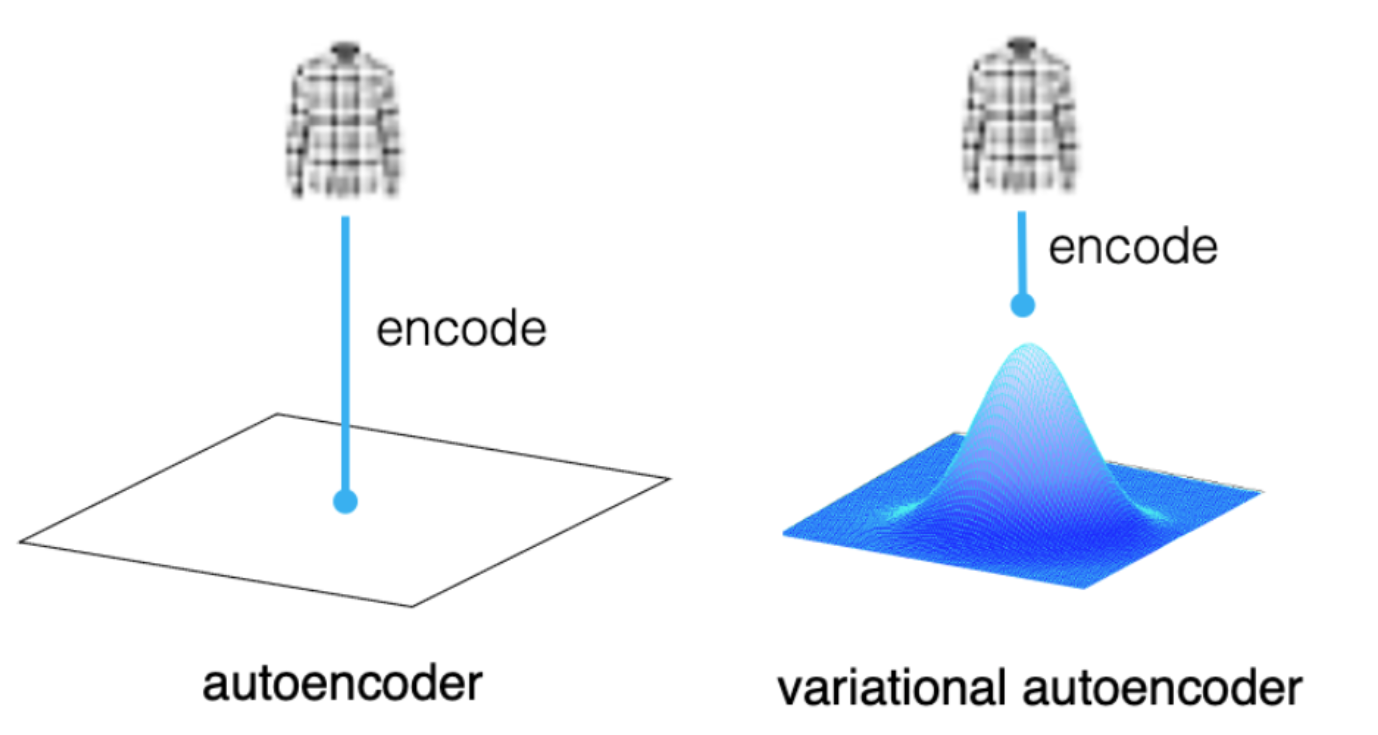
- 변이형 오토인코더, VAE는 심층 신경망을 이용한 생성 모델의 하나로, 데이터의 잠재 공간(Latent Space)을 학습하여 새로운 데이터를 생성하거나 기존 데이터를 압축하고 복원하는데 사용되는 모형입니다.
- 기존에 알아본 오토인코더(Auto Encoder)와 개념상 유사하지만, 다음과 같은 차이가 존재하는데요
[생성 AI] 오토인코더(Auto Encoder)
[해당 포스팅은 "만들면서 배우는 생성 AI 2탄" 을 참조했습니다. 1. 오토 인코더(Auto Encoder) - 오토 인코더는 단순히 어떤 항목의 인코딩과 디코딩 작업을 수행하도록 훈련된 신경망을 말합니다.-
jaylala.tistory.com
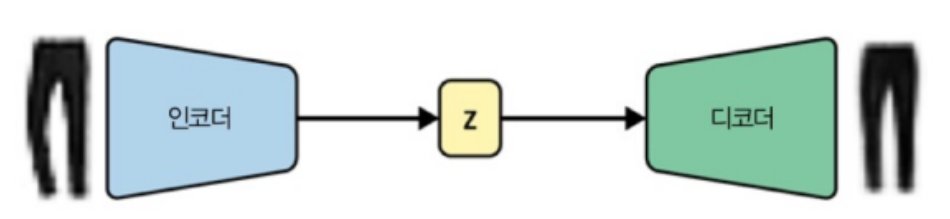
a) 오토 인코더는 각 이미지가 Latent Space의 한 포인트에 직접 매핑(Mapping)이 되지만,
b) 변이형 오토 인코더는 각 이미지가 잠재 공간에 있는 포인트 주변의 다변량 정규분포(Multi variate normal distribution)에 매핑 된다라는 차이가 있습니다
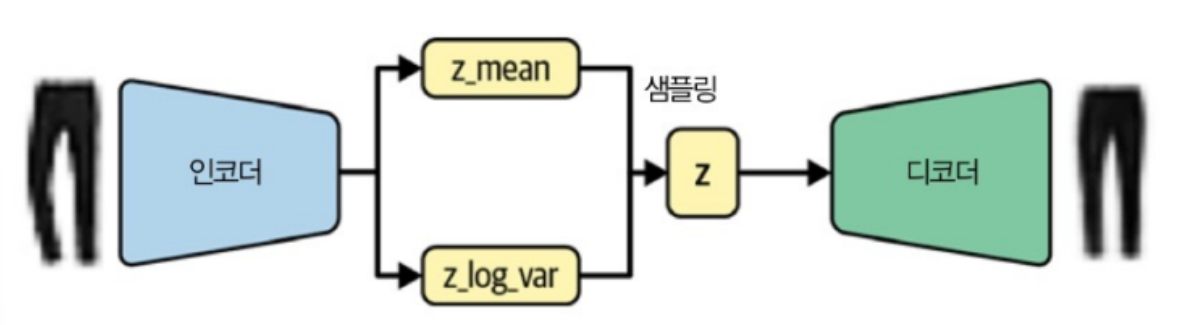
- VAE의 인코더는 각 입력을 평균 벡터와 분산 벡터에 매핑하기만 하면 되며 차원 간 공분산을 신경 쓸 필요가 없습니다.
* 이때, 변이형 오토인코더는 잠재 공간에서 차원간 상관관계가 없다고 가정하고 있습니다.
- 이로 인해 인코더는 입력 이미지를 받아 잠재 공간의 다변량 정규 분포를 정의하는 다음 2개의 벡터로 인코딩이 됩니다.
a) z_mean : 이 분포의 평균 벡터
b) z_log_var : 차원별 분산의 로그값
이를 활용해 다음식을 활용해 포인트 z를 샘플링하게 됩니다.
z = z_mean + z_log_var
(z_sigma = exp(z_log_var * 0.5) / epsilon ~ N(0,I) )
-이와 같이 잠재 벡터 z를 만드는 방법을 달리했을 때, 인코더의 역할을 향상시킬 수가 있는데요
* 오토 인코더에서는 잠재 공간을 연속형으로 만들 필요가 없었습니다. 즉, (-2,2)가 제대로 된 샌들 이미지로 디코딩하더라도 (-2.1,2.1)이 비슷해야 할 필요가 없었습니다.
* 하지만, 변이형 오토 인코더에서는 z_mean 주변 영역에서 랜덤한 포인트를 샘플링하기 때문에 디코더는 재구성 손실이 작게 유지되도록 같은 영역에서 위치한 포인트를 매우 비슷한 이미지로 디코딩해야 합니다.
=> 이는 잠재 공간에서 본 적이 없는 포인트를 선택하더라도 디코더가 제대로 된 이미지로 디코딩할 가능성을 높이는 결과를 만들어 내게 됩니다.
'딥러닝 with Python' 카테고리의 다른 글
| [딥러닝 with Python] 변이형 오토인코더(Variational Auto Encoder) 추가본 - CelebA Faces 활용 (0) | 2024.05.31 |
|---|---|
| [생성 AI] 변이형 오토인코더(Variational Auto Encoder) (2/2) (0) | 2024.05.29 |
| [생성 AI] 오토인코더(Auto Encoder) (0) | 2024.05.26 |
| [개념정리] Adaptation methods (1) | 2024.03.05 |
| [논문리뷰] Segmenter: Transformer for Semantic Segmentation (0) | 2024.02.20 |




댓글