
이번에 리뷰해볼 논문은 Segmenter: Transformer for Semantic Segmentation 입니다.
해당 논문은 2021년 ICCV에 소개된 논문이고, 2024년 2월 기준 약 1200회의 인용수를 가진 논문입니다.
해당 논문을 읽고나서 해당 논문이 기여하고 있는 부분은
모든 아키텍처가 ViT로 이루어졌으며, 이를 통해서 Semantic Segmentation에서 SOTA를 달성했다는 것입니다.
특히, 디코더 부분에서 Patch embeddings와 Class embeddings를 함께 입력하여 Semantic Segmentation을 한다는 것입니다.
논문 내용 자체가 복잡하지 않고, ViT만 이해한다면 대부분 쉽게 읽히는 논문이 되겠습니다.
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2)
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2)
이번에 알아보 내용은 Vision Transformer입니다. 해당 모델은 "An Image is worth 16x16 words: Transformers for image recognition at scale" 이라는 논문에서 등장했습니다. 해당 논문은 2021년 ICLR에서 발표된 이후, 많은
jaylala.tistory.com
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2)
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2)
지난 포스팅에 이어서 비전트랜스포머(Vistion Transformer/ ViT)에 대해서 알아보겠습니다. [개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2) 지난 시간에는 인코더 부분에 대해서 알아보았습니다
jaylala.tistory.com
그렇다면, 중점 위주로 간단하게 논문을 리뷰해보겠습니다.
1. Segmenter: Transformer for Semantic Segmentation
1) Introduction 부분에서는 Semantic Segmentation에 대해서 전반적인 설명과 함께 FCN(Fully Convolutional Network)의 등장으로 Semantic Segmentation에 Convolution filter를 적용한 다양한 방법론들이 등장하였고, U-Net과 DeepLabV3등 효과적인 모델들에 대해서 소개를 하고 있습니다.
[딥러닝 with 파이썬] U-Net 모델 구현하기 (Semantic Segmentation)
[딥러닝 with 파이썬] U-Net 모델 구현하기 (Semantic Segmentation)
[본 포스팅은 Medium의 "Semantic Segmentation in Self-driving Cars" 포스팅과 아래 블로그를 참조하여 작성하였습니다] https://blog.jovian.com/semantic-segmentation-in-self-driving-cars-3cb89aa08e9b Semantic Segmentation in Self-driv
jaylala.tistory.com
[논문리뷰] DeepLabV3+ / 이미지 분할(Image Segmentation)
[논문리뷰] DeepLabV3+ / 이미지 분할(Image Segmentation)
이번에 알아볼 모델은 DeepLabV3+입니다. DeepLabV3+는 "Encoder-Decoder with Atrous Seperable Convolution for Semantic Image Segmentation(2018)"이라는 논문에서 나온 모델입니다. 1. DeepLab 모델 - DeepLab은 V1부터 V2, V3, V3+ 까
jaylala.tistory.com
- 이와 더불어 NLP task에 사용되던 트랜스포머를 이미지 분류 영역에서 사용한 Vision Transformer의 등장으로 인해 Segmentation 분야에서도 ViT의 적용이 많이 이루어졌습니다.
- 하지만, ViT가 가지고 있는 문제점 중 하나인 Inductive bias의 부족함으로 CNN이 Encoder 또는 Decoder 부분에서 지식증류를 통한 지식전달을 하거나 하나의 구성요소로서 사용되고 있다는 것입니다.
- 이런 부분에 착안해서 해당 논문이 제시하고 있는 것은 완전히 ViT로만 구성된(Decoder 부분까지) Semantic Segmentation 모델을 만들고 이 성능이 기존 여러 모델들보다 좋았다는 성과입니다.
2) Related Work
- FCN과 Vision Transformer에 대해서 간략하게 설명하고 있습니다.
- 또한, Inductive bias 등의 문제로 인해 좋은 성능을 보여주고 있는 ViT 기반 Segmentation 모델들인 Swin Transformer와 SETR의 경우 Decoder 부분을 CNN으로 사용하고 있다고 하고 있습니다.
- 해당 연구팀은 Object Detection 부분에서 온전히 ViT만을 사용한 DETR에 대해 영감을받아서, Segmenter라는 온전히 ViT만을 사용한 Segmentation 모델을 만들었다고 하고 있습니다.
3) Our approach: Segmenter
- Segmenter의 구조에 대해서 설명을 하고 있습니다.
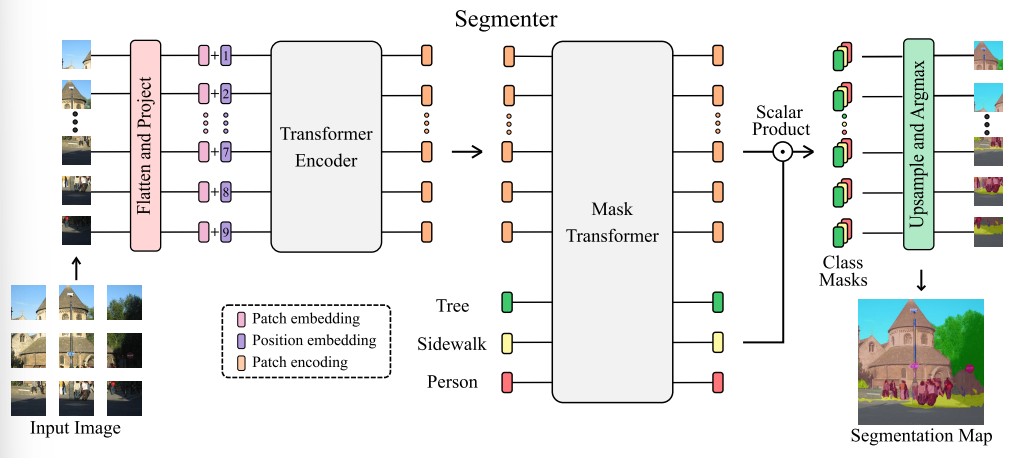
- 위 그림과 같은 구조이며 간단히 설명해보겠습니다.
- Input ~ Transformer Encoder
* 기존의 ViT와 대부분 동일합니다. 단, 최초 제시된 ViT의 경우 Image Classification을 위한 모델이다보니 Patch Embedding의 맨 앞 부분에 Class Embedding을 추가했지만, 여기서는 추가히자 않고 온전히 Patch Embedding만 Input이 되어 Transformer에 들어가게 됩니다.
* Transformer Encoder 부분에서는 잘 알고 있는 Transformer Encoder 부분과 다르지 않습니다. Multi-head Self Attention과 MLP, 그리고 중간중간 Skip connection이 이루어지는 Transformer Block들로 이루어져있습니다.
* 이 과정을 거쳐 도출된 것은 주황색의 Patch encoding입니다.
- Mask Transformer ~ Segmentation Map
* 위에서 도출된 Patch encoding과 Semantic segmentation에서 stuff를 뜻하는 Class들이 class embeddings가 되어 들어가게 됩니다. 그 숫자는 클래스의 개수만큼입니다.(위 그림에서는 Tree, Sidewalk, Person을 구분하는 것이므로 3개가 들어가게 되었습니다)
* 이 값들은 Mask Transformer에 들어가게 됩니다. Mask Transformer는 앞에서본 Transformer의 인코더와 동일한 구조이며 Block의 개수가 조금 다르며, 추가된 입력값이 들어올 수 있게 형태가 조금 변형 된 것입니다.
* 이렇게 Mask Transformer를 거쳐 나오게 된 patch encodings와 class embeddings는 서로 Scalar Product(Dot product)연산을 거치게 되고 이를 통해서
Patch encodings는 class embeddings 만큼의 Class masks를 도출하게 됩니다.
* 이렇게 도출된 Class masks는 reshape 되어 사각형의 형태가 되고, 이게 bilinear interpolation의 과정을 거쳐 원본이미지의 크기로 재현됩니다.
* 결국, 각 패치당 클래스의 개수만큼의 채널들이 더 생기게 되는 것인데요. 여기서 각 채널의 픽셀별 값들(logits)들이 전체 이미지의 크기 범위에서 softmax 함수 계산이 되어 확률의 분포로 변하게됩니다.
* 그리고 최종적으로 channel wise하게 각 동일한 위치의 픽셀들의 확률 값들이 regularization되고, 그 중 가장 높은 확률을 가진 클래스의 맵에 속한 픽셀이 해당 클래스로 표시되게 되는 것입니다.
**ex. 224x224 의 이미지에서 3x3에 위치한 픽셀이 (regularization 이후 )tree class mask에서는 0.1 / person mask에서는 0.7 / sidewalk mask에서는 0.2의 값을 가지게 된다면, 해당 위치의 픽셀은 결국 확률이 가장 높은 person으로 분류되는 것입니다.
3) 실험 관련
- 사용된 데이터는 ADE20K, Cityscapes, Pascal Context를 사용했습니다.
- 사용된 ViT의 variants는 다음과 같이 Tiny, Small, Base, Large입니다.

- 여러 Abalation study에 사용된 데이터는 ADE20K이며, 평가 지표는 mIoU입니다. Stochastic Depth와 Dropout의 비율도 ADE20K를 활용하여 정했습니다.
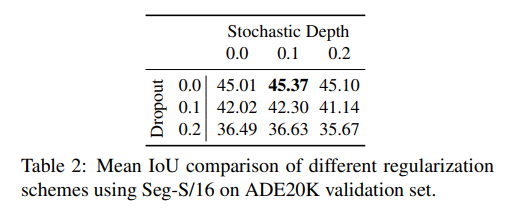
- 패치의 사이즈도 다음과 같이 여러 variants와 patch size를 ADE20K를 활용해 비교하였습니다.

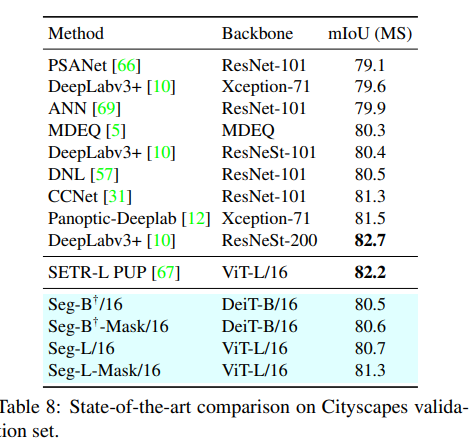
- 최종적으로 아래와 같이 결과들을 확인할 수 있었고, SOTA를 달성한 모습을 볼 수 있습니다.
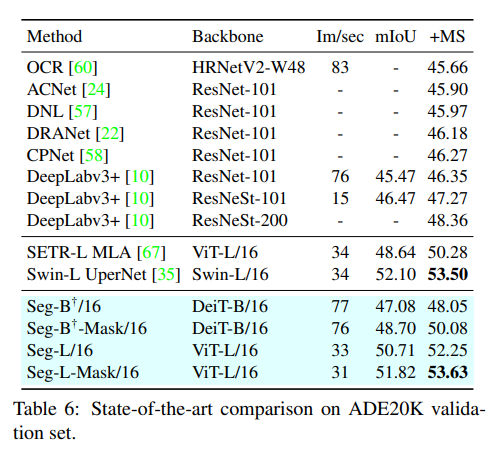
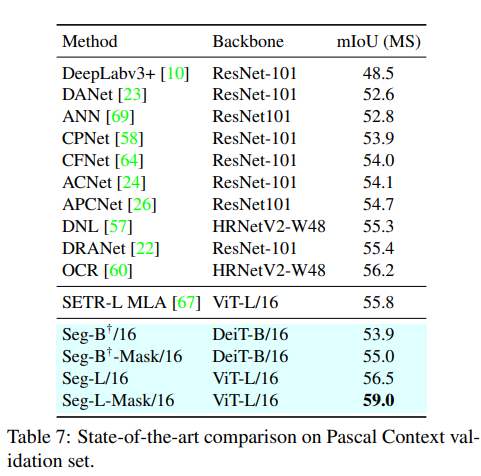
'딥러닝 with Python' 카테고리의 다른 글
| [생성 AI] 오토인코더(Auto Encoder) (0) | 2024.05.26 |
|---|---|
| [개념정리] Adaptation methods (1) | 2024.03.05 |
| [딥러닝 with 파이썬] Precision-Recall Curve와 Average Precision (0) | 2024.02.19 |
| [딥러닝 개념 정리] Inference? 딥러닝에서 Inference란? (0) | 2024.02.18 |
| [개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2) (1) | 2024.02.17 |




댓글