
이번에 리뷰할 논문은 U-Net: Convolutional Networks for Biomedical Image Segmentation 입니다.
[본 리뷰는 논문 " U-Net: Convolutional Networks for Biomedical Image Segmentation " 와
아래 medium 자료를 참고하여 제작하였습니다]
U-Net 논문 리뷰 — U-Net: Convolutional Networks for Biomedical Image Segmentation
딥러닝 기반 OCR 스터디 — U-Net 논문 리뷰
medium.com
해당 논문은 2015년 8월에 발표된 논문으로, MICCAi에 등재된 논문입니다.
U-Net 모델은 의료영상분석에서 딥러닝 기술을 활용하여 그 성과를 보여준 모델로서,
Contracting path(축소 경로)와 Exapnsive path(확장 경로)를 통해, 모델이 이미지의 정밀한 위치 정보 및 더 넓은 컨텍스트 정보를 동시에 고려할 수 있게 해주는 모델입니다.
1. U-Net의 구조 (Network Architecture)
해당 모델이 U-Net이라고 이름이 붙여진 이유는, 그 구조가 'U'자 형태를 가지고 있기 때문입니다.

이 모델은 크게 두 부분으로 나뉘어져 있으며, 크게 1) Contracting Path(축소 경로), 2)Bottleneck(병목) ,3) Expansive Path(확장 경로)로 두 부분으로 이루어져 있습니다.
(각 파란색 박스는 다채널의 특징맵(feature map)을 나타내며, 박스위의 숫자는 채널의 숫자를 나타내고 박스 아래의 숫자는 특징맵의 크기를 나타냅니다.)
여기서 Contracting path는 입력 이미지의 Context를, Expansive path는 입력 이미지의 Localization을 포함하고 있기에, 이 둘을 결합(Concatenate)하여 전체적인 Context와 세밀한 Localization 모두 고려하는 네트워크를 만들겠다는 의미입니다.
1) Contracting path(축소 경로)
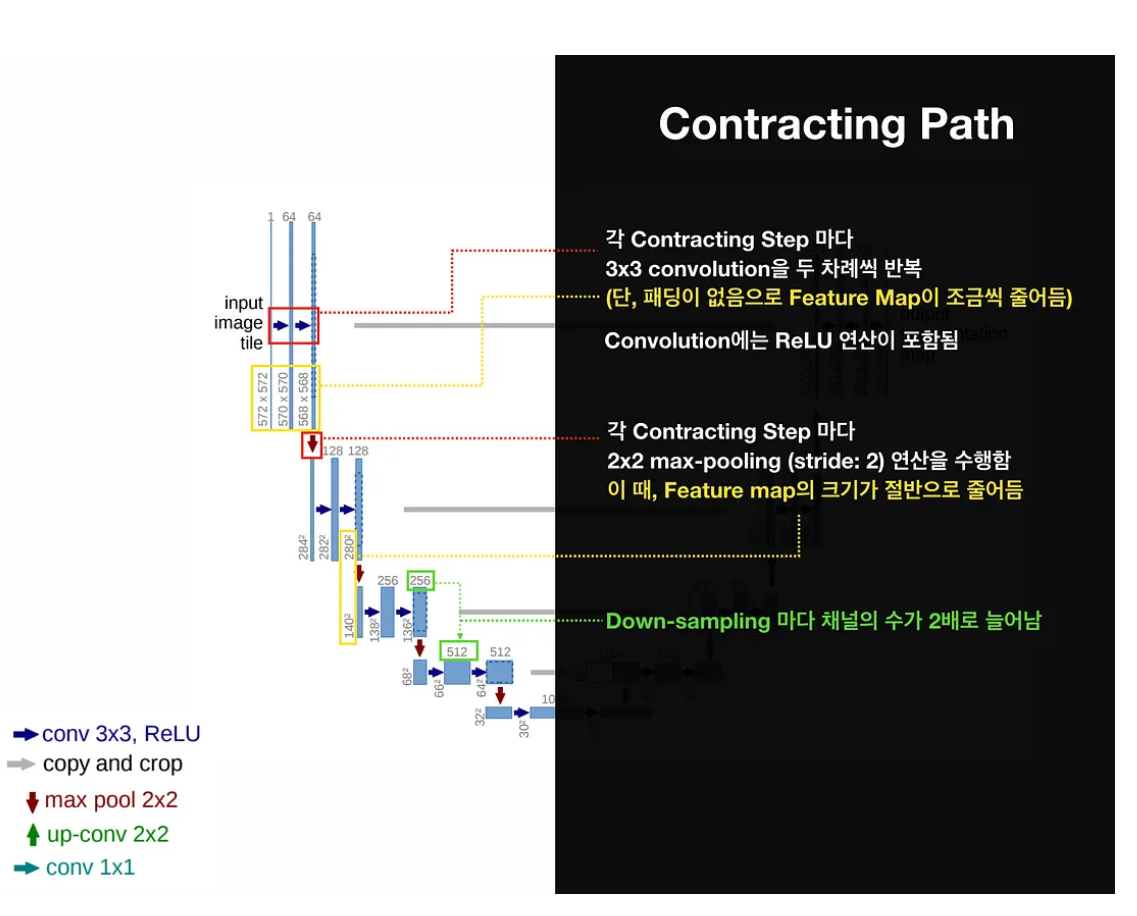
* 이 부분은 일반적인 CNN과 유사하며, 이미지의 컨텍스트를 포착하기 위해 사용됩니다. 여러개의 컨볼루션 레이어와 풀링레이어를 통해 이미지의 크기를 점차 축소 시켜나갑니다.
* 각 Contracting step마다 3x3 Convolution을 두번씩 반복하며, 해당 연산간 ReLU 연산이 포함됩니다.
* 각 Down Sampling마다 채널의 수는 2배씩 증가하지만, 2x2 Max pooling으로 인해 feature map의 크기는 절반으로 줄어들게 됩니다.
2) Bottleneck(병목, 일종의 전환 구간)
* 이는 Contracting path와 Expanding path를 연결하는 중심부분을 의미합니다. 네트워크 이미지 상 중심에 위치(그림 상 가장 아래부분)하고 있으며, 입력 이미지의 가장 추상적이고 고수준의 표현을 학습하는 부분입니다.

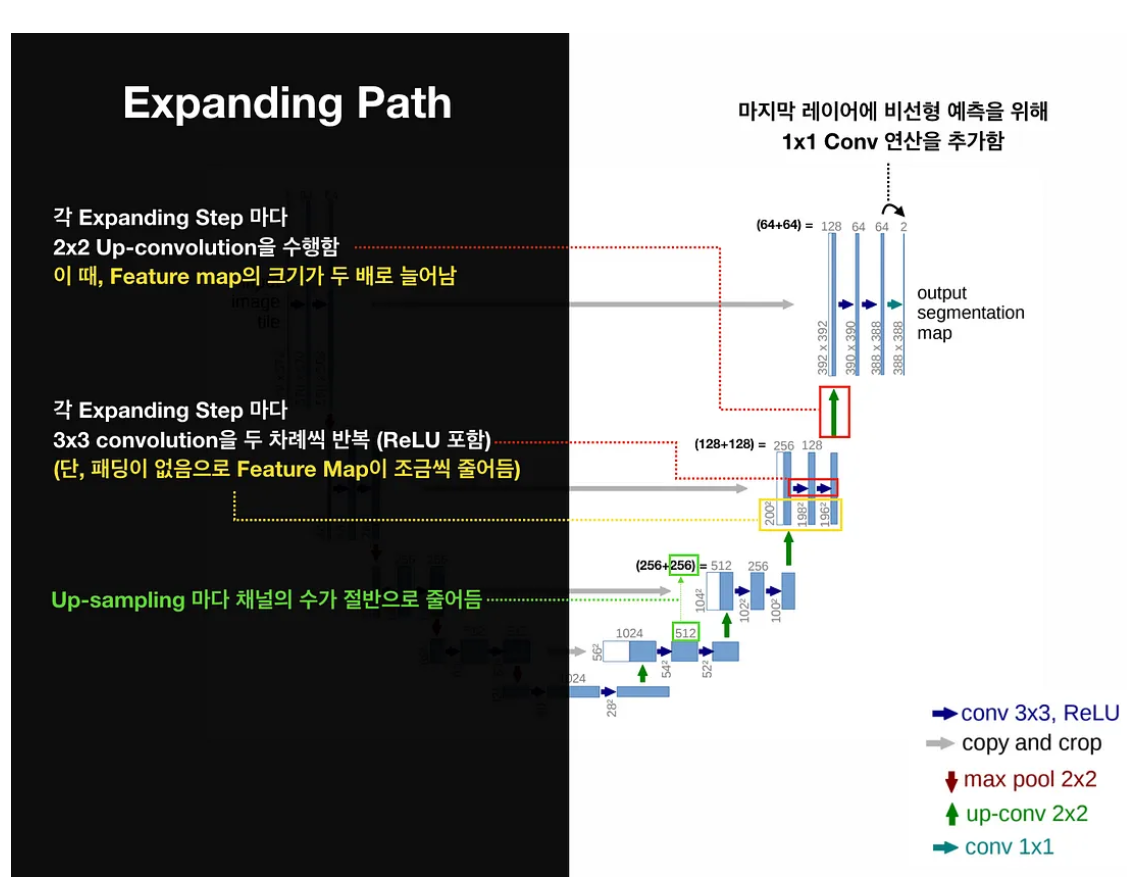
3) Expansive path(확장 경로)
* Bottleneck 다음에 위치하는 부분으로 이미지의 공간차원을 점차적으로 확장시켜나가며 세밀한 세그멘테이션을 가능하게 합니다.
* 각 Expanding step마다 2x2 Up-Convolution을 반복하며, 해당 연산간 ReLU 연산을 포함합니다.
* 각 Up-sampling마다 채널의 수는 2배씩 감소하지만, 크기가 2x2 Up Convolution으로 인해 feature map의 크기가 2배씩 증가합니다.
Skip Architecture
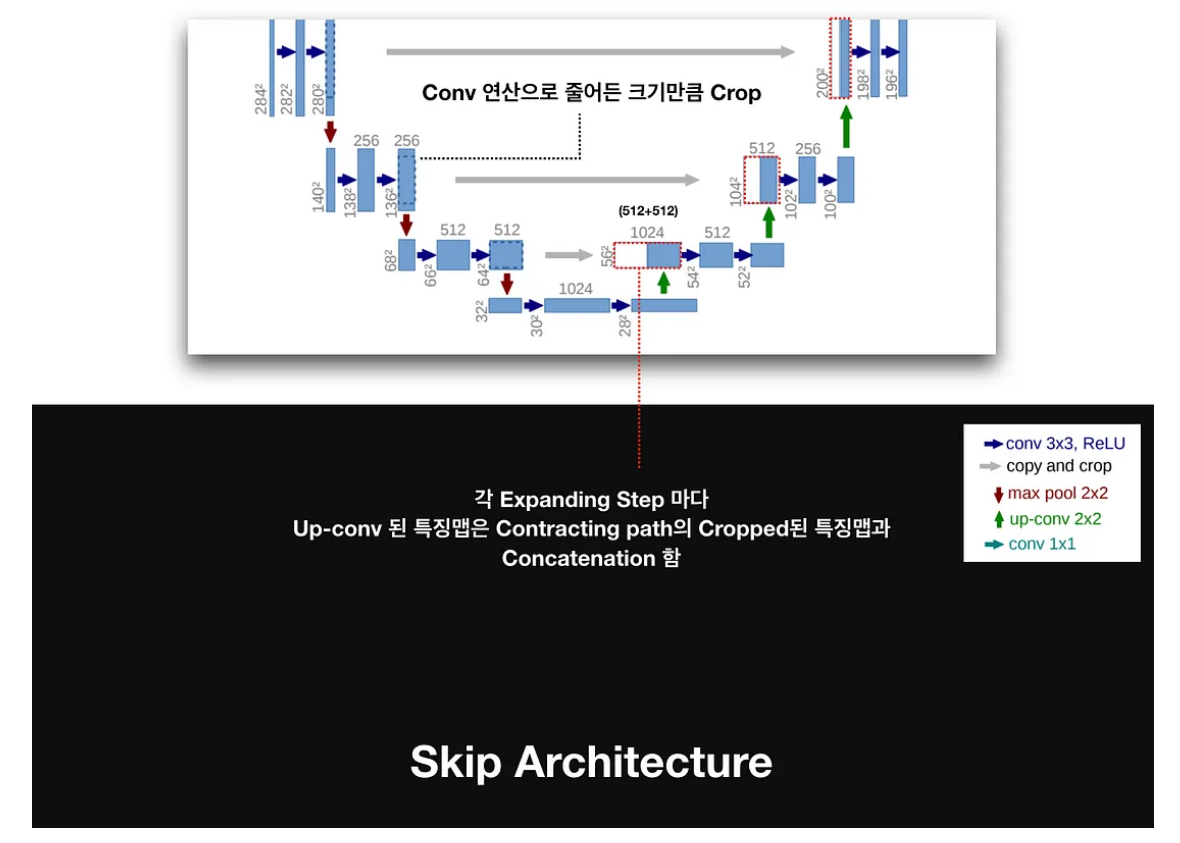
Expanding path에서는 FCN과 유사하게 Skip Architecture를 활용합니다. (위 그림에서 회색 부분입니다)
* Skip Architecture의 주요 역할을 세밀한 공간 정보와 추상적인 컨텍스트 정보를 동시에 활용하여 정밀한 세그멘테이션 결과를 얻는 것입니다.
Contracting path 과정에서 도출된 Feature map을, 동일한 Level의 Expansive path의 feature map에 더하는 것입니다. 다만 이 과정에서 동일 level의 contracting path와 expansvie path의 feature map의 크기가 다르다는 것을 알 수 있습니다. 이는 Contracting path에서 수행되는 패딩 방식으로 인해 파생되는데요
* 여러 번의 패딩이 없는 3x3 Convolution Layer 지나면서 Feature map의 크기가 줄어들 기 때문입니다.
(첫 번째 Contracting path를 예시로 들면, 첫번째 3x3 Convolution layer 지나면 572 -> 570 으로 feature map의 크기가 줄어들고, 한번 더 지나게 되면 570 -> 568로 줄어들게 됨을 알 수 있습니다. 이러한 패딩이 없는 3x3 Convolution layer를 1번 지날때 마다 feature map의 크기는 -2만큼 감소하게 됩니다.
Expansvie path에서도 패딩이 없는 3x3 Convlution layer가 계속 활용되기에 feature map의 크기는 달라질 수 박에 없는 것입니다)
* 위 모델의 feature map 크기의 변화를 보자면
572 -> (3x3 conv) -> 570 -> (3x3 conv) -> 568 -> (2x2 maxpooling) -> 284 -> (3x3 conv) -> 282 -> (3x3 conv) -> 280 -> (2x2 maxpooling) -> 140 -> (3x3 conv) -> 138 -> (3x3 conv) -> 136 -> .............................
와 같이 변하게 됩니다. 즉, feature map 크기의 입장에서 2를 빼주는 3x3 conv layer가 계속 적용되기에 2배로 늘려주는 3x3 up-conv를 거쳐도 동일 수준의 feature map의 크기가 다른 것입니다.
* 이로 인해, Contracting Path의 feature map 테두리 부분을 자른 후 크기를 동일하게 맞추어 주는 "copy and crop"의 과정으로 두 feature map이 합쳐지는 것입니다.
2. 학습 방법
본 논문에서는 크게 3가지의 학습 방법을 활용해 모델의 성능을 향상시켰습니다.
1) Overlap-Tile Input
* FCN(Fully Convolutional Network) 구조의 특성상 입력 이미지 크기에 제약이 없기에, 크기가 큰 이미지의 경우 이미지 전체를 사용하는 대신 overlap-tite라는 전략(Strategy)을 사용하여 input 값의 크기를 조절하였습니다.

* 말 그대로 큰 이미지를 작은 tile(타일)로 나누어 네트워크에 입력하고, 각 타일에 대한 세그멘테이션 결과를 얻은 후 이를 다시 조합하여 전체 이미지의 세그멘테이션 결과를 생성하는 방법을 말합니다.
* Overlap tile 방법은
1) 이미지 분할(큰 이미지를 작은 이미지로 나누며, 각 타일은 일정한 크기의 오버랩 영역을 가지고 있습니다. 이 오버랩되는 부분은 이미지 분할 과정에서 발생하는 왜곡인 아티팩트(artifact)를 줄이기 위해 사용됩니다)
2) 세그멘테이션(각 타일을 독립적으로 네트워크에 입력하여 세그멘테이션 결과를 얻음)
3) 결과 조합(각 타일의 세그멘테이션 결과를 조합하여 전체 세그멘테이션 결과를 만들며, 이때 이미지 분할간 오버랩된 부분들은 여러 타일의 결과를 조합하는 과정에서 평균화 과정을 통해 부드러운 효과(Smoothing effect)를 만들어 줍니다)

* 파란 영역의 이미지를 입력하면 노란 영역의 segmentation 결과를 얻고, 다음 tile에 대한 segmentation을 얻기 위해 이전 입력의 일부분이 포함되어야 하는데, 이때 경계 부분 픽셀에 대한 segmentation을 위해 0이나 임의의 패딩값을 사용하는 대신 이미지 경계부분의 미러링을 활용한 extrapolation 기법을 사용합니다.
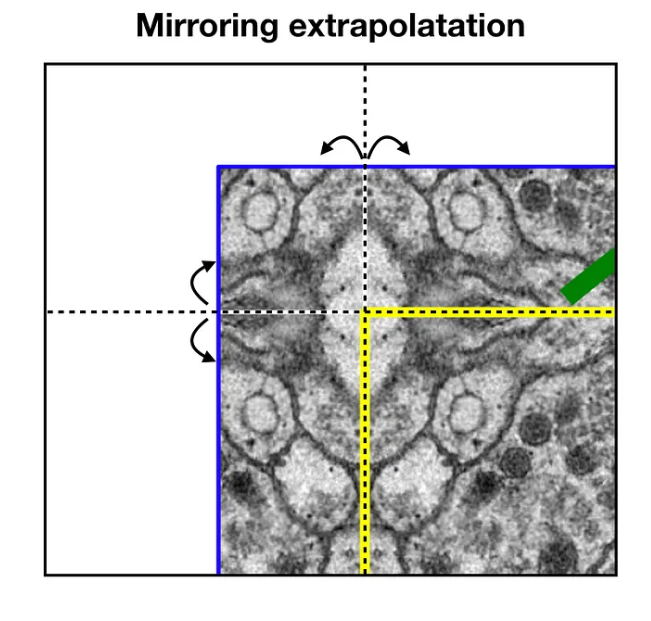
(원본 이미지의 경계부분이 거울에 반사된 것 처럼 확장)
2) Touching cells separation
* 세포를 분할(segmenation)하는 과정에서 중요한 과제 중 하나는 인접한 클래스의 접촉 개체를 분리하는 것입니다.
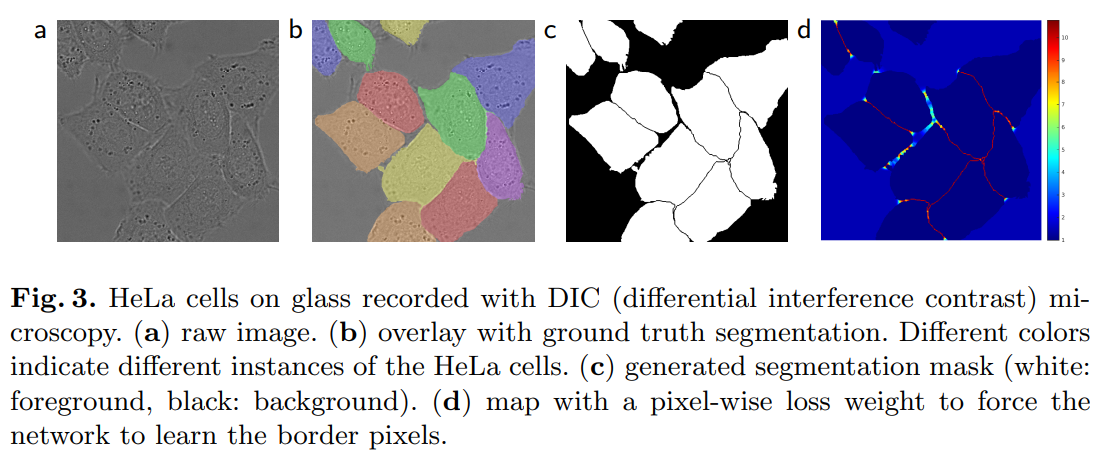
이미지 a는 raw image, b는 ground truth segmentation와 함께 제공된 overlay, c는 생성된 segmetation mask, d는 경계 픽셀을 학습하는 네트워크를 강화하기 위해 pixel-wise loss weight가 heatmap 형태로 제공된 map 입니다.
c와 d처럼 각 세포 사이의 경계를 포착할 수 있어야 하는데, 이를 위해 학습 데이터에서 각 픽셀마다 클래스 분포가 다른점을 고려하여 사전에 획득한 ground truth에 대한 weight map을 구해 학습에 반영하였습니다.
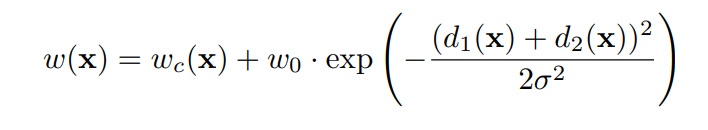

3) Training
* 네트워크의 출력 값은 픽셀 단위의 softmax로 예측하며, 즉 최종 특징맵에 대한 픽셀 x의 예측값은 다음과 같이 계산됩니다.

이에따라 Loss function은 Cross-Entropy 함수가 사용되지만, 인접한 세포들(Touching cells) 분리를 위해 Weight map loss가 포함됩니다.
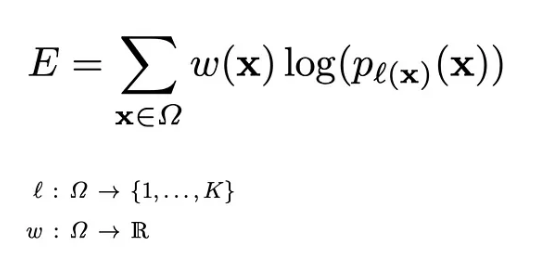
또한, 부족한 Data 숫자로 인해 해당 영역에 대한 지식 (Domain Knowledge)를 활용해 Data Augmentation을 했으며,
1) Shift(학습 이미지의 위치를 옮기기), 2) Rotation(회전), 3)Gray value(강도 변환이라고도하며, 일종의 흑백데이터로 변환), 4) Elastic Deformation(pixel이 랜덤하게 다른 방향으로 뒤틀리도록 변형)
을 적용하여 데이터 부족 문제를 해결하고자 했습니다.
3. 결과
결과적으로 U-Net은 FCN의 Skip Architecture와 Up-sampling을 활용해, 입력 이미지의 전체적인 의미와 지역화된 의미를 동시에 고려하는 모델을 만들어, segmetation에서 IOU의 향상을 가져왔습니다.
다음 포스팅에서는 파이토치를 활용해 U-Net을 구현해보겠습니다.




댓글