
이번에는 Knowledge Distillation(지식 증류)이라는 기법에 대해서 알아보겠습니다.
1. Knowledge Distillation(지식 증류)란?
- Knowledge Distillation, 우리말로 지식 증류란, 딥러닝 분야에서 큰 모델(Teacher model)의 지식을 작은 모델(Student model)로 전달하여 작은 모델의 성능을 향상시키는 방법론을 말합니다.
- 이는 NIPS 2014에서 제프리 힌튼, 오리올 비니알스, 제프 딘 세사람의 이름으로 제출된 "Distillting the Knowledge in a Neural Network"라는 논문에서 등장한 개념입니다.
- Knowledge Distillation이 등장하게 된 배경은 다음과 같습니다.
* 인공신경망 기반의 모델들이 다양한 분야에서 성과를 나타냈지만, 이러한 모델들은 더욱더 향상된 성과를 내기위해 모델의 사이즈가 커지고, 그 내부의 파라미터의 개수 또한 커지게 되었습니다.
* 이렇게 비대해진 사이즈를 가진 모델들은 실생활의 Edge Device에 활용되기 제한되며, 결과를 도출하는 시간 또한 오래 걸린다는 단점을 가지고 있습니다.
* 이를 해결하기 위해 큰 모델(Teacher model)에서 학습된 지식(Knowledge)를 증류(Distillation)하여 중요 정보를 작은 모델(Studendt model)에 전달하는 방법을 생각하게 되었습니다.
- Knowledge Distillation은 이미 훈련된 더 큰 네트워크(Teacher network)를 사용하여 수행할 작업을, 더 작은 네트워크에 단계별로 정확하게 교육함으로써 모델을 압축하는 방법을 말합니다.
- 이를 이미지 분류 학습에서 적용의 예시를 보면 아래와 같은데요
* 먼저, 복잡한 모델인 Teacher model과 간단한 모델인 Student 모델과 학습 데이터를 준비합니다.
* 이후 두 모델을 통해서 입력데이터는 학습되고 (다중 분류 문제이므로) 각 클래스에 대한 softmax 값이 도출됩니다.
* 이는 다음과 같이 특정 입력값(특정 클래스의 사진)이 들어갔을 때, 학습에 사용된 전체 클래스 별로 해당 클래스일 확률을 도출하게 됩니다.

* 이 출력값들은 해당 모델의 지식이라고 할 수 있습니다. 하지만, 이러한 값들은 softmax에 의해 너무 작아져서 모델에 반영하기 쉽지 않을 수 있습니다.
* 이를 해결하기 위해, 즉 각 클래스에 속할 확률 분포를 극단적이지 않은, soft하게 만들기 위한 과정으로 T 라고하는 값으로 각 입력값들을 나누어줍니다.
(이 T는 해당 논문에서 온도, 즉 Temperature로 표현되었고, 그래서 지식을 증류한다는 말을 사용한 것 같습니다)
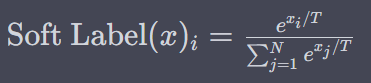
* 위와 같이 최종 결과 값들은, T를 반영한 Soft Labels를 도출하게 됩니다.
* T가 1일 경우 우리가 알고 있는 softmax의 값을 도출하며,
- Teacher model에서 도출된 soft label은, Student model의 학습 결과에서 하나의 목표, 즉 Target이 됩니다. 이로 인해, Soft Target 이라고도 합니다. Student model은 Soft Target을 지표삼아 학습을 해나갑니다.
- 그렇다면, 어떻게 student model은 teacher model에서 도출한 soft target을 지표 삼아 학습을 해나갈까요? 아래 그림과 수식을 통해서 설명해보겠습니다.
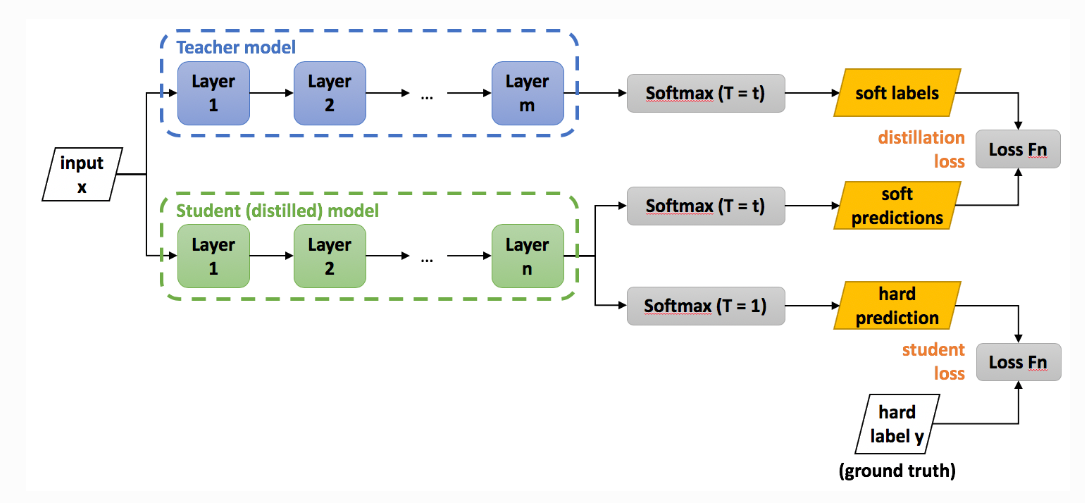

* 위 "Total Loss" 함수에서 "+" 좌측에 위치한 계산식은, 위 그림에서 표현된 student loss를 의미합니다.
이는, Student network의 분류 성능에 대한 Loss로, Ground truth와 Student의 분류 결과와의 차이를 Corss Entropy Loss로 계산하고 있습니다.
* 위 "Total Loss" 함수에서 "+" 우측에 위치한 계산식은, 위 그림에서 표현된 distillation loss를 의미합니다.
이는, Teach model과 Student model의 Output logit을 Softmax로 변환한 값의 차이를 Cross Entropy Loss로 계산하고 있습니다. (이때, 각 Output logit들은 softmax 함수에 입력되기 전에 Temperature로 나누어집니다.)
* 즉, 위 식을 요약해보면
1) Teacher Model과 Student Model의 Output logit을 T로 나눈 Soft labels와 Soft Predictions의 차이를 Cross Entropy로 계산한 "Distillation Loss"와,
2) Student Model의 Output logit을 softmax에 넣어 도출된 hard prediction과 실제 값인 hard label y의 차이를 Cross Entropy로 계산한 "Student Loss" 로
구성된 Total Loss를 정의합니다. (위 식에서 표현된 Total Loss는 하나의 예시 입니다)
( Student Loss와 Distillation Loss는 위 Alpha값과 T 값이라는 Variables에 의해 조절되며, 최적의 값을 찾아갑니다)
다음 시간에는 이러한 Knowledge Distaillation에 대해 파이썬 코딩의 예시를 통해 더 자세히 알아보도록 하겠습니다.




댓글