[본 포스팅은 "만들면서 배우는 생성 AI 2탄" 을 참조했습니다]
이번에 알아볼 내용은 조건부 GAN (CGAN / Conditional GAN) 입니다.
기존에 알아본 GAN 모형 (DC GAN, WGAN-GP)들은 훈련 세트와 유사한 사실적인 이미지를 재현해낼 수 있었지만, 생성하려는 이미지의 유형(남성 얼굴 또는 여성 얼굴, 벽돌의 크기 등)을 제어할 수는 없었습니다.
잠재 공간(Latent Space)에서 랜덤한 한 포인트를 선정해서 샘플링할 수는 있지만, 그렇다고 어떤 잠재 변수를 선택하면 어떤 특징을 변형할 수 있는 지를 알수는 없었습니다.
이 문제를 해결한 것이 CGAN이 되겠습니다.
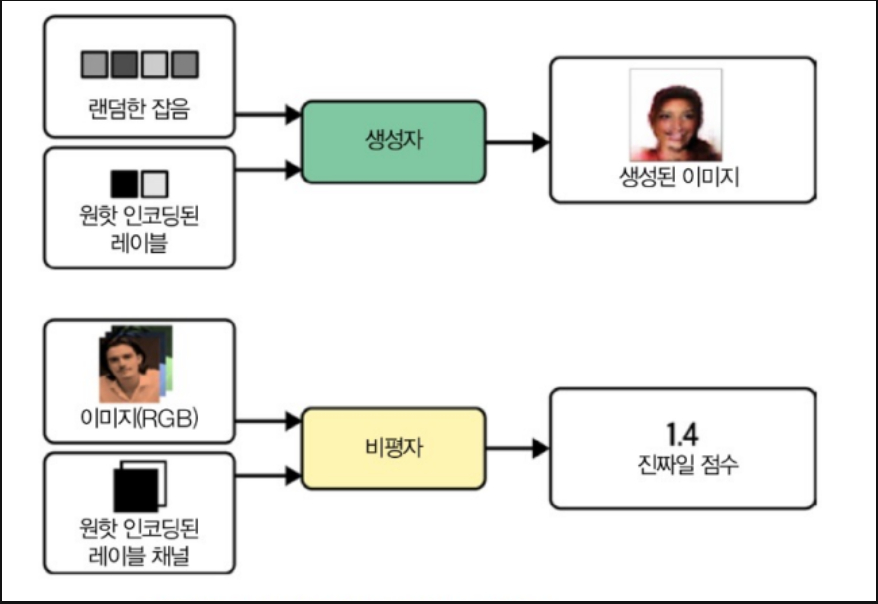
CGAN의 구조는 아래와 같습니다.
- 일반적인 GAN과 CGAN의 차이점은 레이블과 관련된 추가 저보를 생성자와 비평자 모두에게 추가적으로 전달한다는 것입니다. 생성자에서는 이 정보를 원핫 인코딩(One-Hot Encoding)된 벡터로 잠재 공간 샘플에 단순히 추가하고, 비평자에서는 레이블 정보를 RGB 이미지에 추가 채널로 추가합니다. 이를 정리해보면
a) CGAN의 생성자
* 입력 : 잠재 공간의 샘플(랜덤 노이즈) + 조건 정보(이미지의 클래스 레이블 등)
* 이때 조건 정보는 원핫 인코딩된 벡터로 제공됩니다. 원핫 인코딩 된 벡터가 가지고 있는 클래스의 수 만큼 채널의 수가 늘어나게 됩니다.
ex) 잠재공간 샘플의 차원 : 100, 레이블 개수 : 3 => 최종 입력 채널 수 : 103(=100+3)
b) CGAN의 비평자
* 입력 데이터(진짜 또는 가짜) + 조건 정보
* 이때 조건 정보는 이미지에 추가 채널로 제공됩니다. 즉, 일반적인 RGB 이미지가 입력데이터라면, 여기에 조건으로 이루어진 n개의 채널(참 : 1, 거짓 : 0으로 이루어진 경우 n = 2)을 추가해 3 + n개의 채널로 만드는 겁니다. 추가되는 채널의 개수는 이미지 레이블의 클래스의 개수에 따라 정해집니다.
ex) 입력 채널의 차원 : 3(RGB) , 레이블 개수 : 3 => 최종 입력 채널 수 6(=3+3)
이치럼 CGAN은 비평자가 이미지의 콘텐츠에 부과한 추가 정보를 참고할 수 있기 때문에 생성자는 비평자를 계속 속이려고 제공된 레이블과 출력이 일치하는지 확인해야 합니다.
만약 생성자가 이미지 레이블과 일치하지 않는 완벽한 이미지를 생성했다면, 비평자는 간단하게 이미지와 레이블이 불일치하기 때문에 가짜임을 알아차릴 수 있는 것입니다.
이제 이 CGAN을 파이썬을 활용해서 구현해보겠습니다.
먼저 util 파일을 받아줍니다.
import sys
# 코랩의 경우 깃허브 저장소로부터 utils.py를 다운로드 합니다.
if 'google.colab' in sys.modules :
! wget https://raw . githubusercontent . com/rickiepark/Generative_Deep_Learning_2nd_Edition/main/notebooks/utils . py
! mkdir -p notebooks
! mv utils . py notebooks
다음은 사용할 라이브러리를 로드해줍니다.
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import (
layers ,
models ,
callbacks ,
utils ,
metrics ,
optimizers ,
)
from notebooks.utils import display , sample_batch
학습간 사용할 하이퍼 파라미터들을 정의해줍니다.
IMAGE_SIZE = 64
CHANNELS = 3
CLASSES = 2
BATCH_SIZE = 128
Z_DIM = 32
LEARNING_RATE = 0.00005
ADAM_BETA_1 = 0.5
ADAM_BETA_2 = 0.999
EPOCHS = 20
CRITIC_STEPS = 3
GP_WEIGHT = 10.0
LOAD_MODEL = False
ADAM_BETA_1 = 0.5
ADAM_BETA_2 = 0.9
LABEL = "Blond_Hair"
학습에 사용할 데이터를 준비해줍니다. 사용할 데이터는 CelebA 입니다.
# 코랩일 경우 노트북에서 celeba 데이터셋을 받습니다.
if 'google.colab' in sys.modules :
# # 캐글-->Setttings-->API-->Create New Token에서
# # kaggle.json 파일을 만들어 코랩에 업로드하세요.
# from google.colab import files
# files.upload()
# !mkdir ~/.kaggle
# !cp kaggle.json ~/.kaggle/
# !chmod 600 ~/.kaggle/kaggle.json
# # celeba 데이터셋을 다운로드하고 압축을 해제합니다.
# !kaggle datasets download -d jessicali9530/celeba-dataset
# 캐글에서 다운로드가 안 될 경우 역자의 드라이브에서 다운로드할 수 있습니다.
import gdown
gdown.download ( id= '15gJhiDBkltMQz3T97xG-fO4gXTKAWkSB' )
! unzip -q celeba-dataset . zip
# output 디렉토리를 만듭니다.
! mkdir output
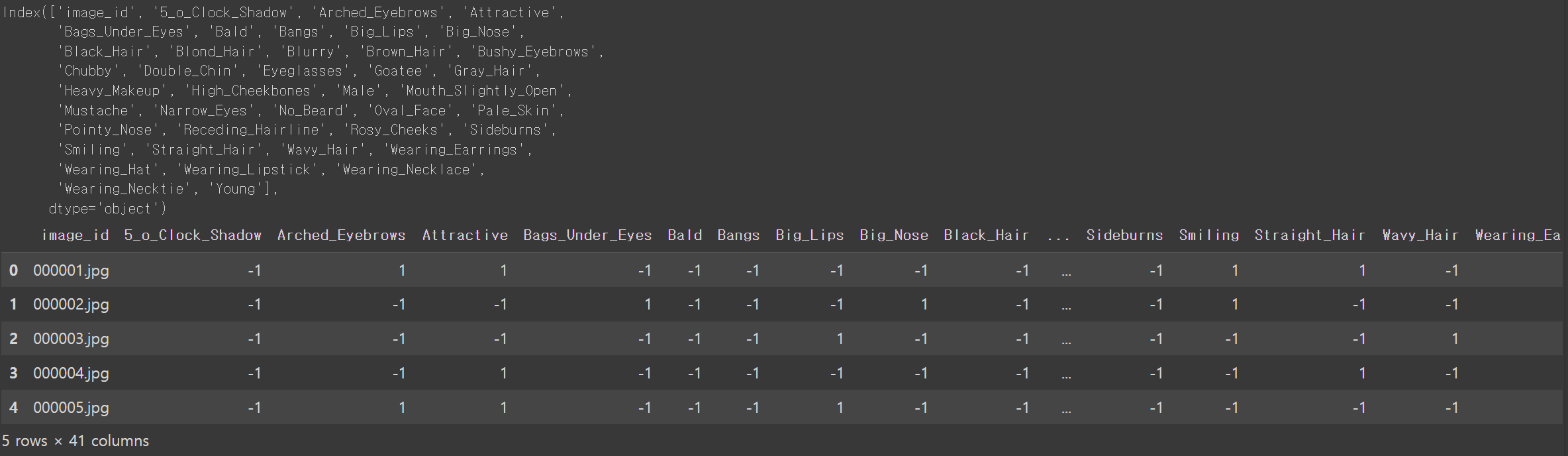
해당 이미지가 가지고 있는 레이블의 종류를 확인해봅니다.
# 레이블 데이터셋 로드
attributes = pd.read_csv ( "./list_attr_celeba.csv" )
print ( attributes.columns )
attributes.head ()
각 attributes는 1 또는 -1로 이진화 되어 있습니다.
데이터를 활용가능하게 로드해줍니다.
# 데이터 로드
labels = attributes [ LABEL ] .tolist ()
int_labels = [ x if x == 1 else 0 for x in labels ]
train_data = utils.image_dataset_from_directory (
"./img_align_celeba" ,
labels=int_labels ,
color_mode= "rgb" ,
image_size= ( IMAGE_SIZE , IMAGE_SIZE ),
batch_size=BATCH_SIZE ,
shuffle= True ,
seed= 42 ,
interpolation= "bilinear" ,
)
데이터를 전처리하고, 훈련 세트의 몇개의 샘플을 출력해봅니다.
# 데이터 전처리
def preprocess ( img ) :
"""
이미지 정규화
"""
img = ( tf.cast ( img , "float32" ) - 127.5 ) / 127.5
return img
train = train_data. map (
lambda x , y : ( preprocess ( x ), tf.one_hot ( y , depth=CLASSES ))
)
# 훈련 세트에 있는 몇 개의 샘플 출력하기
train_sample = sample_batch ( train )
display ( train_sample , cmap= None )
이제 CGAN 모델을 구축해봅니다.
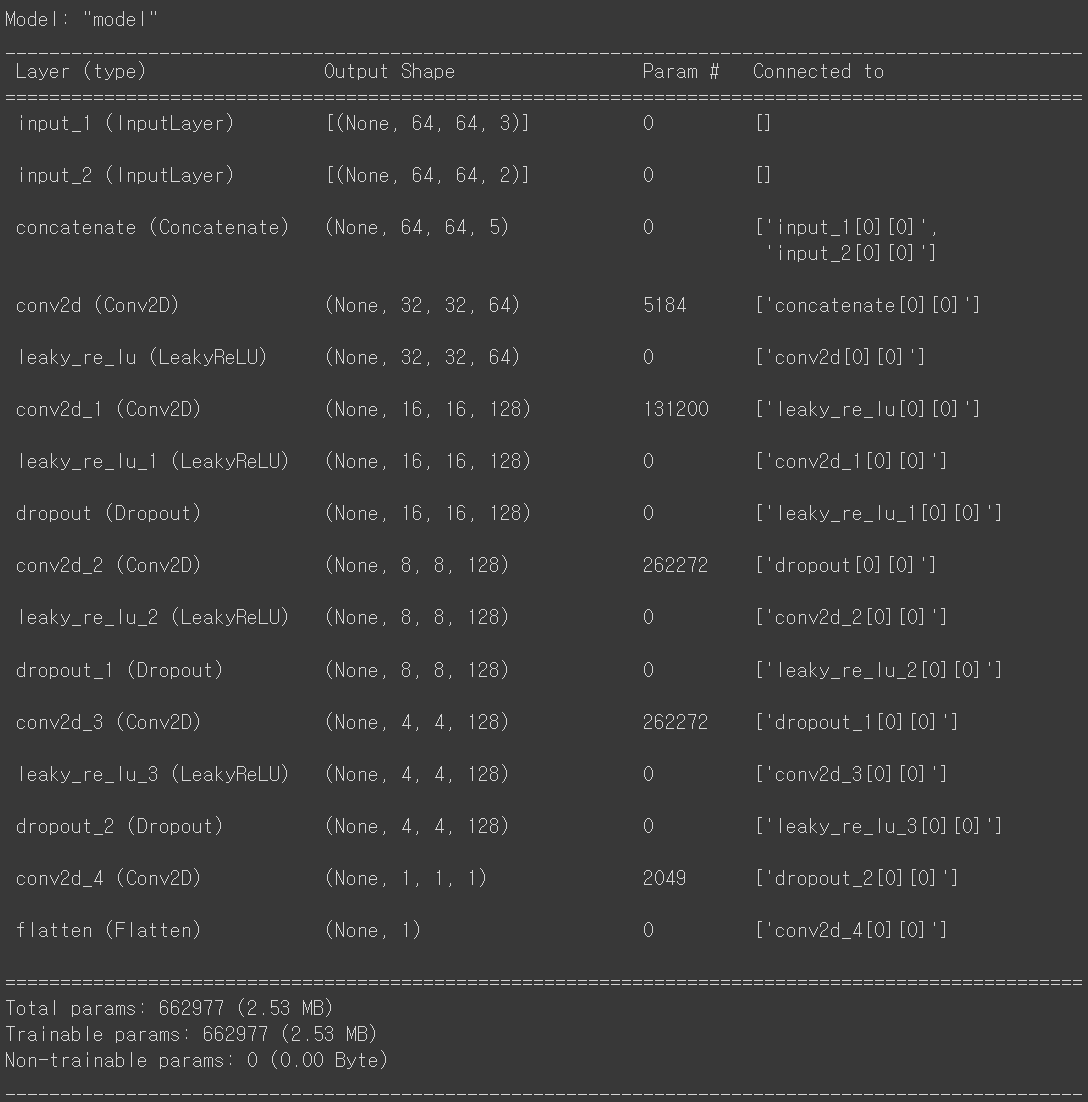
먼저 비평자(Crictic)입니다. WGAN-GP에서의 비평자 개념을 활용하여 더 안정적이고 잘 학습할 수 있도록 했습니다.
앞서 CGAN의 특징에 대해서 말씀드렸듯, 기존에 설명드린 GAN 모델과 비교했을때 label_input이 채널 단위로 추가된것을 확인할 수 있습니다.
critic_input = layers.Input ( shape= ( IMAGE_SIZE , IMAGE_SIZE , CHANNELS ))
label_input = layers.Input ( shape= ( IMAGE_SIZE , IMAGE_SIZE , CLASSES ))
x = layers.Concatenate ( axis= -1 )([ critic_input , label_input ])
x = layers.Conv2D ( 64 , kernel_size= 4 , strides= 2 , padding= "same" )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2D ( 128 , kernel_size= 4 , strides= 2 , padding= "same" )( x )
x = layers.LeakyReLU ()( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D ( 128 , kernel_size= 4 , strides= 2 , padding= "same" )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D ( 128 , kernel_size= 4 , strides= 2 , padding= "same" )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D ( 1 , kernel_size= 4 , strides= 1 , padding= "valid" )( x )
critic_output = layers.Flatten ()( x )
critic = models.Model ([ critic_input , label_input ], critic_output )
critic.summary ()
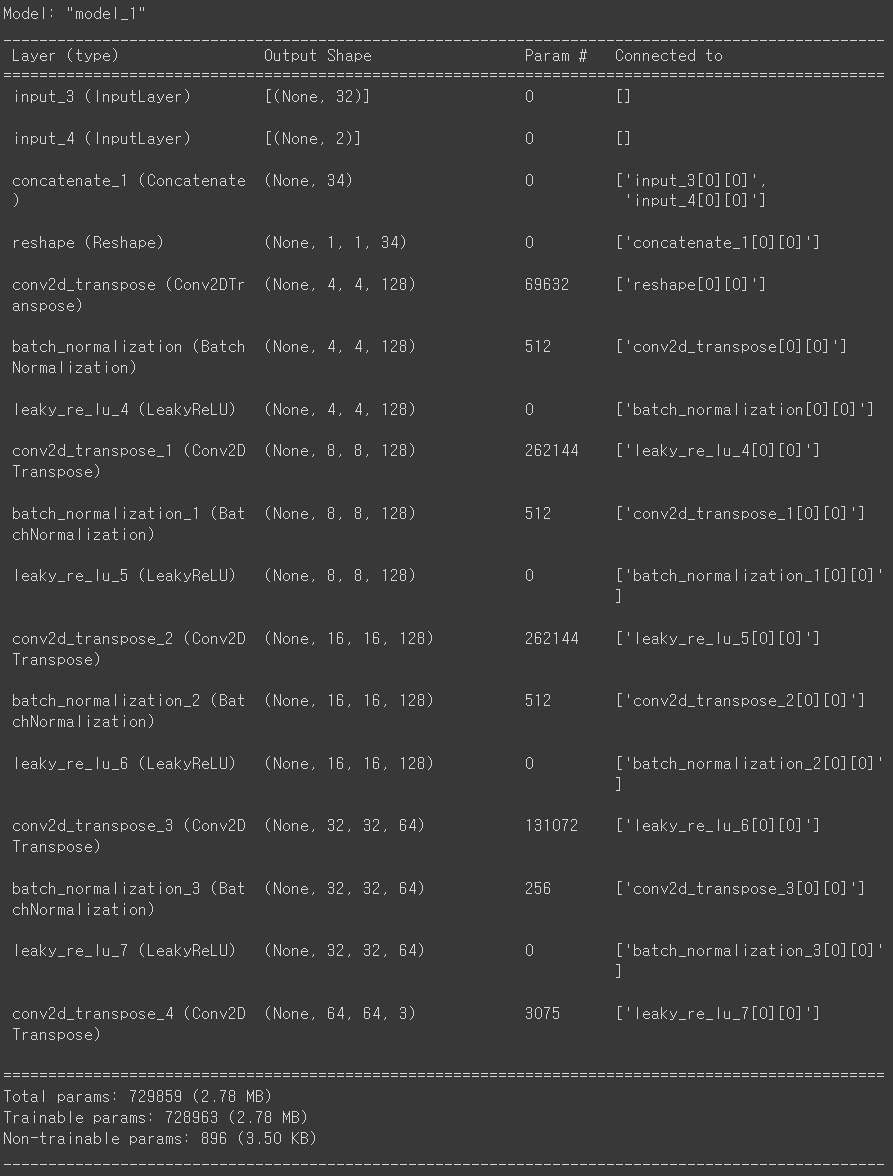
다음은 생성자 입니다.
생성자에도 label_input이 들어가며, 원핫 인코딩 된 레이블이 채널 단위로 추가됩니다.
generator_input = layers.Input ( shape= ( Z_DIM ,))
label_input = layers.Input ( shape= ( CLASSES ,))
x = layers.Concatenate ( axis= -1 )([ generator_input , label_input ])
x = layers.Reshape (( 1 , 1 , Z_DIM + CLASSES ))( x )
x = layers.Conv2DTranspose (
128 , kernel_size= 4 , strides= 1 , padding= "valid" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
128 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
128 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
64 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
generator_output = layers.Conv2DTranspose (
CHANNELS , kernel_size= 4 , strides= 2 , padding= "same" , activation= "tanh"
)( x )
generator = models.Model ([ generator_input , label_input ], generator_output )
generator.summary ()
이제 위에서 정의한 비평자와 생성자를 연결하여 최종적인 CGAN 모델을 정의하겠습니다.
이번에도 Gradient Penalty를 추가했으며, 이를 호출할 때 전달할 원핫 인코딩된 레이블 채널이 설정되도록 하였습니다.
class ConditionalWGAN ( models . Model ) :
def __init__ ( self , critic , generator , latent_dim , critic_steps , gp_weight ) :
super ( ConditionalWGAN , self ) . __init__ ()
self .critic = critic
self .generator = generator
self .latent_dim = latent_dim
self .critic_steps = critic_steps
self .gp_weight = gp_weight
def compile ( self , c_optimizer , g_optimizer ) :
super ( ConditionalWGAN , self ) . compile ( run_eagerly= True )
self .c_optimizer = c_optimizer
self .g_optimizer = g_optimizer
self .c_wass_loss_metric = metrics.Mean ( name= "c_wass_loss" )
self .c_gp_metric = metrics.Mean ( name= "c_gp" )
self .c_loss_metric = metrics.Mean ( name= "c_loss" )
self .g_loss_metric = metrics.Mean ( name= "g_loss" )
@property
def metrics ( self ) :
return [
self .c_loss_metric ,
self .c_wass_loss_metric ,
self .c_gp_metric ,
self .g_loss_metric ,
]
def gradient_penalty (
self , batch_size , real_images , fake_images , image_one_hot_labels
) :
alpha = tf.random.normal ([ batch_size , 1 , 1 , 1 ], 0.0 , 1.0 )
diff = fake_images - real_images
interpolated = real_images + alpha * diff
with tf.GradientTape () as gp_tape :
gp_tape.watch ( interpolated )
pred = self .critic (
[ interpolated , image_one_hot_labels ], training= True
)
grads = gp_tape.gradient ( pred , [ interpolated ])[ 0 ]
norm = tf.sqrt ( tf.reduce_sum ( tf.square ( grads ), axis= [ 1 , 2 , 3 ]))
gp = tf.reduce_mean (( norm - 1.0 ) ** 2 )
return gp
def train_step ( self , data ) :
real_images , one_hot_labels = data
image_one_hot_labels = one_hot_labels [:, None , None , :]
image_one_hot_labels = tf.repeat (
image_one_hot_labels , repeats=IMAGE_SIZE , axis= 1
)
image_one_hot_labels = tf.repeat (
image_one_hot_labels , repeats=IMAGE_SIZE , axis= 2
)
batch_size = tf.shape ( real_images )[ 0 ]
for i in range ( self .critic_steps ):
random_latent_vectors = tf.random.normal (
shape= ( batch_size , self .latent_dim )
)
with tf.GradientTape () as tape :
fake_images = self .generator (
[ random_latent_vectors , one_hot_labels ], training= True
)
fake_predictions = self .critic (
[ fake_images , image_one_hot_labels ], training= True
)
real_predictions = self .critic (
[ real_images , image_one_hot_labels ], training= True
)
c_wass_loss = tf.reduce_mean ( fake_predictions ) - tf.reduce_mean (
real_predictions
)
c_gp = self .gradient_penalty (
batch_size , real_images , fake_images , image_one_hot_labels
)
c_loss = c_wass_loss + c_gp * self .gp_weight
c_gradient = tape.gradient ( c_loss , self .critic.trainable_variables )
self .c_optimizer.apply_gradients (
zip ( c_gradient , self .critic.trainable_variables )
)
random_latent_vectors = tf.random.normal (
shape= ( batch_size , self .latent_dim )
)
with tf.GradientTape () as tape :
fake_images = self .generator (
[ random_latent_vectors , one_hot_labels ], training= True
)
fake_predictions = self .critic (
[ fake_images , image_one_hot_labels ], training= True
)
g_loss = -tf.reduce_mean ( fake_predictions )
gen_gradient = tape.gradient ( g_loss , self .generator.trainable_variables )
self .g_optimizer.apply_gradients (
zip ( gen_gradient , self .generator.trainable_variables )
)
self .c_loss_metric.update_state ( c_loss )
self .c_wass_loss_metric.update_state ( c_wass_loss )
self .c_gp_metric.update_state ( c_gp )
self .g_loss_metric.update_state ( g_loss )
return { m.name : m.result () for m in self .metrics }
이제 CGAN 모델을 인스턴스화 해줍니다.
# GAN 만들기
cgan = ConditionalWGAN (
critic=critic ,
generator=generator ,
latent_dim=Z_DIM ,
critic_steps=CRITIC_STEPS ,
gp_weight=GP_WEIGHT ,
)
이제 GAN 모델을 학습시켜줍니다.
# GAN 컴파일
cgan. compile (
c_optimizer=optimizers.Adam (
learning_rate=LEARNING_RATE , beta_1=ADAM_BETA_1 , beta_2=ADAM_BETA_2
),
g_optimizer=optimizers.Adam (
learning_rate=LEARNING_RATE , beta_1=ADAM_BETA_1 , beta_2=ADAM_BETA_2
),
)
이번에 활용할 레이블은 금발 여부 ([1,0] : 금발 아님 / [0,1] 금발 맞음) 입니다.
# 모델 저장 체크포인트 만들기
model_checkpoint_callback = callbacks.ModelCheckpoint (
filepath= "./checkpoint/checkpoint.ckpt" ,
save_weights_only= True ,
save_freq= "epoch" ,
verbose= 0 ,
)
tensorboard_callback = callbacks.TensorBoard ( log_dir= "./logs" )
class ImageGenerator ( callbacks . Callback ) :
def __init__ ( self , num_img , latent_dim ) :
self .num_img = num_img
self .latent_dim = latent_dim
def on_epoch_end ( self , epoch , logs = None ) :
random_latent_vectors = tf.random.normal (
shape= ( self .num_img , self .latent_dim )
)
# 0 레이블
zero_label = np.repeat ([[ 1 , 0 ]], self .num_img , axis= 0 )
generated_images = self .model.generator (
[ random_latent_vectors , zero_label ]
)
generated_images = generated_images * 127.5 + 127.5
generated_images = generated_images.numpy ()
if epoch % 100 == 0 : # 출력 횟수를 줄이기 위해
display (
generated_images ,
save_to= "./output/generated_img_%03d_label_0.png" % ( epoch ),
cmap= None ,
)
# 1 레이블
one_label = np.repeat ([[ 0 , 1 ]], self .num_img , axis= 0 )
generated_images = self .model.generator (
[ random_latent_vectors , one_label ]
)
generated_images = generated_images * 127.5 + 127.5
generated_images = generated_images.numpy ()
if epoch % 100 == 0 : # 출력 횟수를 줄이기 위해
display (
generated_images ,
save_to= "./output/generated_img_%03d_label_1.png" % ( epoch ),
cmap= None ,
)
history = cgan.fit (
train ,
epochs=EPOCHS * 100 ,
steps_per_epoch= 1 ,
callbacks= [
model_checkpoint_callback ,
tensorboard_callback ,
ImageGenerator ( num_img= 10 , latent_dim=Z_DIM ),
],
)
학습이 거듭될수록 점차 실제와 유사한 이미지가 나오게 됨을 알 수 있습니다.
이제 모델을 저장합니다.
# 최종 모델 저장
generator.save ( "./models/generator" )
critic.save ( "./models/critic" )
이를 활용해서 새로운 이미지를 생성해봅니다.
# 0 레이블
z_sample = np.random.normal ( size= ( 10 , Z_DIM ))
class_label = np.repeat ([[ 1 , 0 ]], 10 , axis= 0 )
imgs = cgan.generator.predict ([ z_sample , class_label ])
display ( imgs , cmap= None )
# 1 레이블
z_sample = np.random.normal ( size= ( 10 , Z_DIM ))
class_label = np.repeat ([[ 0 , 1 ]], 10 , axis= 0 )
imgs = cgan.generator.predict ([ z_sample , class_label ])
display ( imgs , cmap= None )











댓글