[해당 포스팅은 "만들면서 배우는 생성 AI 2탄"을 참조했습니다]
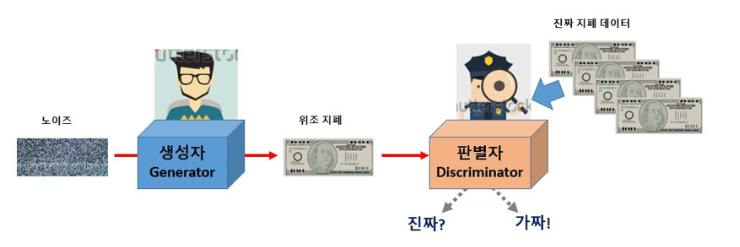
생성 AI (Generative AI)에서 유명한 모델 중 하나는 생성적 적대 신경망, GAN (Generatvie Adversarial Network) 입니다.
이는 Ian Goodfellow 등이 2014년 NeurIPS 라는 학회 (Neural Information Processing Systems)에서 발표한 논문인, Generative Adversarial Nets에서 시작하였습니다.
GAN은 생성자(Generative)와 판별자(Discriminator)라는 두 적대자의 싸움을 통한 생성을 해내는 네트워크가 되겠습니다.
생성자는 랜덤한 잡음을 원래 데이터셋에서 샘플링한 것처럼 보이는 샘플로 변환하고, 판별자는 샘플이 원래 데이터셋에서 나왔는지 아니면 생성자의 위조품인지를 에측하는 네트워크 입니다.
GAN은 이 두 네트워크의 훈련을 번갈아가며 진행하여, 생성자가 판별자를 속이는데 능숙해지면 판별자는 이에 적응해서 어떤 샘플이 가짜인지 정확하게 식별하게 되고 이에 따라 다시 생성자는 더 진짜 같은 것을 만들어 판별자를 속이려고 하는 과정이 반복되는 학습과정을 가지고 있습니다.
이 결과, 생성자는 진짜가 아니지만 진짜처럼 보이는 물체를 생성해내게 됩니다.
이러한 GAN을 발전시켜, 2015년 심층 합성곱 신경망(DCGAN, Deep Convolutional Generative Adversaril Network)이 나오게 됩니다. 해당 신경망에 대해서 코드를 통해서 알아보겠습니다.
먼저 해당 모델의 재현을 위해 필요한 util 파일을 받아줍니다.
import sys
# 코랩의 경우 깃허브 저장소로부터 utils.py를 다운로드 합니다.
if 'google.colab' in sys.modules :
! wget https://raw . githubusercontent . com/rickiepark/Generative_Deep_Learning_2nd_Edition/main/notebooks/utils . py
! mkdir -p notebooks
! mv utils . py notebooks
다음은 DCGAN 재현을 위해 필요한 라이브러리들을 임포트 해줍니다.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import (
layers ,
models ,
callbacks ,
losses ,
utils ,
metrics ,
optimizers ,
)
from notebooks.utils import display , sample_batch
이제 학습을 위해 사용할 하이퍼 파라미터들을 설정해줍니다.
IMAGE_SIZE = 64
CHANNELS = 1
BATCH_SIZE = 128
Z_DIM = 100
EPOCHS = 100 # 훈련이 오래 걸려 에포크 횟수를 300에서 100으로 줄입니다.
LOAD_MODEL = False
ADAM_BETA_1 = 0.5
ADAM_BETA_2 = 0.999
LEARNING_RATE = 0.0002
NOISE_PARAM = 0.1
데이터셋을 준비할 차례입니다. 아래 코드를 활용해서 웹에서 데이터를 다운로드하고 압축을 풀어줍니다.
# 코랩일 경우 노트북에서 celeba 데이터셋을 받습니다.
if 'google.colab' in sys.modules :
# # 캐글-->Setttings-->API-->Create New Token에서
# # kaggle.json 파일을 만들어 코랩에 업로드하세요.
# from google.colab import files
# files.upload()
# !mkdir ~/.kaggle
# !cp kaggle.json ~/.kaggle/
# !chmod 600 ~/.kaggle/kaggle.json
# # celeba 데이터셋을 다운로드하고 압축을 해제합니다.
# !kaggle datasets download -d joosthazelzet/lego-brick-images
#
# 캐글에서 다운로드가 안 될 경우 역자의 드라이브에서 다운로드할 수 있습니다.
import gdown
gdown.download ( id= '1qd50QDZtr_NYFiFVdp0sIvGDwTT3mMEQ' )
! unzip -q lego-brick-images . zip
# output 디렉토리를 만듭니다.
! mkdir output
이제 학습 데이터를 불러와줍니다.
train_data = utils.image_dataset_from_directory (
"./dataset/" ,
labels= None ,
color_mode= "grayscale" ,
image_size= ( IMAGE_SIZE , IMAGE_SIZE ),
batch_size=BATCH_SIZE ,
shuffle= True ,
seed= 42 ,
interpolation= "bilinear" ,
)
불러온 결과, 총 40,000개의 학습데이터가 있으며 전부 1개의 클래스에 속해있음을 알려줍니다.
다음은 학습을 용이하게 해주기 위해 정규화 및 이미지 크기 변경 진행해줍니다.
def preprocess ( img ) :
"""
이미지 정규화 및 크기 변경
"""
img = ( tf.cast ( img , "float32" ) - 127.5 ) / 127.5
return img
train = train_data. map ( lambda x : preprocess ( x ))
데이터로드 및 정규화, 크기 변경이 잘 진행되었는지 일부 데이터를 가져와서 확인해보겠습니다.
train_sample = sample_batch ( train )
위에서 처럼 데이터가 잘 로드 및 변환되었음을 확인할 수 있으며, 레고블록이 명암으로만 표현된 grayscale 이미지 임을 확인할 수 있습니다.
이제 합성곱 신경망을 활용해서 DC GAN 모델을 구축해보겠습니다.
먼저 판별자(Discriminator)부터 정의해보겠습니다.
discriminator_input = layers.Input ( shape= ( IMAGE_SIZE , IMAGE_SIZE , CHANNELS ))
x = layers.Conv2D ( 64 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False )(
discriminator_input
)
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D (
128 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D (
256 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D (
512 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Dropout ( 0.3 )( x )
x = layers.Conv2D (
1 ,
kernel_size= 4 ,
strides= 1 ,
padding= "valid" ,
use_bias= False ,
activation= "sigmoid" ,
)( x )
discriminator_output = layers.Flatten ()( x )
discriminator = models.Model ( discriminator_input , discriminator_output )
discriminator.summary ()
총 크게 3개의 블록을 거치고 있으며, 한개의 블록은 2D convolution -> Leaky ReLU -> Dropout 의 층이 반복되는 형태이며 블록은 진행될수록 더 크기를 작게 만들고 더 많은 채널을 활용해 더 고수준의 집약된 정보들을 많이 뽑아내고 있는 네트워크 입니다.
3개의 블록을 거친 뒤 마지막에는 1x1 크기의 1개의 채널을 가진 노드를 연결해줍니다. 이후 이 값을 flatten 하여 sigmoid function을 통해 0과 1사이의 숫자 하나를 출력해냅니다.
다음은 생성자 입니다.
생성자의 입력은 다변량 표준 정규분포에서 뽑은 벡터입니다. 출력은 원본 훈련 데어터에 있는 이미지와 동일한 크기의 이미지입니다.
GAN의 생성자 또한 VAE의 디코더 처럼 잠재 공간의 벡터를 이미지를 변환하는 목적을 수행합니다.
그래서 구조도 아래 코드처럼, 생성자의 반대 순서를 진행하고 있음을 알 수 있습니다.
generator_input = layers.Input ( shape= ( Z_DIM ,))
x = layers.Reshape (( 1 , 1 , Z_DIM ))( generator_input )
x = layers.Conv2DTranspose (
512 , kernel_size= 4 , strides= 1 , padding= "valid" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
256 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
128 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
x = layers.Conv2DTranspose (
64 , kernel_size= 4 , strides= 2 , padding= "same" , use_bias= False
)( x )
x = layers.BatchNormalization ( momentum= 0.9 )( x )
x = layers.LeakyReLU ( 0.2 )( x )
generator_output = layers.Conv2DTranspose (
CHANNELS ,
kernel_size= 4 ,
strides= 2 ,
padding= "same" ,
use_bias= False ,
activation= "tanh" ,
)( x )
generator = models.Model ( generator_input , generator_output )
generator.summary ()
먼저, 생성자의 Input 층(길이가 100인 벡터)를 정의합니다.
이후, Reshape 층을 사용해 1x1x100 크기의 텐서로 바꾸고, Transpose Conv2d를 활용해 채널수는 줄여가고 이미지의 크기는 점차 원본 이미지 크기처럼 키워갑니다.
마지막 Conv2DTranspose 층은 tanh(하이퍼탄젠트 함수)를 활성화 함수로 사용해 출력을 원본 이미지 도메인과 같은 [-1, 1] 범위로 변환합니다.
자, 이제 위에서 정의한 두 생성자와 판별자 네트워크를 이용해서 최종적인 DCGAN 함수를 정의해줍니다.
class DCGAN ( models . Model ) :
def __init__ ( self , discriminator , generator , latent_dim ) :
super ( DCGAN , self ) . __init__ ()
self .discriminator = discriminator
self .generator = generator
self .latent_dim = latent_dim
def compile ( self , d_optimizer , g_optimizer ) :
super ( DCGAN , self ) . compile ()
self .loss_fn = losses.BinaryCrossentropy ()
self .d_optimizer = d_optimizer
self .g_optimizer = g_optimizer
self .d_loss_metric = metrics.Mean ( name= "d_loss" )
self .d_real_acc_metric = metrics.BinaryAccuracy ( name= "d_real_acc" )
self .d_fake_acc_metric = metrics.BinaryAccuracy ( name= "d_fake_acc" )
self .d_acc_metric = metrics.BinaryAccuracy ( name= "d_acc" )
self .g_loss_metric = metrics.Mean ( name= "g_loss" )
self .g_acc_metric = metrics.BinaryAccuracy ( name= "g_acc" )
@property
def metrics ( self ) :
return [
self .d_loss_metric ,
self .d_real_acc_metric ,
self .d_fake_acc_metric ,
self .d_acc_metric ,
self .g_loss_metric ,
self .g_acc_metric ,
]
def train_step ( self , real_images ) :
# 잠재 공간에서 랜덤 포인트 샘플링
batch_size = tf.shape ( real_images )[ 0 ]
random_latent_vectors = tf.random.normal (
shape= ( batch_size , self .latent_dim )
)
# 가짜 이미지로 판별자 훈련하기
with tf.GradientTape () as gen_tape , tf.GradientTape () as disc_tape :
generated_images = self .generator (
random_latent_vectors , training= True
)
real_predictions = self .discriminator ( real_images , training= True )
fake_predictions = self .discriminator (
generated_images , training= True
)
real_labels = tf.ones_like ( real_predictions )
real_noisy_labels = real_labels + NOISE_PARAM * tf.random.uniform (
tf.shape ( real_predictions )
)
fake_labels = tf.zeros_like ( fake_predictions )
fake_noisy_labels = fake_labels - NOISE_PARAM * tf.random.uniform (
tf.shape ( fake_predictions )
)
d_real_loss = self .loss_fn ( real_noisy_labels , real_predictions )
d_fake_loss = self .loss_fn ( fake_noisy_labels , fake_predictions )
d_loss = ( d_real_loss + d_fake_loss ) / 2.0
g_loss = self .loss_fn ( real_labels , fake_predictions )
gradients_of_discriminator = disc_tape.gradient (
d_loss , self .discriminator.trainable_variables
)
gradients_of_generator = gen_tape.gradient (
g_loss , self .generator.trainable_variables
)
self .d_optimizer.apply_gradients (
zip ( gradients_of_discriminator , discriminator.trainable_variables )
)
self .g_optimizer.apply_gradients (
zip ( gradients_of_generator , generator.trainable_variables )
)
# 메트릭 업데이트
self .d_loss_metric.update_state ( d_loss )
self .d_real_acc_metric.update_state ( real_labels , real_predictions )
self .d_fake_acc_metric.update_state ( fake_labels , fake_predictions )
self .d_acc_metric.update_state (
[ real_labels , fake_labels ], [ real_predictions , fake_predictions ]
)
self .g_loss_metric.update_state ( g_loss )
self .g_acc_metric.update_state ( real_labels , fake_predictions )
return { m.name : m.result () for m in self .metrics }
이때 중요한 것은 생성자와 판별자의 네트워크의 가중치 업데이트가 번갈아가며 이루어지도록 훈련 또한 번갈아서 진행을 해야합니다. 가중치가 한번에 업데이트 되어버린다면, 생성자가 생성한 덜 성숙한 이미지가 판별자가 진짜라고 믿어버리도록 강제하는 효과를 가지고 있기 때문입니다.
자 이렇게 정의된 모델을 인스턴스화 해줍니다.
# DCGAN 생성
dcgan = DCGAN (
discriminator=discriminator , generator=generator , latent_dim=Z_DIM
)
그리고 체크포인트 또한 지정해줍니다.
if LOAD_MODEL :
dcgan.load_weights ( "./checkpoint/checkpoint.ckpt" )
이제 모델을 컴파일 해줍니다. 이때 생성자와 판별자 각각에 대한 옵티마이저를 정의해줍니다.
dcgan. compile (
d_optimizer=optimizers.Adam (
learning_rate=LEARNING_RATE , beta_1=ADAM_BETA_1 , beta_2=ADAM_BETA_2
),
g_optimizer=optimizers.Adam (
learning_rate=LEARNING_RATE , beta_1=ADAM_BETA_1 , beta_2=ADAM_BETA_2
),
)
이제 최종적으로 모델 저장 체크포인트를 만들어줍니다.
# 모델 저장 체크포인트 만들기
model_checkpoint_callback = callbacks.ModelCheckpoint (
filepath= "./checkpoint/checkpoint.ckpt" ,
save_weights_only= True ,
save_freq= "epoch" ,
verbose= 0 ,
)
tensorboard_callback = callbacks.TensorBoard ( log_dir= "./logs" )
class ImageGenerator ( callbacks . Callback ) :
def __init__ ( self , num_img , latent_dim ) :
self .num_img = num_img
self .latent_dim = latent_dim
def on_epoch_end ( self , epoch , logs = None ) :
if epoch % 10 == 0 : # 출력 횟수를 줄이기 위해
random_latent_vectors = tf.random.normal (
shape= ( self .num_img , self .latent_dim )
)
generated_images = self .model.generator ( random_latent_vectors )
generated_images = generated_images * 127.5 + 127.5
generated_images = generated_images.numpy ()
display (
generated_images ,
save_to= "./output/generated_img_%03d.png" % ( epoch ),
)
그리고 이제 피팅을 해서 학습을 진행합니다.
dcgan.fit (
train ,
epochs=EPOCHS ,
callbacks= [
model_checkpoint_callback ,
tensorboard_callback ,
ImageGenerator ( num_img= 10 , latent_dim=Z_DIM ),
],
)
첫번째 에포크의 결과는 아래와 같습니다.
다음은 10번째, 20번째 에포크의 결과이며, 점점 레고의 형상을 생성해감을 알 수 있습니다.
학습이 완료되니 아래와 같이 꽤나 실제 이미지와 유사한 결과가 나오게 됩니다.
이제 최종모델을 저장해줍니다.
# 최종 모델 저장
generator.save ( "./models/generator" )
discriminator.save ( "./models/discriminator" )
다음은 이렇게 학습된 생성자를 가지고 새로운 이미지를 만들어보겠습니다.
인풋 값은 표준정규 분포에서 잠재 공간의 일부 포인트를 샘플링한 것이 되겠습니다.
# 표준 정규 분포에서 잠재 공간의 일부 포인트를 샘플링합니다.
grid_width , grid_height = ( 10 , 3 )
z_sample = np.random.normal ( size= ( grid_width * grid_height , Z_DIM ))
# 샘플링된 포인트 디코딩
reconstructions = generator.predict ( z_sample )
# 디코딩된 이미지 그리기
fig = plt.figure ( figsize= ( 18 , 5 ))
fig.subplots_adjust ( hspace= 0.4 , wspace= 0.4 )
# 얼굴 그리드 출력
for i in range ( grid_width * grid_height ):
ax = fig.add_subplot ( grid_height , grid_width , i + 1 )
ax.axis ( "off" )
ax.imshow ( reconstructions [ i , :, :], cmap= "Greys" )
꽤나 그럴싸한 이미지들이 나오게 되었습니다. 하지만 레고 블록이라는 것을 보았을때는 만족 스럽지는 못한 결과인데요
성공적인 생성 모델에 필요한 조건 인 훈련 세트에서 이미지를 단순히 재생성해서는 안된다는 것을 확인하기 위해 다음 과정을 진행해보겠습니다.
생성된 특정 샘플에 가장 비슷한 훈련 세트의 이미지를 찾아 이를 테스트해보는 것입니다. 이때 두 이미지의 비슷함을 확인하기 위해 L1-norm을 사용하겠습니다
def compare_images ( img1 , img2 ) :
return np.mean ( np. abs ( img1 - img2 ))
all_data = []
for i in train.as_numpy_iterator ():
all_data.extend ( i )
all_data = np.array ( all_data )
r , c = 3 , 5
fig , axs = plt.subplots ( r , c , figsize= ( 10 , 6 ))
fig.suptitle ( "Generated images" , fontsize= 20 )
noise = np.random.normal ( size= ( r * c , Z_DIM ))
gen_imgs = generator.predict ( noise )
cnt = 0
for i in range ( r ):
for j in range ( c ):
axs [ i , j ] .imshow ( gen_imgs [ cnt ], cmap= "gray_r" )
axs [ i , j ] .axis ( "off" )
cnt += 1
plt.show ()
fig , axs = plt.subplots ( r , c , figsize= ( 10 , 6 ))
fig.suptitle ( "Closest images in the training set" , fontsize= 20 )
cnt = 0
for i in range ( r ):
for j in range ( c ):
c_diff = 99999
c_img = None
for k_idx , k in enumerate ( all_data ):
diff = compare_images ( gen_imgs [ cnt ], k )
if diff < c_diff :
c_img = np.copy ( k )
c_diff = diff
axs [ i , j ] .imshow ( c_img , cmap= "gray_r" )
axs [ i , j ] .axis ( "off" )
cnt += 1
plt.show ()
위 두 결과를 비교해보면 생성된 이미지가 훈련 세트의 이미지와 비슷하긴 하지만 동일하지 않음을 알 수 있습니다.








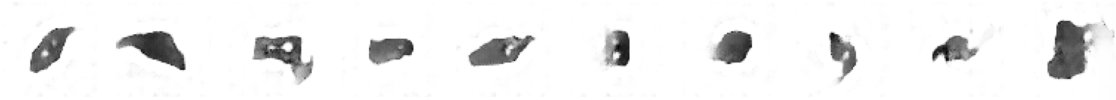








댓글