
이번에는 자기지도학습(Self-Supervised Learning, SSL)의 방법 중
대조학습(Contrastive Learning)에 대해서 알아보고자 합니다.
1. 대조학습(Contrastive Learning)이란?
- 대조학습은 유사한 데이터(Positive Sample)는 가깝게, 다른 데이터(Negative Sample)는 멀어지도록 학습하는 방법을 말합니다.
- 대조학습의 핵심 원리는
1) 데이터 증강(Augmentation)을 통해서 Positive / Negative Pair를 생성
* 하나의 이미지를 다양한 변형(Crop, Rotation, Color Jittering 등)하여 Positive Pair를 생성해줍니다.
* 서로 다른 이미지는 Negative Pair로 설정합니다.
2) Encodeer를 활용한 표현 학습
* CNN, Transformer 등 학습시키고자하는 Encoder를 통해 데이터의 특징을 잘 추출할 수 있도록 학습을 시킵니다.
3) Contrastive Loss 계산
* NCE, InfoNCE를 사용할 수 있습니다.
Contrastive Learning 기초 : EBM, NCE, InfoNCE
* 또는 NT-Xent Loss(Normalized Temperature-scaled Cross Entropy Loss)를 사용합니다.

(Info NCE와 유사하지만, Batch내에서 2N개의 샘플을 사용하며, 분모의 합을 계산할 때 자기 자신을 제외한 모든 샘플(2N-1개)와 비교)
* 이는 학습 목표가 되어 설정된 Positive pair 끼리는 가까워지도록, Negative pair 끼리는 멀어지도록 해줍니다.
2. 대조학습을 활용한 대표적인 논문
1) SimCLR ( A Simple Framework for Contrastive Learning of Visual Representations, Chen et al. 2020)
- SimCLR는 대조학습을 가장 직관적이고 효과적으로 구현한 방법 중 하나로, CNN을 활용한 Representation Learning에서 기본적인 표준 모델입니다.
- 핵심 아이디어는 아래와 같습니다.

1) 데이터 증강 : 하나의 이미지를 두 개의 랜덤한 변형으로 변환
2) CNN 기반의 Encoder를 활용
* 위 그림에서 Encoder는 f 입니다.
3) Projection head 추가(MLP를 사용해 Feature Embedding 공간을 조정)
* 위 그림에서 Projection head는 g 입니다.
* 이때 Projection head는 인코더를 통해 학습된 표현이 적절한 Embedding Space에 투영되도록 하는데요. 이 이유는 Contrastive Learning을 위한 공간(Projection head가 학습)과 실제 다운 스트림 task에 사용할 Represenation Space(Encoder가 학습)을 분리하는 것입니다.
* 만일 Projection head가 없다면, 학습해야 될 Encoder가 Contrastive Loss를 최소화하는 방향으로 학습이 이루어지게 되어 보다 SSL의 목적인 풍부한 Representation을 학습하는 것보다는 Contrastive Loss를 최소화하는 것에만 초점이 될 수 있끼 때문입니다.
4) Contrastive Loss 적용 : NT-Xent Loss를 활용
SimCLR은 Vision Task에 Contrastive Learning을 적용한 것으로 Positive Set을 만들기 위한 Augmentation으로 아래와 같은 방법들을 활용했습니다.

2) MoCo ( Momentum Contrast for Unsupervised Visual Representation Learning, He et al., 2020)
- MoCo는 Contrastive Learning에서 Negative Sample을 효과적으로 활용하기 위해 Queue 기반 Memory Bank를 도입한 모델입니다.
- 핵심 아이디어는 아래와 같습니다.
1) 2개의 Encoder 사용 (Query Encoder, Key Encoder)
2) Momentum Update Mechanism 도입
* Quenry Encoder는 일반적인 CNN구조
* Key Encoder는 Momentum Update 방식으로 가중치가 조금씩 업데이트
3) Negative Sample을 저장하는 Dynamic Queue 사용
* 기존 Contrastive Learning을 Batch 내에서 존재하는 Negative sample만을 학습에 활용했지만, Memory Bank에 Negative Sample의 정보를 저장해 이를 활용함으로서 Batch가 크지 않아도 많은 Negative Sample과의 대조를 할 수 있게 됨
- MoCo의 핵심 아이디어를 그림으로 표현하면 아래와 같은데요
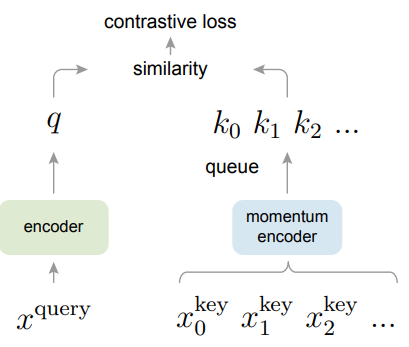
* 원본 이미지 x가 주어지면, 두개의 Augmentation을 생성하는데 하나는 Query sample, 다른 하나는 Key sample입니다.
* Query Sample은 Query Encoder에 입력되어 q라는 Feature vector를 만들고
* Key Sample은 Momentum Encoder에 입력되어 k라는 Feature vector를 만듭니다.
* 이 Momentum Encoder의 출력은 queue인 Memorybank에 저장하여 Negative Sample들로 역할을 하게 되는 것입니다.
(Augment 되기 전 원본과는 Positive의 관계이겠지만, 그 이후 다른 샘플들과는 Negative의 관계가 되는 것입니다)
* 그리고, 이 q와 k의 유사도를 비교하여 Contrastive Loss를 계산하는 것입니다.
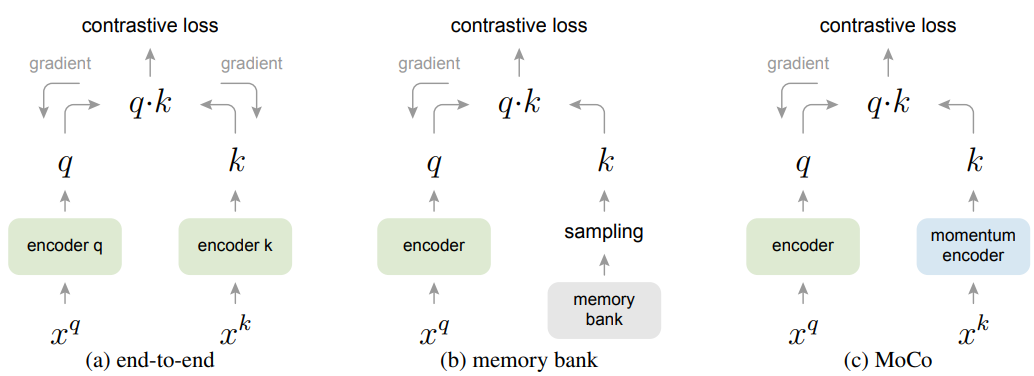
- MoCo는 기존 Contrastive Learning 방식들과 차이점이 있는데요
1) End to End 방식과의 차이 : MoCo는 Key Encoder의 가중치를 Gradient 기반으로 업데이트 하지 않고, Momentum Update를 사용해 부드럽게 조정
2) Memory Bank 방식과의 차이 : MoCo는 사전에 많은 Negative Sample을 저장할 필요 없이, Queue를 활용해 동적으로 Negative Sample을 관리
- 이때 moemntum encoder인 k는 다음과 같이 EMA방식으로 가중치가 부드럽게 업데이트가 됩니다.

* EMA를 통해 Key Encoder를 업데이트할 경우, Key 인코더가 데이터의 변화에 따라 급격하게 변하지 않고 어느정도의 일관성을 유지할 수 있으며
* Query인 q와 Key인 k가 너무 유사해질 수 있는 문제를 방지하고 더 일반적인 Representation을 얻을 수 있게 됩니다.
- MoCo는 일반적인 InfoNCE Loss를 사용합니다.

- 이를 통해 MoCo는
1) 메모리 효율적인 대조학습이 가능하며
2) Batch size에 SimCLR보다 덜 의존적인 학습을 할 수 있고
3) 이를 바탕으로 대규모 데이터셋에도 잘 작동합니다.
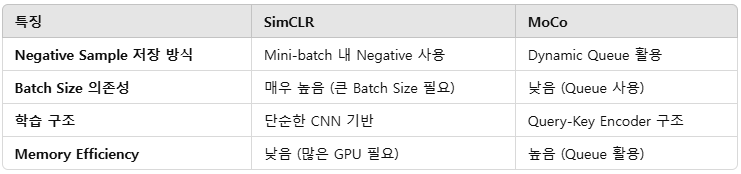
3) SimCLR과 MoCo 비교
-먼저, 두 방법론을 비교해서 정리해보면 다음과 같습니다.
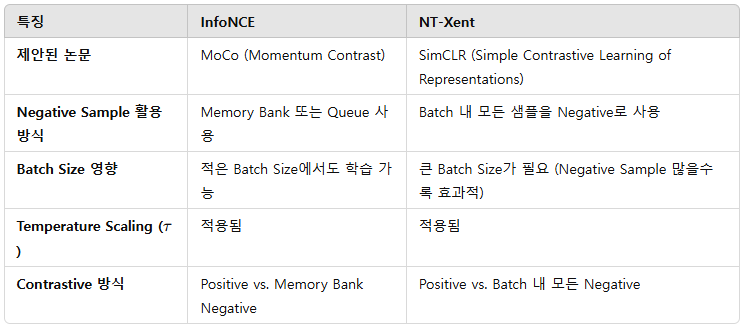
- 또한, 각각의 방법론이 사용하는 Loss인 InfoNCE(MoCO가 사용), NT-Xent(SimCLR)을 비교해보면 내용은 아래 표와 같습니다.




댓글