
이번에는 지난 시간에 알아본 "Credit Card Fraud Detection" 데이터를 활용해서 불균형 클래스 분류 문제에서 활용되는 평가지표 들에 대해서 알아보겠습니다.
[머신러닝 with Python] 불균형 데이터 처리(1) : Credit Card Fraud Detection Data에 대해 EDA
1. 불균형 클래스 분류 문제에 활용되는 평가지표들
- 불균형 클래스 문제에서는 단순한 Accuracy는 신뢰할 수 없는 평가지표가 됩니다. 지난 시간에 알아봤던 Credit Card Fraude Detection 데이터에서도 사기 탐지 거래 비율이 겨우 0.172% 밖에 안되기에 아무런 로직없이 단지 "정상" 이라고 내뱉는 Dummy Classifier를 만들어도 Accuracy는 99.8%가 넘게 되어 모델의 성능을 평가하기에 제한됩니다.
- 이에 따라 다음과 같은 평가 지표들을 많이 활용하는데요
1) Precision(정밀도) 과 Recall(재현율), 그리고 F1 score
* Precision은 모델이 긍정 클래스를 예측한 것 중 실제로 긍정 클래스인 비율을 의미합니다.
* Recall은 실제 긍정 클래스 중에서 모델이 올바르게 예측한 비율을 말합니다. 사기 탐지와 같이 긍정 클래스 탐지가 중요한 경우, 재현율이 중요한 역할을 합니다.
*F1 score : Precision과 Recall의 조화 평균으로, 두 지표 간 균형을 평가하며 Precision과 Recall 중 어느 한쪽 개념에 치우치지 않은 지표이기에 가장 많이 활용됩니다.
2) AUROC
* Area Under the Receiver Operating Characteristic Curve의 줄임말로, ROC의 곡선의 아래 면적을 나타내는 값을 말합니다.
* ROC 곡선은 거짓 양성비율(False Positive Rate, FPR)과 참 양성 비율(True Positive Rate, TPR)간의 관계를 그래프로 표현하는 것으로
FPR은 실제 음성인 데이터를 양성으로 잘못 예측한 비율을 뜻하고, TPR은 실제 양성 데이터를 정확히 양성으로 예측함 비율로 Recall과 동일한 개념입니다.
* 이런 ROC 곡선은 모델이 여러 임계값(모델의 최종 예측이 0~1사이의 확률값으로 나오게 되는데 이때 어떤 임계값을 적용하여 특정 값보다 작으면 음성, 특정값보다 크면 양성으로 분류)에 따라 FPR과 TPR이 어떻게 변하는지를 보여줍니다. 이에 대한 예시는 아래와 같습니다.
* 이를 해석해보면
a) AUROC가 1에 가까울 경우, 모든 양성 샘플을 양성으로 모든 음성 샘플을 음성으로 분류하기에 가장 이상적인 완벽한 분류모델이라고 볼 수 있고
b) AUROC가 0.5에 가까울 경우, 임의로 예측하는 모델과 비슷한 성능을 가졌다고 볼 수 있습니다.
즉, 값이 클수록 모델이 양성 클래스와 음성 클래스를 잘 구분한다고 볼 수 있습니다.
* 하지만, 불균형 데이터에서는 성능을 왜곡할 수도 있는데, 특히 음성 클래스가 압도적으로 많은 경우 FPR이 낮게 유지되므로 ROC 곡선이 우상향으로 나타나지만 이는 실제로 좋은 모델이라고 단정할 수 는 없기에 다른 평가지표가 추가적으로 필요합니다.
3) AUPRC
* Area Under the Precision Recall Curve의 줄임말로, 정밀도-재현율 곡선의 아래 면적을 나타냅니다.
* 불균형 데이터에서 모델의 성능을 평가하는데 특히 유용한 평가지표인데, 양성 클래스가 적은 경우에 다른 평가지표들보다 더 신뢰할 수 있는 평가지표입니다.
* Precision Recall Curve는 임계값을 변화시켜 Precision과 Recall간의 관계를 시각화 해주며 예시는 아래와 같습니다.
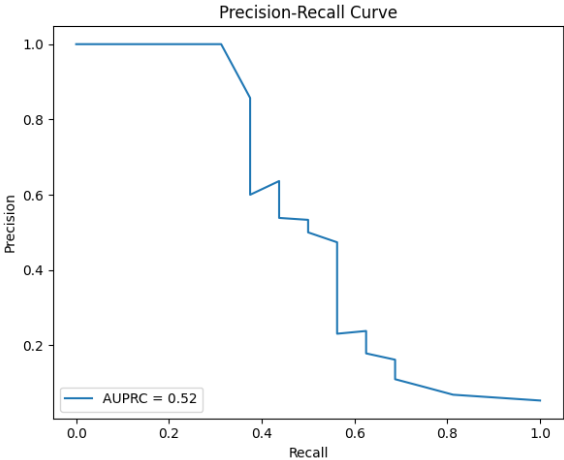
* 이를 해석해보면
a) AUPRC가 높을 경우, 모델이 양성 클래스에서 높은 정밀도와 재현율을 유지하고 있음을 의미합니다.
b) AUPRC가 낮을 경우, 모델이 양성 클래스 탐지에서 성능이 낮으며, 특히 불균형 데이터에서 중요한 양성 샘플을 잘 잡아내지 못하고 있음을 의미합니다.
4) MCC
* Matthews Correlation Coefficient의 줄임말로, 모든 예측결과를 종합해 모델 성능을 평가할 수 있는 지표로 수식은 아래와 같습니다.
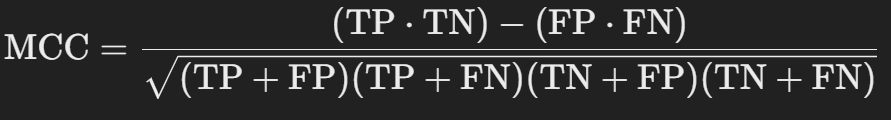
* 이는 -1과 1 사이의 값을 가지며, 1에 가까울수록 완벽한 예측을 의미하고 0에 가까우면 무작위 예측과 유사한 성능을 의미합니다.
* 이는, 모든 유형의 오류(TP부터 FN까지)를 고려해 평가에 반영하며, 한쪽 클래스가 압도적으로 많은 상황에서도 데이터의 불균형을 반영하여 평가할 수 있기에 불균형 데이터 분류문제에서 유용한 평가지표로 활용됩니다.
5) Cohen's Kappa
* 카파 통계량이라고도 불리며, 모델의 예측 성능을 무작위 예측 대비 얼마나 개선했는지를 나타내주고 -1에서 1사이의 값을 가집니다.
* 1에 가까울수록 완벽한 예측을, 0은 무작위 예측을 의미하고 수식은 아래와 같습니다.
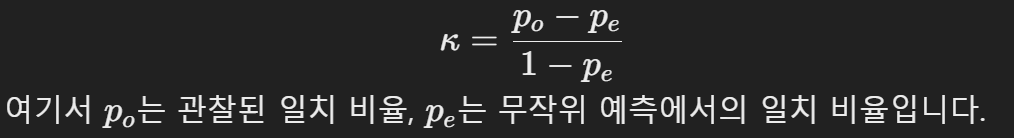
* 카파는 모델의 예측 성능을 평가할 때, 기대되는 정확도(무작위로 예측할 경우의 정확도)를 고려합니다. 이로 인해 단순히 음성 클래스가 많은 상황에서 무작위로 음성을 예측하여 높은 정확도를 얻는 것처럼 보이는 모델도 실제 카파값은 낮게 나올 수 있기에 불균형 데이터 분류 문제에서 유용한 평가지표로 활용됩니다.
2. 분류 모델을 활용한 데이터 분류
- 이번에는 본격적인 불균형 데이터 처리를 하기 전에 앞서 알아본 평가지표들을 활용해 Baseline 성능을 알아보기 위해 LASSO 및 XGBoost를 가지고 모델링을 해보겠습니다.
- 먼저 필요한 라이브러리를 임포트 해줍니다
- 다음 데이터를 불러와줍니다.
- 이제 데이터를 Train/Test로 분리하고, 모델은 XGBoost모델을 활용하여 5 fold CV를 진행해줍니다.
(XGBoost는 학습속도가 상대적으로 빠르고 성능도 우수하기 때문에 분석의 Baseline으로 많이 활용합니다.)

* 결과는 위와 같이 나왔습니다.
* 이 결과를 바탕으로 다음 포스팅들에서는, 불균형 데이터 처리 방법을 적용한 다양한 모델들과의 결과 비교에 활용해보도록 하겠습니다.
'머신러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] Kernel PCA란? (0) | 2024.11.24 |
|---|---|
| [머신러닝 with Python] 불균형 데이터 처리(3) : TomekLink활용 (0) | 2024.11.23 |
| [머신러닝 with Python] 불균형 데이터 처리(1) : Credit Card Fraud Detection Data에 대해 EDA (1) | 2024.11.20 |
| [머신러닝 with Python] t-SNE란? (차원축소, 시각화) (0) | 2024.07.08 |
| [머신러닝 with Python] 상점 신용카드 매출 예측 (DACON 문제) (2/2) (0) | 2024.06.11 |




댓글