
이번에는 불균형 데이터 처리에 대표적으로 사용되는 데이터 셋인
Credit Card Fraud Detection Data에 대해서 알아보겠습니다.
1. Credit Card Fraud Detection
- 해당 데이터셋은 유럽의 신용카드 소지자들이 2013년 9월 동안 사용한 거래 데이터를 포함하고 있으며, 신용카드 사기 탐지를 위한 머신러닝 모델 학습에 적합하게 설계되어 있는 데이터 입니다.
- 데이터 정보 요약
* 기간 : 2일 동안 발생한 거래 데이터
* 사기 거래 건수 : 492건 (전체 284,807건 중 약 0.172%)
* 데이터 불균형 : 사기 거래 비율이 0.172%에 불과해 데이터의 클래스가 매우 불균형한 분류 문제를 해결해야 합니다.
* 평가지표 : 클래스의 불균형성으로 인해 단순한 Accuracy 사용은 큰 의미가 없고, AUPRC 등을 사용하는 것이 좋습니다.
- 데이터 특성 요약
* 변수의 종류 : 모든 입력 변수는 수치형(Numeric) 데이터로, PCA(주성분 분석을 통해 변환된 결과입니다.
(원래의 피처와 데이터에 대한 추가 정보는 보안 문제로 공개되지 않았습니다)
[머신러닝 with 파이썬] PCA / 주성분 분석 / 차원축소 /iris 데이터 활용
[머신러닝 with 파이썬] PCA / 주성분 분석 / 차원축소 /iris 데이터 활용
이번에 알아볼 것은 차원축소 알고리즘의 대표적인 PCA(주성분 분석)에 대해서 알아보겠습니다. Tabular type의 데이터에서 차원을 축소한다는 것은 곧, 변수의 개수(또는 피처의 개수)를 줄인다는
jaylala.tistory.com
* 변수 설명
a) V1, V2, .... V28 : PCA로 생성된 주성분 변수들입니다.
b) Time : 각 거래가 데이터셋에서 최초 거래가 발생한 후 얼마나 시간이 경과했는지(초 단위)를 나타냅니다.
c) Amount : 거래 금액을 나타내며, 비용 민감학습(cost-senstive learning)에 활용할 수 있습니다.
d) Class : 사거 거래일 경우 1, 그렇지 않을 경우 0으로 설정됩니다.
2. 파이썬 코드를 활용한 EDA
- 이제 파이썬을 활용해서 직접 데이터 셋을 로드하고 어떤 형태인지 간단하게 EDA를 해보겠습니다.
* EDA는 Explarotory Data Anaylsis의 약자로 탐색적 데이터 분석이라고 불립니다. 데이터의 기본적인 특성과 구조를 파악하고, 데이터에 대한 이해를 높이기 위한 분석 단계를 말합니다.
- 먼저 데이터 셋을 불러오겠습니다. open_ml 라이브러리에 내재되어 있기에 편리하게 아래 코드를 통해서 불러오실 수 있습니다.
- 불러온 데이터의 형태가 위 설명과 일치하는지 info() 함수를 통해 확인해봅니다.
* 정보를 확인해보니 Time, V1 ~ V28, 그리고 Amount 라는 feature가 있는 것을 잘 확인할 수가 있고, Class 변수(Response로 활용)도 잘 있는 것을 알 수 있습니다.
* 결측치가 없으며, 총 284,807개의 관측치가 있는것을 알 수 있으며, 모두 float64 형태의 Numeric 값으로 되어 있는 것을 알 수 있습니다.
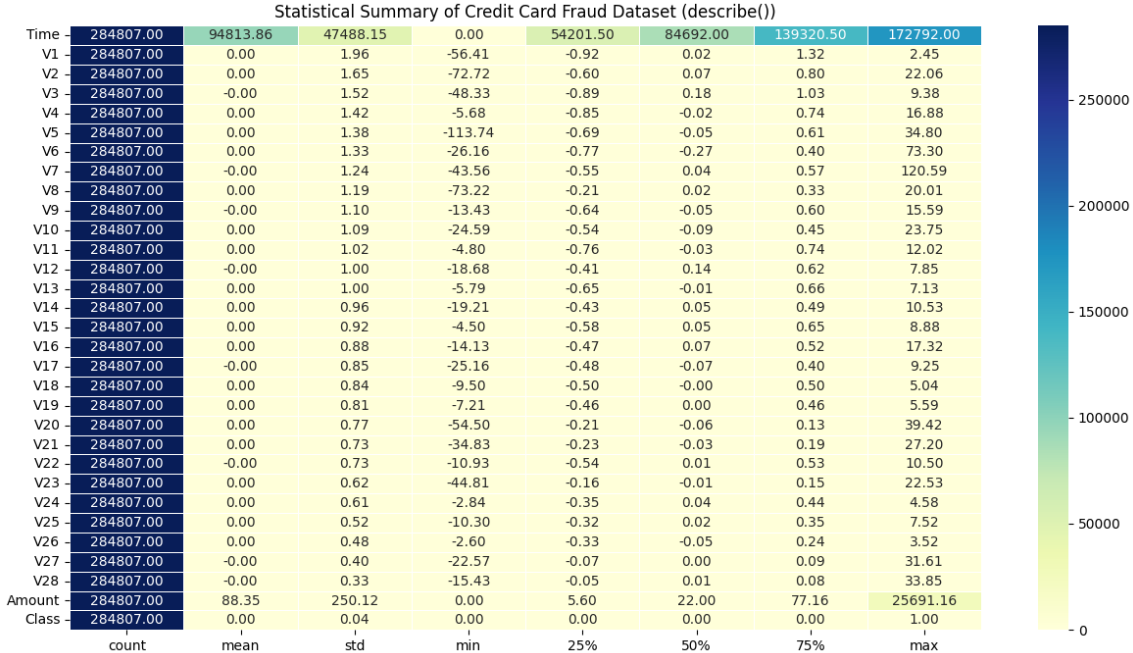
- 데이터의 통계 정보를 describe() 함수를 통해서 알아보겠습니다. describe 함수를 단순 활용하면 아래와 같이 정리가 잘되지만 정보가 한 눈에 들어오지는 않는 것 같습니다.
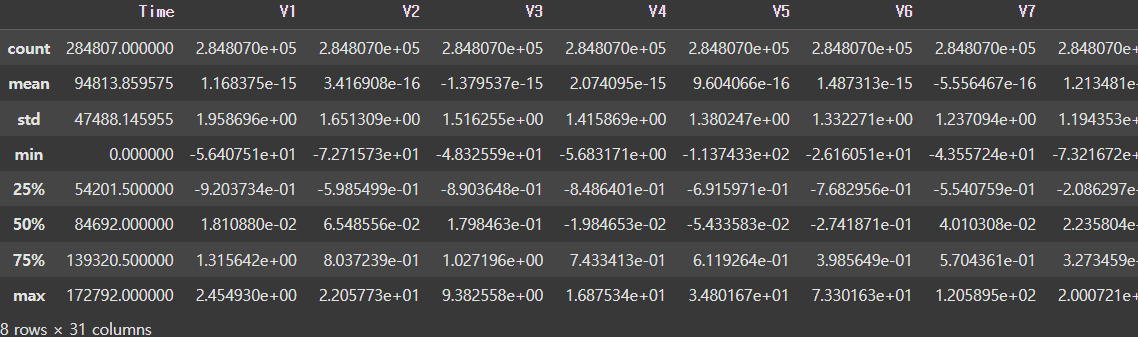
* heat map의 형태를 활용해서 깔끔하게 결과를 정리해보겠습니다. 한결 더 눈에 더 잘 들어옵니다.
- 이번에는 데이터의 불균형 정도에 대해서 확인해보겠습니다.
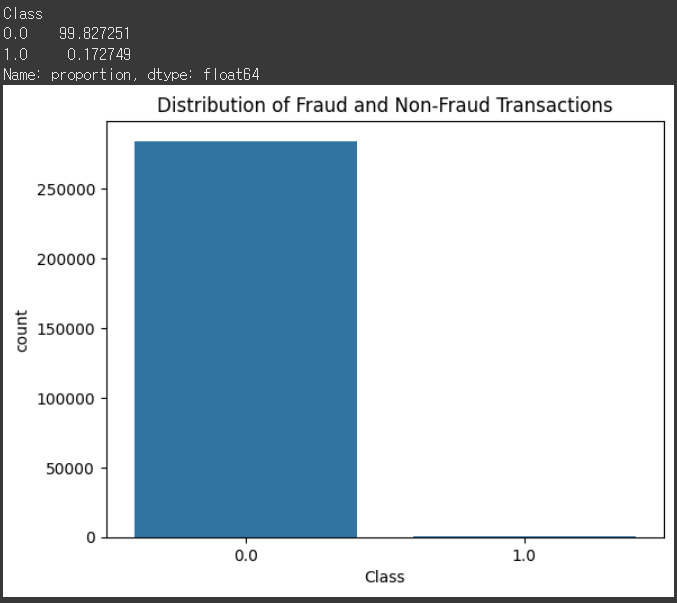
* 최초 설명에서 알아봤던 것처럼 사기 Class의 비율이 0.172% 인 것을 알 수 있습니다.
- 이번에는 주요 Feature들에 대한 히스토그램을 통해서 어떤 분포를 가지고 있는지 알아보겠습니다.
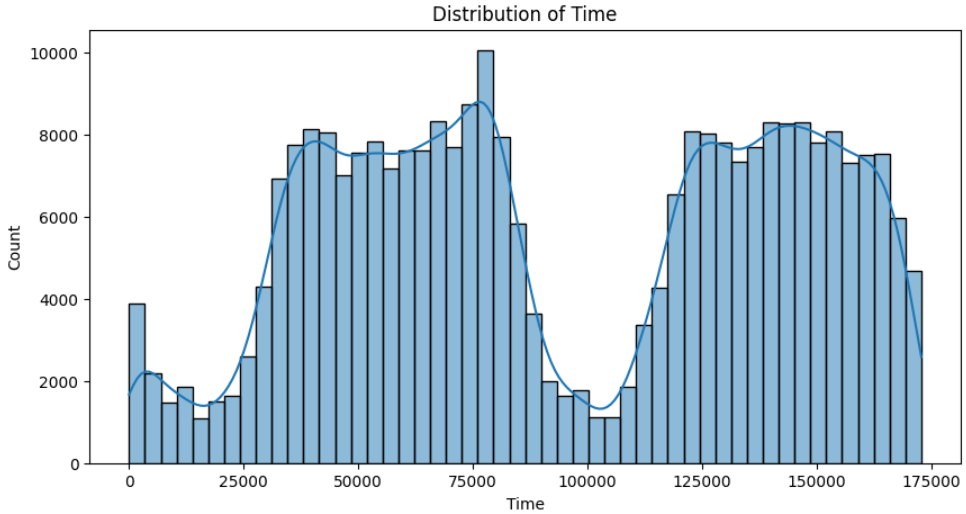
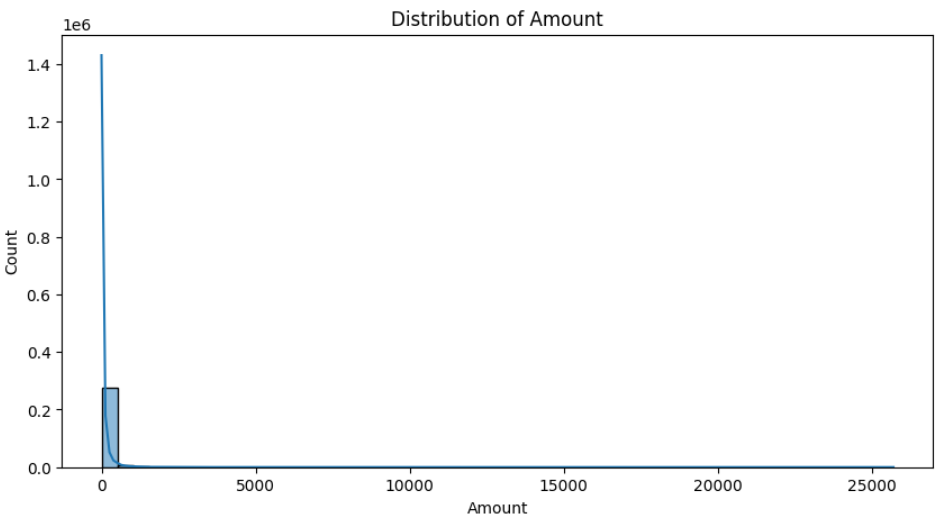
* 시간 분포는 상당히 다양함을 알 수 있으며, 거래 금액 분포는 낮은 금액대에 집중되어 있음을 알 수 있습니다.
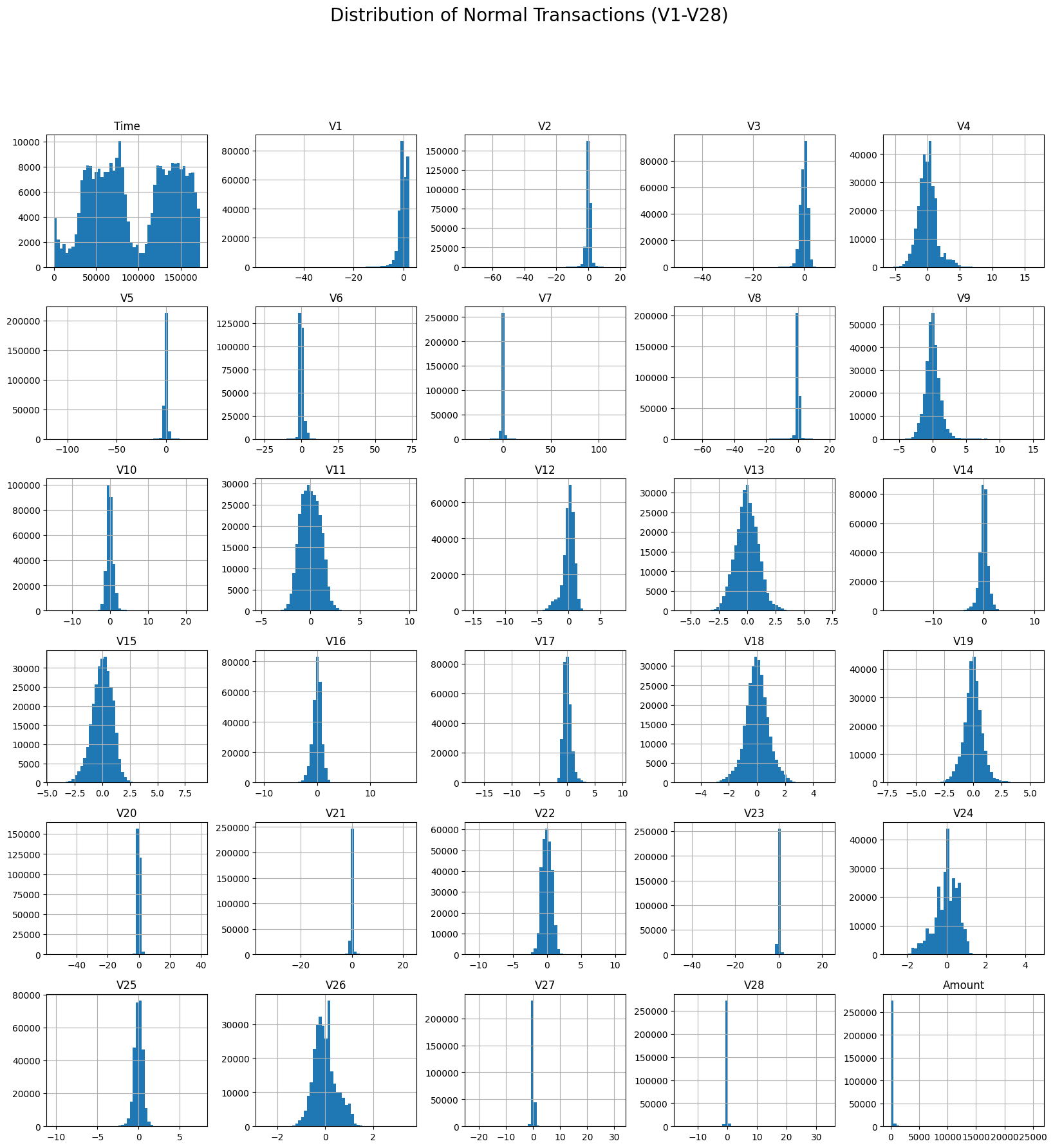
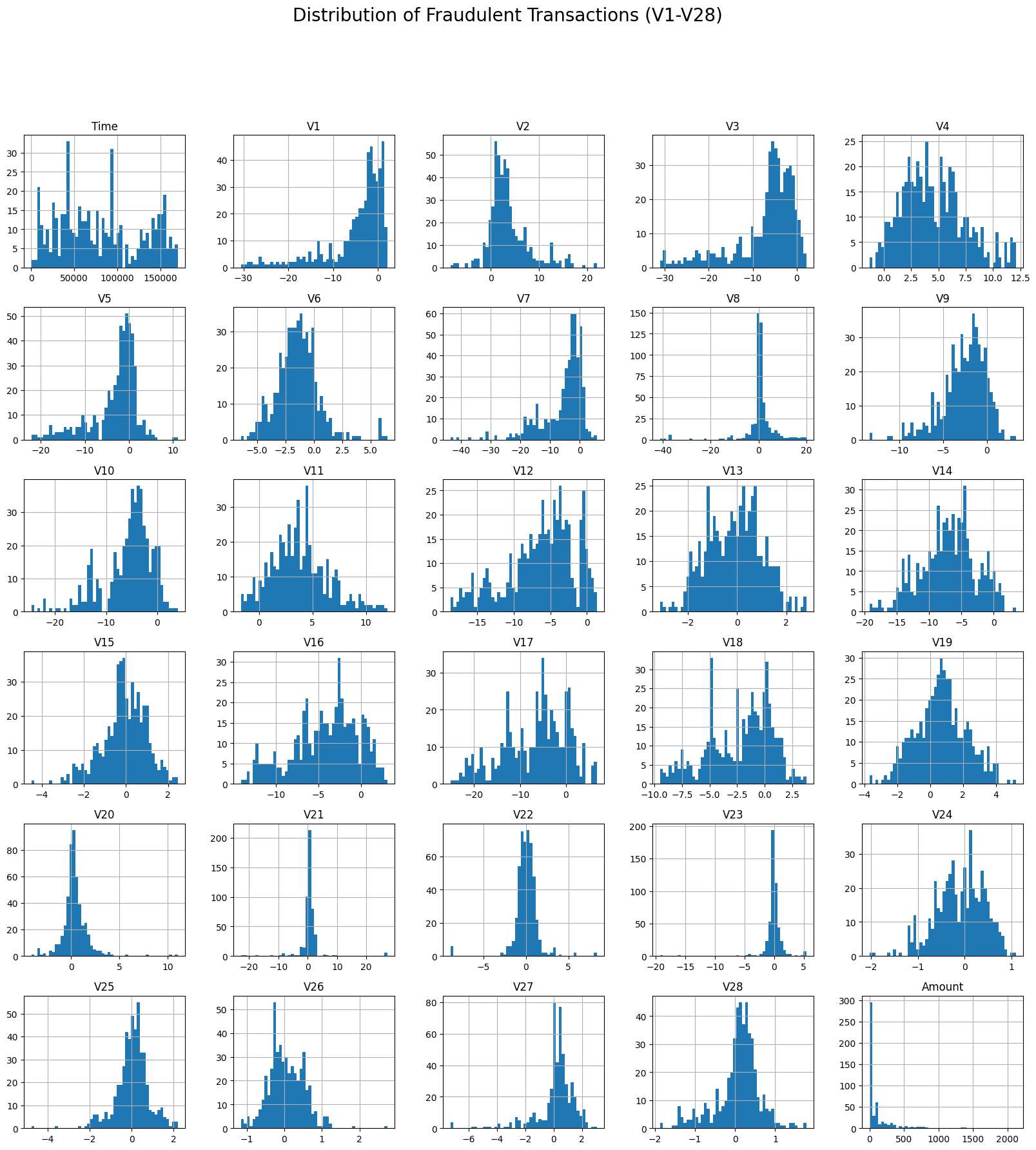
* 정상 데이터와 사기가 탐지된 데이터에서의 각 Feature들의 분포를 보면 차이가 있음을 알 수 있는데요. 정상 데이터의 분포가 사기가 탐지된 데이터의 분포에 비해 분산되어있지 않고 모여있는 모습을 알 수 있습니다.
- 이번에는 피어슨 상관계수를 활용해서 각 변수들끼리의 Correlation을 확인해보았습니다.
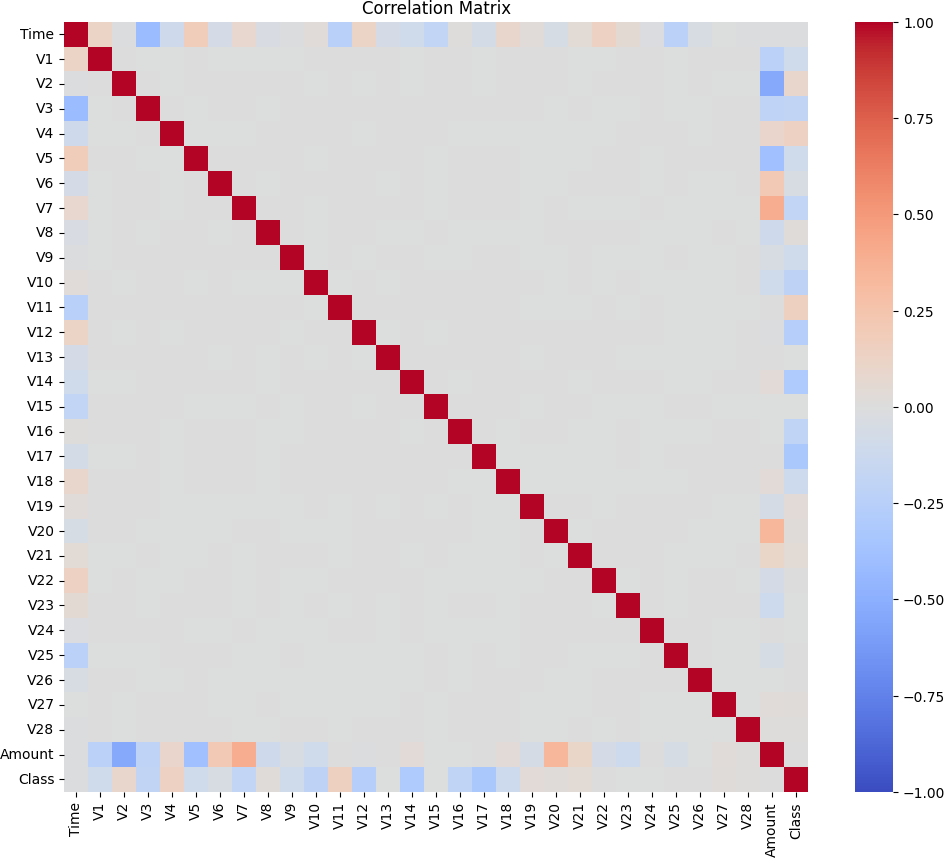
* 각 변수들은 PCA를 통해서 나온 결과물들이기에 서로 Orthogonal하게 뽑힌 차원들이라 상관성이 0에 수렴함을 알 수 있고, Amount와 Class를 기준으로는 양 또는 음의 상관성을 보이는 변수들이 식별됩니다.
- 이번에는 사기 / 정상 거래 간의 분포를 특정 변수를 기준으로 확인해보겠습니다. 예시에 활용할 변수는 V1입니다.
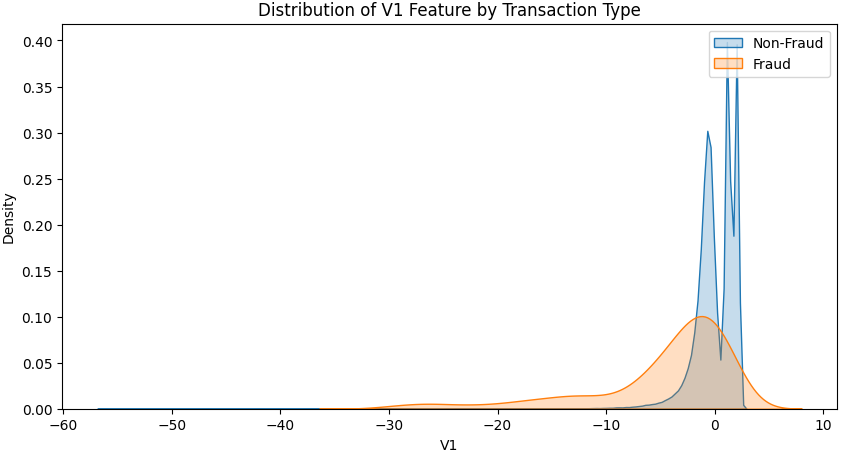
* 앞서 확인했던 전반적인 Distribution을 서로 매칭해서 비교해놓은 것이며, 특정변수를 선정해 직접 상호간의 분포를 매칭해보니 확실히 사기 거래의 경우 변수 값들의 다양성이 더 큰 것을 알 수 있습니다.
- 이번에는 V1 변수와 Amount 간의 Scatter plot을 그려 어떤 형태를 띄는지 알아보겠습니다.
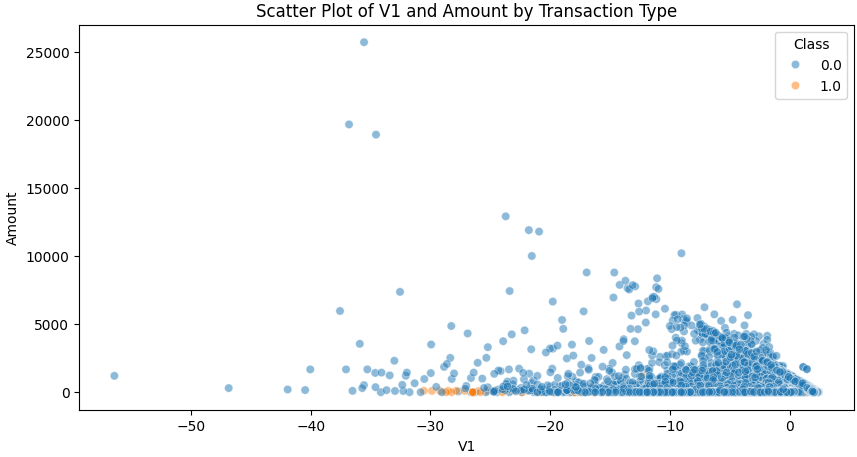
* 가장 분산 설명력이 큰 V1임에도 불구하고 V1 하나만을 가지고는 정상 데이터의 가격 분포와 사기 거래 데이터의 가격 분포간의 직관적인 차이를 확인하기는 어려움을 알 수 있습니다.
- 다음 포스팅에서는 머신러닝 모델링을 통해 사기거래를 탐지할 수 있는 모델들을 하나씩 만들어가보겠습니다.
'머신러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] 불균형 데이터 처리(3) : TomekLink활용 (0) | 2024.11.23 |
|---|---|
| [머신러닝 with Python] 불균형 데이터 처리(2) : 불균형 클래스 분류 문제 평가지표 (0) | 2024.11.21 |
| [머신러닝 with Python] t-SNE란? (차원축소, 시각화) (0) | 2024.07.08 |
| [머신러닝 with Python] 상점 신용카드 매출 예측 (DACON 문제) (2/2) (0) | 2024.06.11 |
| [머신러닝 with Python] 상점 신용카드 매출 예측 (DACON 문제) (1/2) (0) | 2024.06.10 |




댓글