
이번에는 DACON에서 진행되었던 "상점 신용카드 매출 예측" 문제를 해결해가며, 머신러닝 기법을 익혀보도록 하겠습니다.
1. 문제 소개
- 해당 대회는 2019년 7월 11일부터 10월 21일까지 이어진 대회입니다.
- 해당 대회는 2016년 6월 1일부터 2019년 2월 28일까지의 카드 거래 데이터를 이용해 2019년 3월 1일부터 5월 31일까지의 각 상점별 3개월의 총 매출을 예측하는 문제입니다.
* 이때 중요한 것은 3,4,5월이라는 것이며, 새 학기, 새 출발을 의미하는 월들이기에 여러 변수가 발생하고 황사 등 봄철 날씨의 영향을 받을 수 있으며, 가정의 달인 5월이 포함되어 있다는 것도 중요한 변수입니다.
- 문제 유형은 시계열 회귀분석이며, 평가 척도는 MAE(Mean Absolute Error)입니다.
이번 문제는 "DB 분석가" 라는 팀의 코드를 참조했습니다.
2. 문제 해결
먼저 문제를 정의해보겠습니다.
train 데이터와 submission 데이터가 있는데 각 데이터를 불러와줍니다.
import pandas as pd
import os
import warnings
warnings.filterwarnings("ignore")
os.chdir('C:/dacon/ch04')
train = pd.read_csv('./funda_train.csv')
submission = pd.read_csv('./submission.csv')
train data를 통해 데이터의 형태를 확인해보겠습니다.
train.shape
9개의 변수가 있으며, 총 6556613개의 데이터가 기록되어 있음을 알 수 있습니다.

데이터의 구성을 확인해줍니다.
train.head()

다음은 데이터의 속성을 확인하기 위해 .info() 함수를 활용해줍니다.
train.info()각 데이터 별 정수형(int64) / 명목형(object) / 실수형(float64) 인지 확인할 수 있습니다.

이 중 예측해야 종속변수는 amount(매출액) 이며 매출액이 0보다 작은 데이터는 어떤것들이 확인해보겠습니다.
주로 음(-)의 값이 기록되어 있으며, 현재 데이터에서는 환불액을 나타내는 수치로 얼마나 데이터가 있는지 확인해봅니다.
train[train['amount']<0]
총 73,100개의 데이터가 환불액을 나타냄을 알 수 있습니다.
이제 데이터의 구조와 특성에 대해서 간략히 알아봤으니, 데이터를 전처리해보겠습니다.
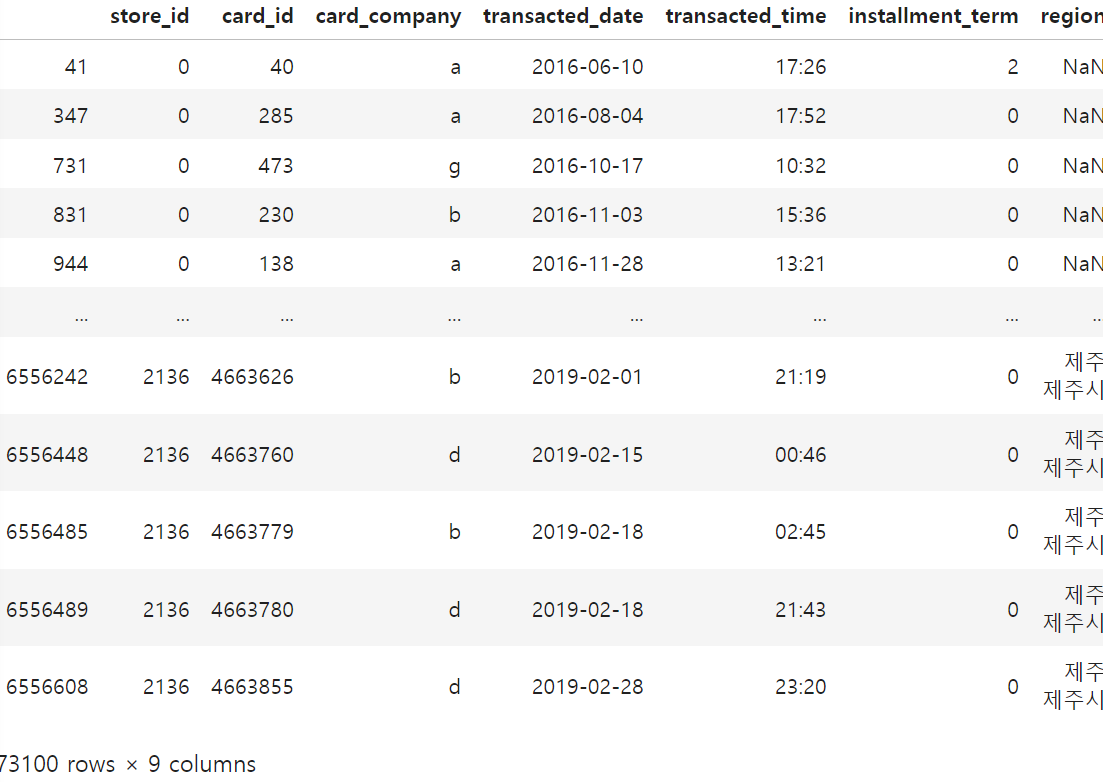
먼저, 결측치가 있는지 확인해보겠습니다.
plt.figure(figsize=(13, 4))
plt.bar(train.columns, train.isnull().sum())
plt.xticks(rotation=45)
확인 결과, region과 type_of_business 열에 NaN값이 존재함을 알 수 있습니다.
이 두 변수(region, tyep_of_business)가 방해가 됨을 확인했으니, 우선 이 둘을 제외해봅니다.
train = train.drop(['region','type_of_business'],axis=1)
train.head()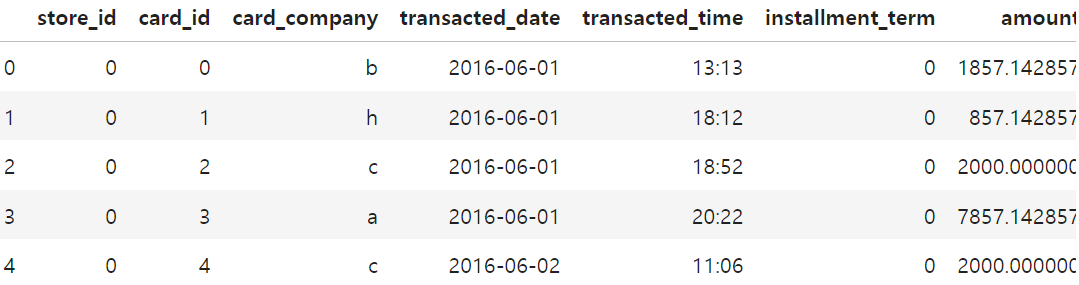
다음은 boxplot 기능을 활용해 amout 변수에 대해서 어떤 분포를 가지고 있는지 확인해봅니다.
plt.figure(figsize=(8, 4))
sns.boxplot(train['amount'])
가격대가 다양한 분포를 보이고 있으며, 특히 0 인근에 많은 분포를 보임을 알 수 있습니다.

이제 다음과 같은 전처리를 해줍니다.
1) 시간 데이터 처리를 위해, 거래일과 거래시간을 합친 변수를 만들어줍니다.
2) 환불 거래를 제거해줍니다. 이를 위해 매출액 중 -인 환불액을 찾고, 그 환불액에서 store id와 card id를 추출하여 이와 동일한 금액이 다른 일자에 + 된 경우를 찾아 서로 상쇄하듯 없애줍니다.
# 거래일와 거래시간을 합친 변수를 생성합니다.
train['datetime'] = pd.to_datetime(train.transacted_date + " " +
train.transacted_time, format='%Y-%m-%d %H:%M:%S')
## 환불 거래를 제거하는 함수를 정의합니다.
def remove_refund(df):
refund = df[df['amount']<0] # 매출액 음숫값 데이터를 추출합니다.
non_refund = df[df['amount']>0] # 매출액 양숫값 데이터를 추출합니다.
removed_data = pd.DataFrame()
for i in tqdm(df.store_id.unique()):
# 매출액이 양숫값인 데이터를 상점별로 나눕니다.
divided_data = non_refund[non_refund['store_id']==i]
# 매출액이 음숫값인 데이터를 상점별로 나눕니다.
divided_data2 = refund[refund['store_id']==i]
for neg in divided_data2.to_records()[:]: # 환불 데이터를 차례대로 검사합니다.
refund_store = neg['store_id']
refund_id = neg['card_id'] # 환불 카드 아이디를 추출합니다.
refund_datetime = neg['datetime'] # 환불 시간을 추출합니다.
refund_amount = abs(neg['amount']) # 매출 음숫값의 절댓값을 구합니다.
## 환불 시간 이전의 데이터 중 카드 이이디와 환불액이 같은 후보 리스트를 뽑습니다.
refund_pay_list = divided_data[divided_data['datetime']<=refund_datetime]
refund_pay_list = refund_pay_list[refund_pay_list['card_id']==refund_id]
refund_pay_list = refund_pay_list[refund_pay_list['amount']==refund_amount]
# 후보 리스트가 있으면 카드 아이디, 환불액이 같으면서 가장 최근시간을 제거합니다.
if(len(refund_pay_list)!=0):
refund_datetime = max(refund_pay_list['datetime']) # 가장 최근 시간을 구합니다
noise_list = divided_data[divided_data['datetime']==refund_datetime] # 가장 최근시간
noise_list = noise_list[noise_list['card_id']==refund_id] # 환불 카드 아이디
noise_list = noise_list[noise_list['amount']==refund_amount] ## 환불액
divided_data = divided_data.drop(index=noise_list.index) # 인덱스를 통해 제거
## 제거한 데이터를 데이터프레임에 추가합니다.
removed_data = pd.concat([removed_data,divided_data],axis=0)
return removed_data
환불 거래가 제거 된 후의 상태입니다.
이제 활용하게 될 데이터 셋의 명칭은 positive_data로 정의해줍니다.
## 환불 거래 제거 함수를 통해 환불 거래를 제거합니다.
positive_data = remove_refund(train)
plt.figure(figsize=(8, 4))
sns.boxplot(positive_data['amount'])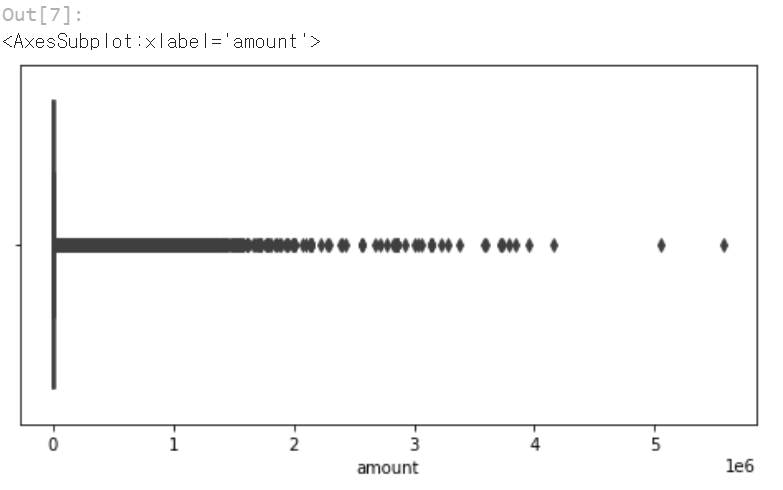
다음은 다운 샘플링을 진행해줍니다.
요구사항이 각 월별 매출의 판매량이기에, 데이터를 시간 / 일단위가 아닌 월단위로 변경하여 학습해야 될 데이터의 개수를 줄이는 통합을 진행해줍니다.
이때 매출이 발생하지 않는 월은 2로 채웁니다. 왜냐하면, 데이터의 진동폭을 안정화시키기 위해 log 정규화할 예정인데 1이하의 값은 로그 정규화를 할 때 음수 또는 무한대가 나오기 때문입니다.
## 월 단위 다운 샘플링 함수를 정의
def month_resampling(df):
new_data = pd.DataFrame()
# 년도와 월을 합친 변수를 생성합니다.
df['year_month'] = df['transacted_date'].str.slice(stop=7)
# 데이터의 전체 기간을 추출합니다.
year_month = df['year_month'].drop_duplicates()
# 상점 아이디별로 월 단위 매출액 총합을 구합니다.
downsampling_data = df.groupby(['store_id', 'year_month']).amount.sum()
downsampling_data = pd.DataFrame(downsampling_data)
downsampling_data = downsampling_data.reset_index(drop=False,inplace=False)
for i in tqdm(df.store_id.unique()):
# 상점별로 데이터를 처리합니다.
store = downsampling_data[downsampling_data['store_id']==i]
# 각 상점의 처음 매출이 발생한 월을 구합니다.
start_time = min(store['year_month'])
# 모든 상점을 전체 기간 데이터로 만듭니다.
store = store.merge(year_month,how='outer')
# 데이터를 시간순으로 정렬합니다.
store = store.sort_values(by=['year_month'], axis=0, ascending=True)
store['amount'] = store['amount'].fillna(2) # 매출이 발생하지 않는 월은 2로 채웁니다.
store['store_id'] = store['store_id'].fillna(i) # 상점 아이디 결측치를 채웁니다.
store = store[store['year_month']>=start_time] # 처음 매출이 발생한 월 이후만 뽑습니다.
new_data = pd.concat([new_data,store],axis=0)
return new_data
# 환불 제거 데이터를 월 단위로 다운 샘플링합니다.
resampling_data = month_resampling(positive_data)
resampling_data['store_id'] = resampling_data['store_id'].astype(int)
resampling_data
데이터가 월단위로 통합되었으며 그 숫자가 많이 줄었음을 확인할 수 있습니다.
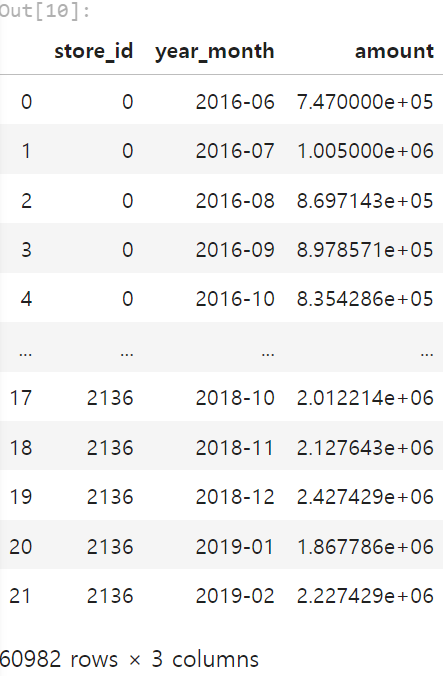
* 이처럼 카드 결제 이력 데이터에 대해 월 단위로 시간 간격을 재조정한 다운 샘플링은 예측 구간을 최소화해 불확실성을 줄여줍니다. 하지만 시간 간격을 너무 크게 재구성하면 데이터 샘플의 수가 너무 작아지기 때문에 정확도가 오히려 떨어지게 됩니다. 따라서 많은 실험과 데이터 분석을 통해 월단위가 아닌 주단위 또는 그 보다 작거나 큰 단위로 조정해서 성능을 더 향상시킬 수 도 있습니다.
이제 시계열 데이터 분석을 위해 데이터프레임을 시리즈 객체로 변환할 것입니다.
이때 상점 아이디별 amount를 확인할 수 있는 시리즈 객체를 만들어줍니다.
# 데이터프레임을 Series로 변환하는 함수
def time_series(df, i):
# 상점별로 데이터를 뽑습니다.
store = df[df['store_id']==i]
## 날짜 지정 범위는 영업 시작 월부터 2019년 3월 전까지 영업 마감일 기준
index = pd.date_range(min(store['year_month']),'2019-03',freq='BM')
## 시리즈 객체로 변환
ts = pd.Series(store['amount'].values,index=index)
return ts
잘 만들어졌는지 상점 아이디가 0번인 데이터를 대상으로 확인해봅니다.
# 상점 아이디가 0번인 데이터를 시리즈 객체로 변환
store_0 = time_series(resampling_data, 0)
store_0
이번에는 상점 아이디가 2번인 데이터 시리즈를 시계열로 시각화해봅니다.
# 상점 아이디가 2번인 데이터를 시리즈 객체로 변환
store_2 = time_series(resampling_data, 2)
store_2.plot()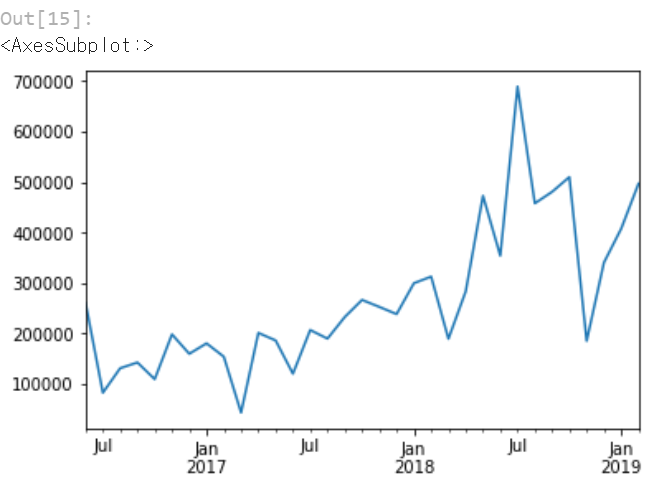
'머신러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] t-SNE란? (차원축소, 시각화) (0) | 2024.07.08 |
|---|---|
| [머신러닝 with Python] 상점 신용카드 매출 예측 (DACON 문제) (2/2) (0) | 2024.06.11 |
| [Machine Learning] What is machine learning? What is ML? (0) | 2024.03.06 |
| [머신러닝 with 파이썬] 군집화(클러스터링) : K-means & HDBSCAN / 시각화 (0) | 2023.09.27 |
| [머신러닝 with 파이썬] PCA / 주성분 분석 / 차원축소 /iris 데이터 활용 (0) | 2023.09.26 |




댓글