
이번 시간에는 지난 시간에 이어서 앙상블(Ensemble) 기법에 대해서 알아보겠습니다.
이번에 알아볼 것은 부스팅 기법에 대해서 알아보겠습니다.
부스팅에도 여러 기법이 존재하지만, 이번 시간에는 가장 기본이 되는 GBM(Gradient Boosting Machine)에 대해서 알아보겠습니다.
1. 부스팅(Boosting)이란?
- 부스팅이란, 여러 개의 약한 학습기(Weak Learner)를 순차적으로 학습 - 예측 하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식을 말합니다.
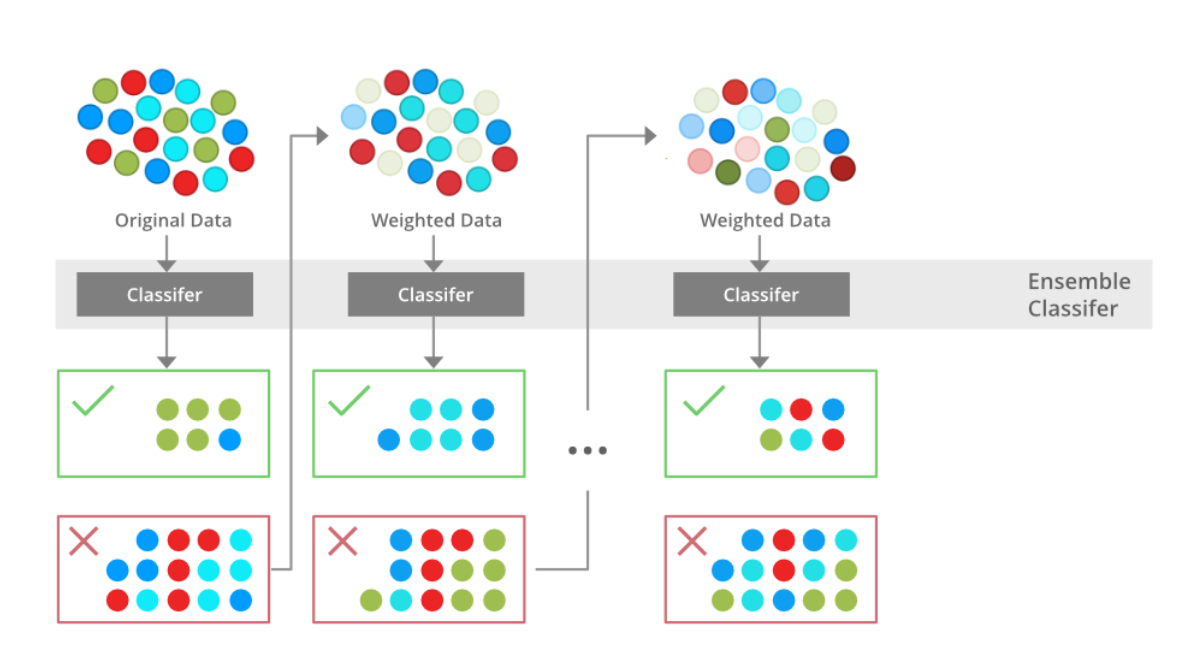
- 부스팅의 초창기 모델은 에이다부스트(AdaBoost)입니다. 이는, 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘을 말합니다.

위 그림을 설명하면 아래와 같습니다.
a) 먼저, 첫번째 약한 학습기로 최초 데이터(D1) 분류를 한 뒤, 잘못 분류된 것들에 대해 표시하여 해당 데이터에 가중치 값이 부여된 업데이트 된 데이터셋(D2)을 구축합니다..
b) 업데이트 된 데이터로 다시 약한 학습기로 분류를 한 뒤, 다시 잘못 분류된 것들에 대해 표시하고 마찬가지로 해당 데이터에 가중치 값이 부여된 업데이트 된 데이터셋(D3)을 구축합니다.
c) 지금까지 총 3번의 약한 학습기가 구축되었고, 이 학습기들을 가중치에 따라 합치면 원하는 결과가 분류되는 분류기가 만들어집니다.
이러한 AdaBoost를 기반으로 발전한 방법이 다음에 소개할 GBM (Gradient Boost Machine)입니다.
2. GBM(Gradient Boost Machine)
- GBM은 에이다 부스트와 유사하나, 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이입니다.
- 경사 하강법은 머신러닝과 딥 러닝에서 모델을 학습시키기 위해 사용되는 최적화 알고리즘 중 하나를 말합니다. 이는, 모델의 손실 함수(Loss Function)를 최소화하기 위해 모델의 파라미터(parameter)를 조정하는 방법 중 하나인데요
(특히, 다수의 변수와 데이터를 포함한 빅데이터에 대한 분석 시, 빠른 연산과 연산 오류를 방지하기위해 자주 사용됩니다)
- 경사하강법의 작동원리는 아래와 같습니다.
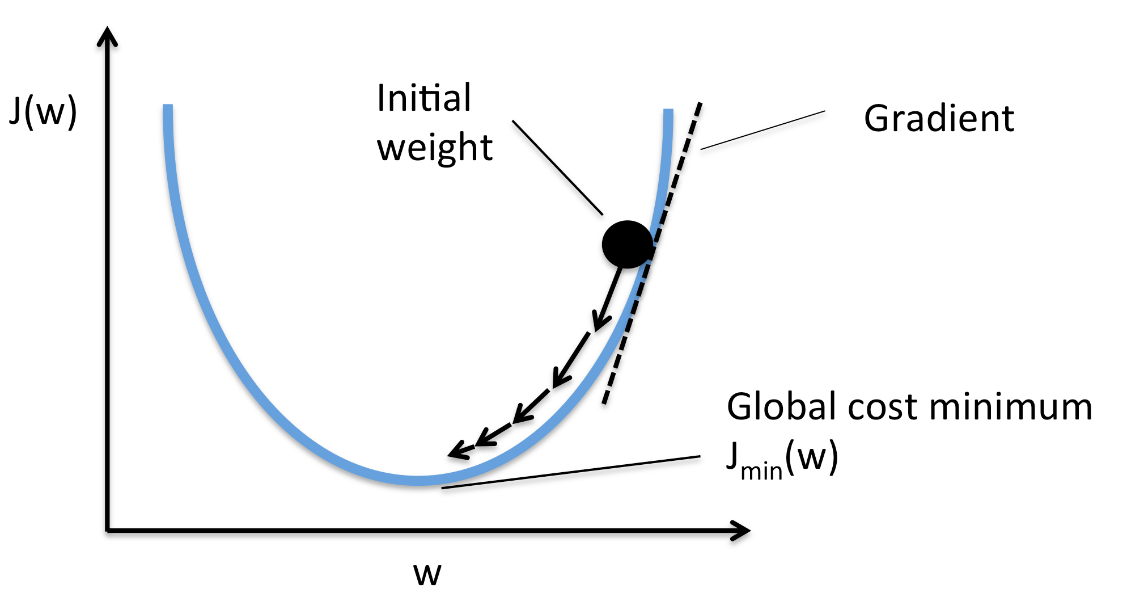
** 아래 그림은 가장 작은 J(w) 값을 찾는 문제입니다. **
a) 초기화 : 먼저 모델의 파라미터를 임의값으로 초기화합니다.
* 아래 그림에서는 임의의 w 값을 선정하는 것을 말합니다.
b) 예측과 손실 계산 : 초기화된 파라미터로부터 모델을 사용하여 예측을 수행하고, 예측값과 실제값 간의 손실을 계산합니다.
* 아래 그림에서는 예측값은 최초 점이 찍힌 곳에서 J(w)의 값을 의미하고, 실제 최소값은 J(w)의 가장 낮은 지점입니다. 두 지점사이에는 차이, 즉 손실이 존재합니다.
c) 그래디언트 계산: 손실 함수의 그래디언트(기울기)를 계산합니다. 이 그래디언트는 현재 파라미터 설정에서 손실 함수가 어느 방향으로 더 작아지는지를 나타냅니다.
* 아래 그림에서는 w 지점에서, 미분을 한 값이 그래디언트를 의미합니다.
d) 파라미터 업데이트: 계산된 그래디언트를 사용하여 파라미터를 업데이트합니다. 경사하강법은 손실 함수를 최소화하기 위해 파라미터를 그래디언트의 반대 방향으로 조금씩 이동시키는 방법입니다. 이러한 업데이트는 학습률(learning rate)이라는 하이퍼파라미터를 사용하여 조절됩니다.
* 아래 그림에서는 학습률은 화살표 방향의 w축 크기를 의미합니다. 아래그림에서는 학습률이 점점 줄어드는(화살표의 w 성분이 점점 줄어드는) 것을 볼 수 있습니다.
e) 반복: 위의 단계를 여러 번 반복하면서 손실 함수가 최소화되는 파라미터를 찾습니다. 경사하강법은 손실 함수의 그래디언트를 계속 계산하고 파라미터를 업데이트하면서 점진적으로 최적의 파라미터를 찾아갑니다.
- 이와 같이 AdaBoost의 약한 학습기를 가중치에 따른 결합을 하고, 이때 가중치 계산을 경사하강법으로 하는 것을 Gradient Boost Machine 이라고 알게 되었습니다. 그렇다면, 예제와 함께 파이썬 코드를 통해 모델을 구현해보도록 하겠습니다.
* 분석에 사용할 데이터는 유방암 데이터(breast_cancer data)로 사이킷런에서 불러왔습니다.
* 해당 데이터는 분류(Classification)이기에 GradientBoosting Classifier를 사용했고
* 학습 데이터와 테스트 데이터로 분류했으며
* 분류 결과는 오차 행렬과 분류 리포트(Classification Report)로 정리했습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
# 필요한 라이브러리 임포트
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score, precision_score, recall_score, f1_score
# Breast Cancer 데이터 로드
data = load_breast_cancer()
X, y = data.data, data.target
# 데이터 분할 (학습 데이터와 테스트 데이터)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# GBM 모델 생성
gbm_classifier = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth= 3,random_state=42)
# 모델 학습
gbm_classifier.fit(X_train, y_train)
# 테스트 데이터에 대한 예측
y_pred = gbm_classifier.predict(X_test)
# Confusion Matrix 계산
confusion_mat = confusion_matrix(y_test, y_pred)
# Confusion Matrix 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_mat, annot=True, fmt="d", cmap="Blues", cbar=False)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
# Classification Report 계산
classification_rep = classification_report(y_test, y_pred)
# 결과 출력
print("Classification Report:\n", classification_rep)
|
cs |
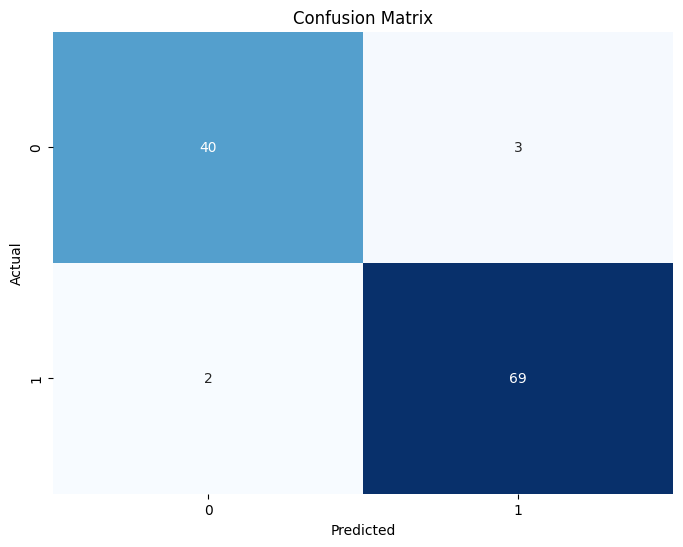
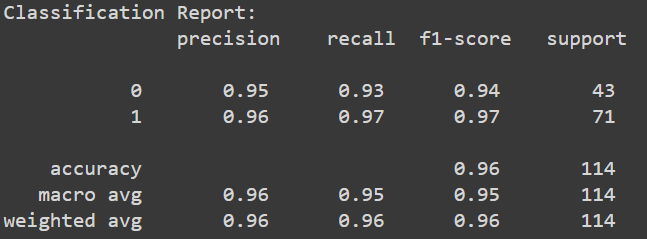
* 결과는 위에서 보시는 것과 같이 약 96%의 정확도(Accuracy)로 양성과 음성을 구분해냈습니다.
* 전체 114개의 데이터 중 단 5개만 잘못분류되었으며, 양성(1)의 경우 97%라는 꽤나 높은 재현율(Recall)을 보여주었습니다.




댓글