
이번에 알아볼 앙상블 모델은 Light GBM입니다.
Light GBM은 XGBoost가 나온 후 등장한 모델로, XGBoost의 장점은 살리고 단점은 보완된 모습이라고 볼 수 있는데요.
그렇지만, 무조건 XGBoost보다 좋다고 할 수는 없으니, 자세한 내용들을 한번 알아봅시다
1. Light GBM이란?
- Light GBM이란, Light Gradient Boosting Machine의 약자로 이 역시 GBM(Gradient Boosting Machine)에 기반을 두고 있는 모델입니다.
* GBM이란, Boosting 방식 중 약한 학습기를 결합해나가는 방식을 Gradient를 이용해서 모델을 개선하는 방식.(Ada Boost는 데이터에 중요한 데이터에 가중치(Weight)를 주는 방식이라는 점에서 차이가 있음)
[머신러닝 with Python] 앙상블(Ensemble) 학습 (3) / 부스팅(Boosting) / GBM
[머신러닝 with Python] 앙상블(Ensemble) 학습 (3) / 부스팅(Boosting) / GBM
이번 시간에는 지난 시간에 이어서 앙상블(Ensemble) 기법에 대해서 알아보겠습니다. 이번에 알아볼 것은 부스팅 기법에 대해서 알아보겠습니다. 부스팅에도 여러 기법이 존재하지만, 이번 시간에
jaylala.tistory.com
- Light GBM은, 정형 데이터(Structured Data)의 분류 문제에서 그 우수한 효과를 입증한 XGBoost의 단점 중 하나인 GridSearch CV를 활용한 하이퍼 파라미터 튜닝을 수행하다보면 수행시간이 너무 오래 걸리는 단점을 보완한 모델입니다.
[머신러닝 with Python] 앙상블(Ensemble) 학습 (4) / XGBoost
[머신러닝 with Python] 앙상블(Ensemble) 학습 (4) / XGBoost
이번에 알아볼 앙상블 학습은 부스팅(Boosting) 기법 중 대표적인 방법인 XGBoost 입니다. XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나입니다. 유명한 캐글 경연 대회(
jaylala.tistory.com
* LightGBM과 XGBoost의 예측 성능적인 측면에서는 별다른 차이가 없다고 볼 수 있습니다만, 학습 속도적인 측면에서 더 빠른 모습을 보이는 알고리즘 중 하나라 볼 수 있습니다.
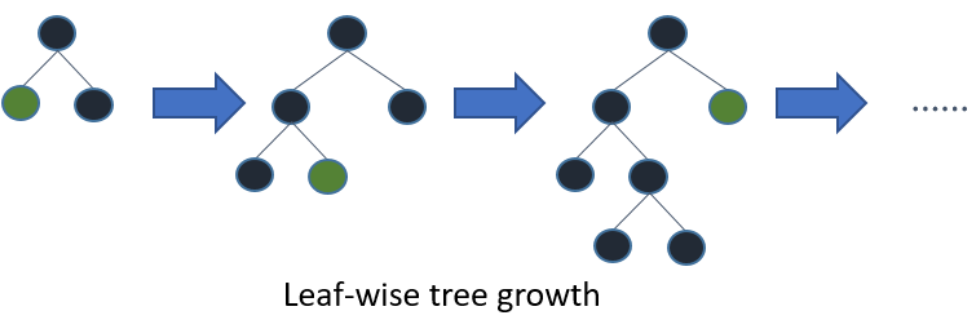
- Light GBM의 XGBoost 대비 가장 큰 특징은 "리프 중심 트리 분할(Leaf wise Tree Growth)" 방식을 사용한다는 점입니다.
* Leaf wise 분할의 모습은 아래 그림처럼 정리할 수 있습니다.
* 이는 트리의 균형을 맞추지 않고, 최대 손실값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리를 생성합니다. 이를 통해 균형 트리 분할방식보다 예측 오류 손실을 최소화할 수 있습니다.
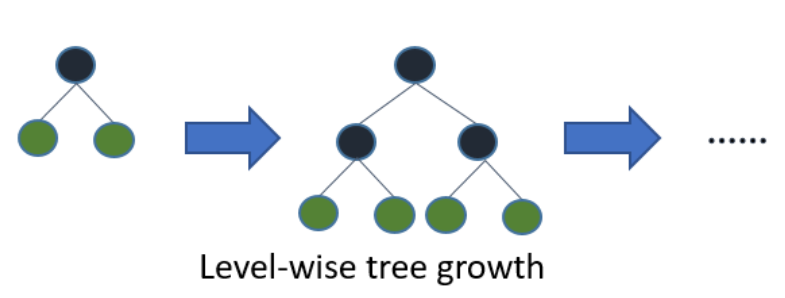
* 이에 대비되는 "균형 트리 분할방식(Level-wise Tree Growth)"은 수평적으로 트리를 키우는 방식으로 아래 그림과 같이 정리할 수 있습니다.
* 이는 트리를 균형적으로 키우게되면 오버피팅(Over fitting)에 보다 강한 구조를 가질 수 있기 때문입니다. 하지만, 균형적으로 만들기 위해서 Leaf wise 보다는 더 많은 연산 시간이 수행된다는 단점이 있습니다.
- Light GBM의 장점과 단점은 아래와 같이 정리해볼 수 있습니다.
1) 장점
a) 뛰어난 속도와 효율성 : Leaf wise 구조를 취하고 있기때문에 보다 빠른 연산속도 및 높은 예측률을 보입니다. 특히, 대용량 데이터 셋에서 그 효과가 뛰어난데, 통상적으로 10,000개 이상의 관측치가 필요하다고 알려져 있습니다.
b) 메모리의 효율성 : Light GBM은 메모리를 효율적으로 저장하고 처리하는 기술이 적용되었습니다.
c) 자동 조기 종료 : XGBoost처럼 자동으로 모델을 훈련 중에 자동 조기 종료하는 기능을 가지고 있어 과적합을 방지할 수 있습니다.
d) 파라미터의 다양성 : 하이퍼파라미터가 많다보니, 해당 튜닝을 통해 보다 데이터에 적합한 모델을 만들 수 있습니다. 하지만, 이는 곧 모델 구현의 복잡성으로 이어지기도 합니다.
2) 단점
a) 작은 데이터셋에서의 과적합 위험 : 장점에서 설명드린 것처럼, 10,000개 이상의 데이터에 대해서는 뛰어난 성능을 보이지만 작은 데이터 셋에서는 과적합이 일어날 가능성이 높고, 이를 방지하기 위해 보다 세심한 하이퍼 파라미터 튜닝이 필요하다보니 모델의 구성에 있어서 어려움이 발생할 수 있습니다.
b) 파라미터 설정의 복잡성 : 앞서 말씀드린 것처럼 설정해야 될 파라미터가 많다보니 이를 설정하는데 많은 시간이 들 수 있습니다.
2. Python을 활용한 Light GBM의 구현 / Breast Cancer 데이터 사용
- 이번에는 파이썬을 활용해서 Light GBM을 구현해보겠습니다.
- 모델을 구현하기에 앞서, 모델에서 사용되는 파라미터에 대해 알아보겠습니다. Light GBM의 하이퍼 파라미터는 많은 편입니다. 다 알아보기에는 제한되니 이 중 주요한 파라미터에 대해 알아보겠습니다.
a) n_estimators [default=100] : 반복 수행하려는 트리의 개수를 지정. 클수록 예측성능은 좋아지나 과적합 위험이 있음
b) learning_rate [default=0.1] : Gradient를 활용하여 Global minimum을 찾아갈 때 활용되는 step의 크기. 너무 작으면 학습시간이 길어지고, 너무 크면 Global minimum에 수렴되지 못하게 될 수 있음
c) max_depth [default=-1] : 트리를 어느정도까지 깊게 할 것인가에 대한 파라미터. -1의경우 깊이에 제한없이 한다는 의미임
d) min_child_samples [default =20] : 리프 노드에서 요구되는 최소 샘플 수. 이 값을 증가시키면 과적합을 줄이는데 도움
e) boosting_type [default=gbdt]: 부스팅 방법을 선택. 기본값은 'gbdt'이며, 'rf'도 사용 가능
* gbdt : gradient boosting decision tree / rf : random forest
f) lambda_l1 및 lambda_l2 [default = 0 / 둘 다]: L1 및 L2 정규화를 제어하는 하이퍼파라미터 모델의 복잡도를 제한하는데 사용됨.
- 이제 사이킷런을 활용해 Light GBM을 구현해보겠습니다.
* 모델은 기본 파라미터를 사용한 Light GBM과 일부 파라미터(num_leaves, max_depth, learning_rate)를 GridSearch CV를 활용해 튜닝해 본 Light GBM을 비교하기 위해 두 가지로 설정했습니다.
* 데이터는 사이킷런에 내장된 Breast Cancer 데이터를 활용했으며
* 결과는 Confusion Matrix와 이를 바탕으로 계산된 Classification Report (Accuracy, Precision, Recall, f1-score, etc), 그리고 계산에 소요된 시간을 설정해보았습니다.
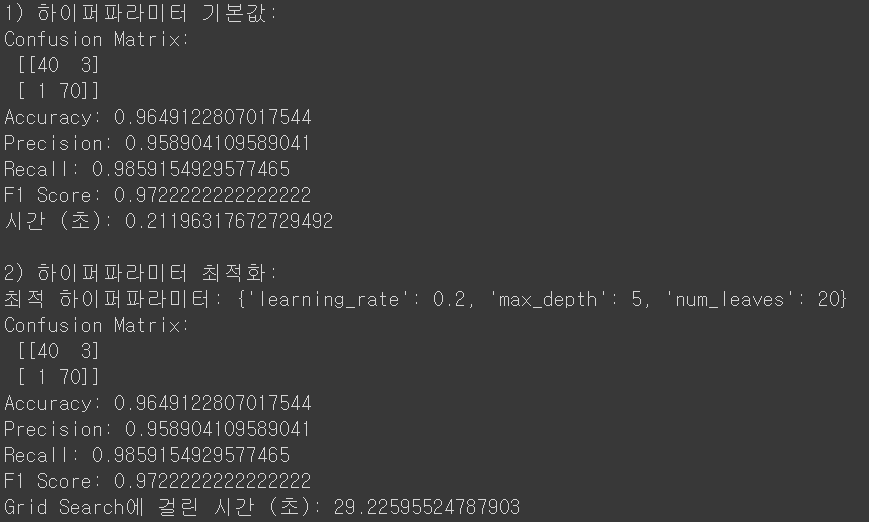
* 먼저 , 결과는 하이퍼 파라미터를 튜닝한 것과 안한 것에서 차이가 없음을 확인할 수 있습니다.
* 하이퍼 파라미터 튜닝을 하는 시간만 더 많이 소요된 것으로 보이긴 하네요
* 다만, 최적의 하이퍼 파라미터로 learning_rate는 0.2, max_depth는 5, num_leaves는 20 으로 찾았으며 이는 default 값인0.1 / -1(제한 없음) / 31 과는 차이가 있습니다. 즉, 해당 데이터에서는 이 파라미터가 더 max delta loss를 줄였다는 말이며, 데이터가 더 많이 수집된다면 Grid Search CV의 효과가 좋을 것이라 예상됩니다.
* 다음은 Classification Report로 결과를 정리해보았습니다.

* 앞서 알아보았듯 결과상에는 큰 차이가 없네요 :)
- 아무래도 Breast Cancer의 데이터의 크기가 총 569개 밖에 되지 않기 때문에, 앞서 말씀드린 10,000개보다는 훨씬 작아서 큰 효과를 발휘하지는 못한것으로 생각됩니다.
- 다음 포스팅에서는 보다 더 큰 데이터를 활용해 Light GBM을 사용해보고, 이때 스태킹이라는 방법에 대해서도 설명드리겠습니다.




댓글