
지난번 포스팅에서는 앙상블 기법의 기본인 보팅(Voting)에 대해서 알아보았습니다.
이번에는 앙상블 기법 중 배깅(Bagging)에 대해서 알아보겠으며, 배깅의 대표적인 모델인 랜덤포레스트에 대해서 알아보겠습니다.
1. 배깅(Bagging)이란?
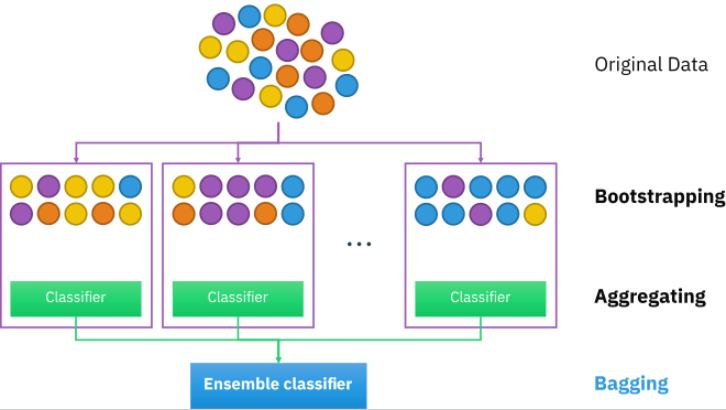
- 배깅(Bagging)이란, Bootstrap Aggregating의 약어로 말 그대로
a) 부트스트랩(Bootstrap) 방법으로 원본 데이터에서 랜덤성과 중복을 허용하여 학습 샘플을 추출하고
b) 정해진 모델로 각각의 샘플에 대해서 학습한 결과를 Aggregating(종합, 집합)해서 최적의 결과를 도출하는 방법을 말합니다.
- 이를 정리해서 Bagging 의 작동방식에 대해서 알아보면 아래와 같습니다.
1) 데이터의 부분 집합(Bootstrap 샘플)을 무작위로 생성합니다. 이는 원본 데이터에서 중복을 허용하고 랜덤하게 선택한 샘플로 구성됩니다.
2) 각 부분 집합에 대해 동일한 학습 알고리즘(예: 결정 트리)을 적용하여 여러 개의 모델을 생성합니다.
3) 이렇게 생성된 모델들의 예측을 평균화(회귀) 또는 다수결 투표(분류)를 통해 최종 예측을 수행합니다.
* 이때 보팅(투표)은 소프트 보팅 방식을 적용합니다.
- 이러한 배깅의 가장 큰 장점은
a) 과적합을 줄여 모델의 안정성을 향상시키며,
b)병렬화가 가능하기때문에 계산 성능이 향상된다는 점입니다.
2. Python 코드로 알아보는 랜덤포레스트(Random Forest)
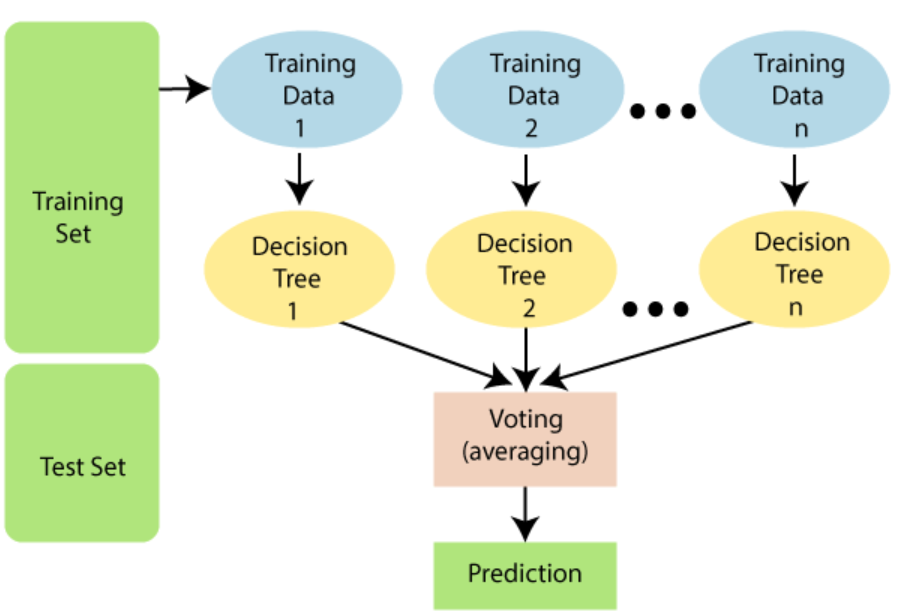
- 랜덤포레스트(Random Forest)는 배깅의 일종으로, 학습 시키는 모델을 결정트리(Decision Tree)로 정하여 이 들의 결과를 소프트 보팅의 방식을 통해 Aggregating 하는 방법을 말합니다.
- 이러한 랜덤포레스트의 작동방식을 간략화해서 설명해보면
1) 데이터의 부분 집합(Bootstrap 샘플)을 생성합니다.
2) 각 노드에서 최적의 분할을 결정할 때, 전체 feature 중 일부 feature만을 무작위로 선택하여 사용합니다.
* 이러한 기법을 "랜덤 서브스페이스(Random Subspace)" 또는 "랜덤 특성(Random Features)"이라고 합니다.
3) 각 결정 트리의 예측을 종합하여 최종 예측을 수행합니다.
- 랜덤포레스트의 주요 특징 및 장점을 정리해보면
1) 과적합을 감소시키며 모델의 일반화 성능을 향상시킵니다.
2) Out-of-Bag(OOB) 샘플을 사용하여 모델 성능을 평가할 수 있습니다.
3) Feature 중요도를 측정할 수 있어, 어떤 feature가 예측에 가장 중요한지 파악할 수 있습니다.
4) 병렬 처리가 가능하여 대규모 데이터셋에 대해 빠른 학습이 가능합니다.
그렇다면, 랜덤포레스트가 어떻게 작동되는지 파이썬 코딩을 통해서 알아보겠습니다.
이때 사용할 데이터는 titanic 데이터 이며, 탑승객의 생존여부에 대해서 예측해보는 모델을 랜덤포레스트를 활용해 만들어보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 데이터 불러오기
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df = pd.read_csv(url)
# 데이터 전처리: 필요한 열 선택 및 결측치 처리
df = df[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Survived']].dropna()
# 범주형 변수를 숫자로 변환 (원핫 인코딩)
df = pd.get_dummies(df, columns=['Sex'], drop_first=True)
# Features(X)와 Target(y) 분리
X = df.drop('Survived', axis=1)
y = df['Survived']
# 데이터를 학습용과 테스트용으로 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
cs |
* 먼저 필요한 라이브러리 임포트를 하고, 데이터도 불러옵니다.
* 데이터는 오픈 소스로 공개하고 있는 데이터를 불러와서 사용합니다.
* 이후 데이터에 결측치가 많기에, 결측치를 포함한 생존자들을 제거하고, 범주형 데이터는 원핫 인코딩을 통해 숫자로 표현해줍니다.
(이번 코딩에서는 편하게 결과를 도출하기위해 결측치를 포함한 생존자의 데이터를 제거했으나, 다양한 방법을 활용해 결측치를 처리하는 방법을 활용하면 모델의 성능을 더 향상시킬 수도 있습니다)
* 이후 데이터를 Features(행렬 X)와 y(생존여부)로 나누고, 학습용과 테스트용으로 나누었습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 랜덤포레스트 모델 생성 및 학습
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 모델 평가
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# 결과 출력
print(f'Accuracy: {accuracy:.2f}')
# Confusion Matrix 시각화
plt.figure(figsize=(6, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=['Not Survived', 'Survived'],
yticklabels=['Not Survived', 'Survived'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()# Classification Report 추출
class_report_str = classification_report(y_test, y_pred)
# Classification Report 문자열을 Pandas DataFrame으로 변환
class_report_df = pd.read_csv(pd.compat.StringIO(class_report_str), sep='\\s+')
# 출력
print(class_report_df)
|
cs |


*이후 랜덤포레스트를 만들었습니다. 이때 사용된 하이퍼 파라미터는 기본 파라미터를 사용했습니다.
(랜덤포레스트의 하이퍼 파라미터와 하이퍼 파라미터를 손쉽게 튜닝하는 방법에 대해서는 다음 포스팅에 알아보겠습니다)
* 결과는, 정확도가 77%(=0.77)이 나왔으며, 해당 결과를 오차 행렬로 시각화해보았습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# Classification Report 시각화
report_dict = classification_report(y_test, y_pred, output_dict=True)
precision = report_dict['weighted avg']['precision']
recall = report_dict['weighted avg']['recall']
f1_score = report_dict['weighted avg']['f1-score']
#
print('Classification Report:\n', class_report)
# 시각화
plt.figure(figsize=(8, 4))
sns.barplot(x=['Precision', 'Recall', 'F1-Score'], y=[precision, recall, f1_score], palette='Blues')
plt.title('Classification Report Metrics')
plt.ylim(0, 1)
plt.show()
|
cs |
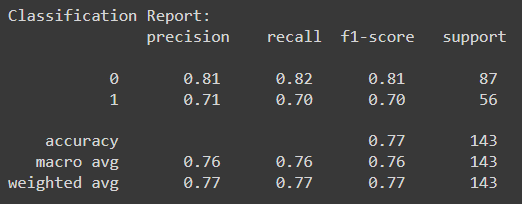
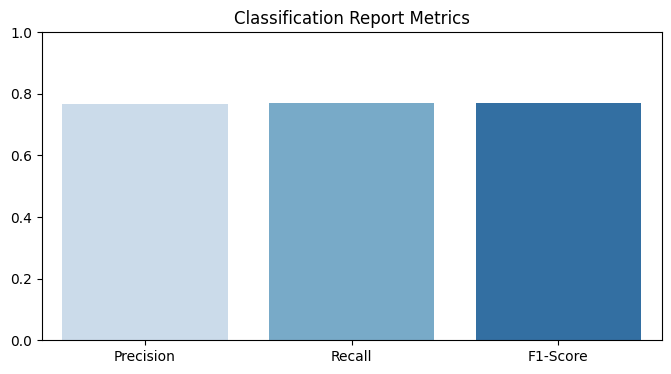
* 해당 분류의 결과를 더 세분화하 Classifcitaion Report를 만들어보았습니다.
* 여기에 사용된 Accuracy, Precision, Recall, f1-score 에 대해서는 아래 포스팅을 참조하시면 되겠습니다.
[머신러닝 with Python] 오차행렬 or 혼동행렬(Confusion Matrix) / 유방암 데이터(Breast Cancer Data) 활용하여 알아보기
[머신러닝 with Python] 오차행렬 or 혼동행렬(Confusion Matrix) / 유방암 데이터(Breast Cancer Data) 활용하여
이번에 알아볼 것은 지난 시간에 알아본 정확도 및 기타 분류평가지표를 도출할 수 있는 오차행렬 또는 혼동행렬이라 불리는 Confusion Matrix에 대해서 알아보겠습니다. 1. 오차행렬 / 혼동행렬 (Conf
jaylala.tistory.com
'머신러닝 with Python' 카테고리의 다른 글
| [머신러닝 with Python] 앙상블(Ensemble) 학습 (4) / XGBoost (0) | 2023.09.13 |
|---|---|
| [머신러닝 with Python] 앙상블(Ensemble) 학습 (3) / 부스팅(Boosting) / GBM (0) | 2023.09.12 |
| [머신러닝 with Python] 앙상블(Ensemble) 학습 (1) / 보팅(Voting) (0) | 2023.09.10 |
| [Python 언어비교] 텐서플로우(Tensor Flow) vs 파이토치 (Pytorch) / Python 코드를 통한 비교포 (0) | 2023.09.09 |
| [머신러닝 with Python] 결정 트리(Decision Tree) (2/2) / 과적합(Over-fitting) (0) | 2023.09.08 |




댓글