이번에 알아볼 것은 불균형 데이터(Imbalanced Data) 처리에 대해서 알아보겠습니다.
불균형 데이터는 모델 학습에 좋지 않은 영향을 미치게되어 그 모델의 신뢰성을 떨어뜨리곤 하는데요.
그렇다면, 불균형 데이터가 가지고 있는 문제는 무엇이며, 이를 해결하기 위한 방법 중 오버샘플링에 대해서 알아보겠습니다.
추가적으로, 오버샘플링 기법 중 많이 활용되는 SMOTE(Synthetic Miniority Oversampling Technique)에 대해 알아보겠습니다.
1. 불균형 데이터와 불균형 데이터의 문제점
- 불균형 데이터(Imbalanced Data)란, 불균형한 클래스 분포를 가진 데이터셋을 말합니다.
- 불균형한 클래스 분포란, 하나의 클래스가 다른 클래스보다 훨씬 더 많은 샘플을 가지고 있는 경우를 말하며, 이런 경우 모델은 다수 클래스에 치우쳐 학습을 하게되어 소수 클래스에 대한 성능이 저하될 수 있습니다.
- 불균형 데이터가 모델 학습에 미치는 영향을 정리하면 아래와 같습니다.
a) 클래스 불균형 편향: 불균형한 데이터셋에서 모델은 일반적으로 다수 클래스에 더 많은 주의를 기울입니다. 이로 인해 모델은, 다수의 클래스를 잘 학습하지만 소수 클래스에 대한 성능이 저하될 수 있습니다. b) 모델 평가의 오류: 불균형 데이터셋에서 모델의 성능을 평가할 때 주의가 필요합니다. 정확도(accuracy)는 클래스 불균형으로 인해 잘못된 해석으로 유도할 수 있으며, 이로 인해 모델의 성능을 과대평가할 수 있습니다.
* 예를 들어, 90개의 강아지 클래스와 10개의 고양이 클래스가 있는 데이터를 가지고 모델을 학습시키고 평가하는 경우, 해당 모델이 아무 기준없이 "강아지"라고만 분류해도 90%의 정확도를 가지게 됩니다. 즉, 정확도가 90%가 되더라도 해당 모델은 좋은 분류성능을 가졌다고 말할 수 없습니다. c) 클래스 불균형을 다루지 않는 모델의 불안정성: 일부 모델은 클래스 불균형을 처리하지 않고 학습하면 불안정해질 수 있습니다.
* 예를 들어, 로지스틱 회귀와 같은 선형 모델은 클래스 불균형에 민감할 수 있습니다. d) 소수 클래스의 분류 오류: 모델은 소수 클래스에 속하는 샘플을 제대로 분류하지 못할 수 있습니다. 즉, 모델이 소수 클래스를 무시하거나 잘못 예측할 수 있습니다. e) 샘플 수 부족: 소수 클래스의 샘플 수가 너무 적으면 모델이 해당 클래스를 제대로 학습하기 어려울 수 있습니다. 이로 인해 모델이 일반화 성능을 제대로 내지 못할 수 있습니다.
- 위와 같은 문제를 해결하기 위한 대표적인 방법은, 소수의 클래스의 숫자를 증가시키는 오버샘플링(Over Sampling)과 다수의 클래스 숫자를 줄이는 언더샘플링(Under Sampling)이 있습니다.
- 이 중 오늘은 오버 샘플링에 대해서 알아보겠습니다.
2. Python 코드를 활용한 오버샘플링(Over Sampling)과 SMOTE
- 먼저 오버샘플링에 대해서 알아보겠습니다.
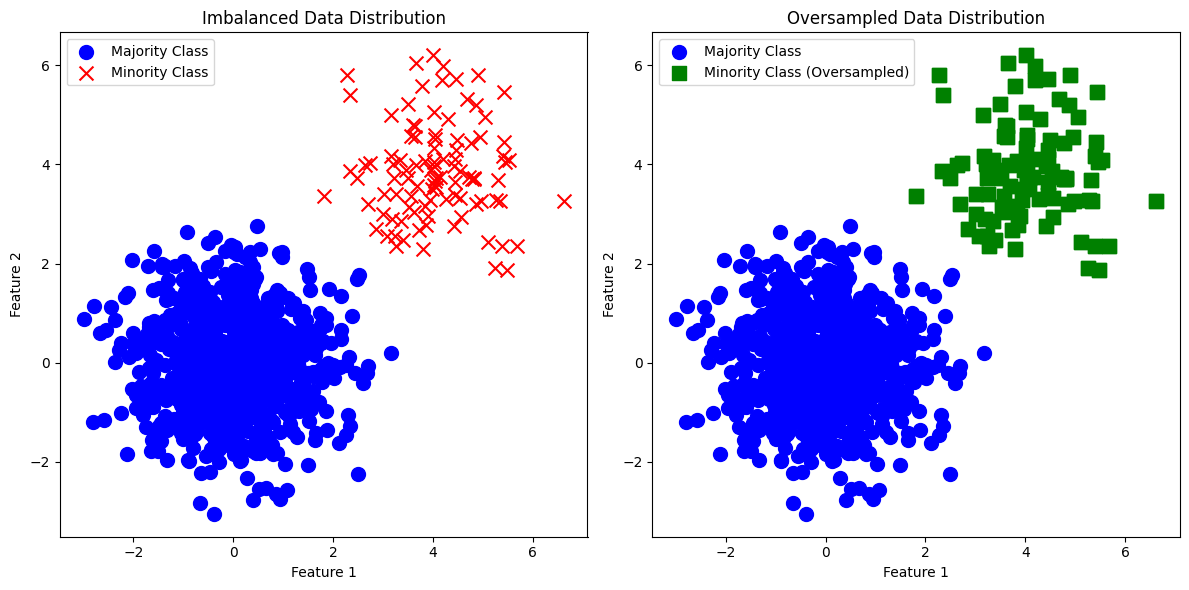
- 오버샘플링은 불균형 데이터의 문제 해결방안 중 소수의 클래스의 데이터를 복제하거나 합성하여 데이터셋의 클래스 분포를 균형있게 만드는 방법을 말합니다.
- 먼저 기본적인 오버샘플링에 대해서 파이썬 코드로 알아보겠습니다.
2-1) 오버샘플링(Over Sampling)
* 임의로 불균형 데이터 군집을 만들기 위해, numpy와 시각화를 위한 matplotlib의 pyplot 라이브러리, 그리고 나중에 갯수 계산을 위한 counter 라이브러리를 불러옵니다.
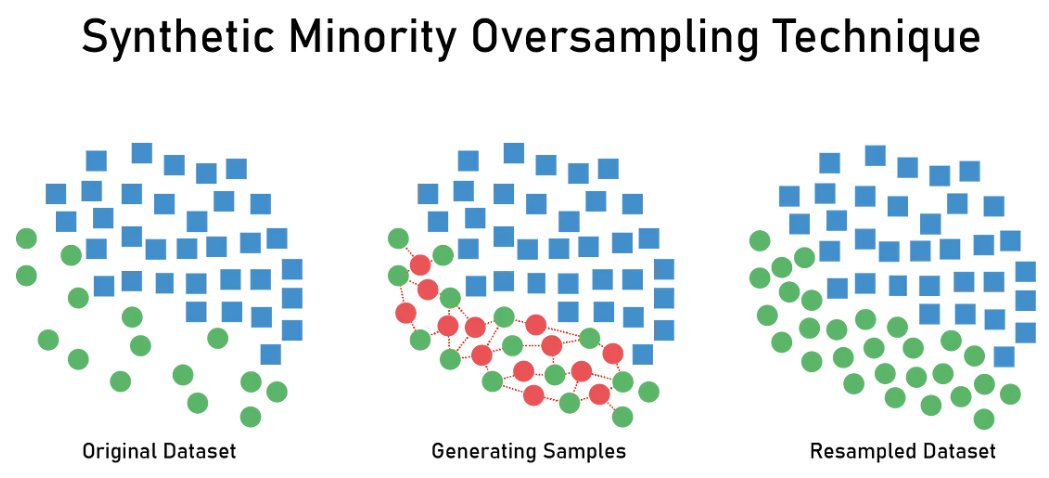
- SMOTE란, 소수 클래스의 샘플을 합성하여 데이터셋을 균형있게 만드는 방법 중 하나입니다.
- SMOTE의 주요 아이디어는 아래와 같습니다.
a) 샘플 합성: SMOTE는 소수 클래스의 샘플을 선택하고, 각 선택된 샘플에 대해 이웃하는 샘플들을 선택합니다. 그런 다음 선택된 샘플과 이웃 샘플 사이의 차이를 계산하여 새로운 합성 샘플을 생성합니다. b) 이웃 샘플 선택: SMOTE는 기존 소수 클래스 샘플 주변의 이웃 샘플을 선택하는데, 이웃 샘플은 k 최근접 이웃(k-nearest neighbors) 알고리즘을 사용하여 찾습니다. c) 샘플 합성 과정: SMOTE는 선택된 소수 클래스 샘플과 그 이웃 샘플 간의 차이를 이용하여 새로운 샘플을 생성합니다. 합성된 샘플은 선택된 샘플과 이웃 샘플 사이의 일정한 비율을 유지하며 생성됩니다.
* 샘플 생성 비율 조절을 위해 SMOTE는 합성 샘플의 수를 조절할 수 있는 파라미터를 제공합니다. 이를 통해 원하는 비율로 오버샘플링을 조절할 수 있습니다. * SMOTE는 원본 데이터를 변형하지 않고 합성된 샘플을 생성하기에 원본 데이터의 변형이 없다는 특징이 있습니다.











댓글