* 예측했던 대로 로지스틱 회귀의 분류 결과는 상승되었으나, Light GBM은 대부분 변화가 없고 AUC 스코어가 오히려 조금 감소한 것을 알수 있습니다.
- 이번에는 Amount를 정규화(Stadardizaion)이 아닌 Log로 변환 시켜보겠습니다. log 함수의 경우 입력값이 클수록 출력값이 이에 비례한 경우보다 더 작게나오는 모습을 보이는데요. 이러한 특성덕분에 데이터 분포도의 왜곡이 큰 경우 이를 해결하는데 자주 사용되는 함수입니다.
* 로지스틱 회귀의 경우 정밀도는 소폭 상승하였으나 재현율은 소폭 감소하였고, AUC 스코어는 상승했음을 알 수 있습니다.
* Light GBM의 경우 정밀도와 재현율이 상승하였고, AUC 스코어도 상승했음을 확인할 수 있습니다.
* 분류 타겟이 되는 변수의 불균형이 심할수록, AUC 스코어를 통한 분류평가가 더 의미가 있는데요, 로그 변환을 했을 경우 두 모델 모두 AUC 스코어가 상승했습니다.
2. 이상치(Outlier) 제거 후 학습 + SMOTE로 오버 샘플링 후 모델 학습/예측/평가
- 이번에는 이상치(Outlier)를 제거 후 학습해보겠습니다.
- 모델 학습과 예측에 사용되는 피쳐들(Features)이 많기때문에 모든 경우에서 이상치를 제거하는 것은 불필요하고, 사기여부에 영향도가 큰 피쳐에 대해 이상치를 제거 후 학습시켜보겠습니다.
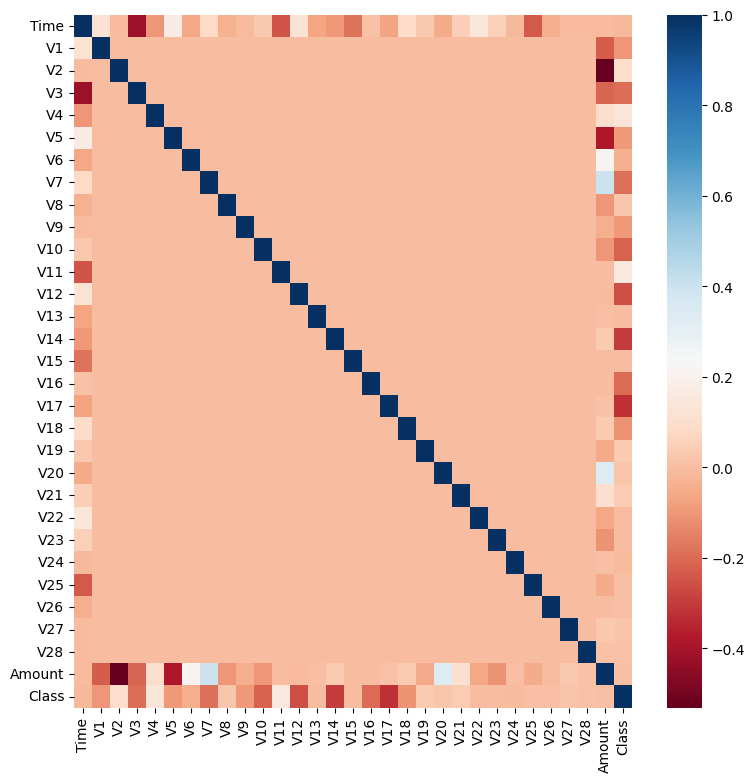
- 이를 위해 전체 데이터의 상관관계 Heatmap을 만들어보겠습니다.
import seaborn as sns
plt.figure(figsize=(9,9))
corr = df.corr()
sns.heatmap(corr, cmap='RdBu')
- 히트맵의 색깔에 따라 Class(사기여부)에 대한 연관도를 알 수 있으며, 파랄수록 양의 상관관계가, 적색에 가까울수록 음의 상관관계가 높다는 것을 알 수있습니다.
- Class와 음의 상관관계가 가장 높은 피처는 V14와 V17입니다. 이 중 V14에 대해서만 처리를 해보겠습니다.
* 해당 데이터 분포에서 1/4지점과 3/4지점의 차이를 나타낸 것을 IQR(Inter Quantile Range)라 하며, 이 IQR을 활용해 이상치를 지정할 때는 IQR에 1.5를 곱한 값을 1/4 분위수에서는 빼주고, 3/4 분위수에서는 더해줘 구간을 만들고, 이 구간을 벗어나는 것을 이상치로 설정하였다.
import numpy as np
defget_outlier(df=None, column=None, weight=1.5):
# fraud에 해당하는 column 데이터만 추출, 1/4 분위와 3/4 분위 지점을 np.percentile로 구함.
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values,25)
quantile_75 = np.percentile(fraud.values,75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
* 로지스틱 회귀의 경우 재현율이 60.81%에서 67.12%로 / Light GBM의 경우 재현율이 76.35%에서 82.88%로 향상되었다. 사기가 발생하는 1건이라도 발생할 경우 문제가 커지는 위와 같은 이진분류에서는 재현율의 상승이 꽤나 중요하다는 점에서 이상치 제거는 매우 유용한 방법 중 하나로 평가해볼 수 있다.
- 다음은 SMOTE로 사기건수에 대한 데이터를 합성하여 오버샘플링 한 뒤 모델을 학습시켜보겠습니다.
* 이를 바탕으로 로지스틱 회귀를 진행하였고, 정확도와 재현율이 급격하게 증가하였지만, 정밀도가 급격히 떨어졌습니다. 이는 로지스틱 회귀 모델이 오버 샘플링으로 인해 실제 원본 데이터의 유형보다 너무나 많은 사기 발생 데이터를 학습하면서 실제 테스트 데이터에서 예측을 지나치게 사기가 발생했다는 것으로 적용하면서 발생한 현상입니다.
- 분류 결정 임곗값에 따른 정밀도와 재현율 곡선을 통해 SMOTE로 학습된 로지스틱 회귀 모델에 어떤 문제가 발생하고 있는지 시각화 해보겠습니다.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.metrics import precision_recall_curve
* 임계값이 0.99이하에서는 재현율이 좋고 정밀도가 극단적으로 낮다가 0.99 이사에서는 반대로 재현율이 대폭 떨어지고 정밀도가 높아집니다. 분류 결정 임계값을 조정하더라도 임계값의 민감도가 너무 심해 올바른 재현율/정밀도 성능을 얻을 수 없으므로 로지스틱 회귀 모델의 경우 SMOTE 적용 후 올바른 예측 모델이 생성되지 못했음을 알 수 있습니다.

















댓글