
지난 시간에는 PDFPlumber를 활용해서 pdf 파일 내의 이미지에 대해서 추출해보았는데요.
이번에는 pdf파일내의 표(Table)을 추출해보도록 하겠습니다
PDFPlumber에 대한 전반적인 내용은 지난 포스팅을 참조해주시면 되겠습니다.
[업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (1)
**아래 작성되는 코드는 결과의 재현성을 위해 구글 코랩 무료버전을 활용해서 작성했습니다.**
1. PDFPlumber를 활용한 표(Table) 추출
- 먼저, 실습에 활용할 데이터를 다운로드 받아주겠습니다.
* 이번에 활용할 데이터는 PDFPlumber에서 예재로 제공하는 ca-warn-report 로 아래 그림과 같습니다.
* 해당 pdf 파일은 여러 page로 구성되어 있습니다.
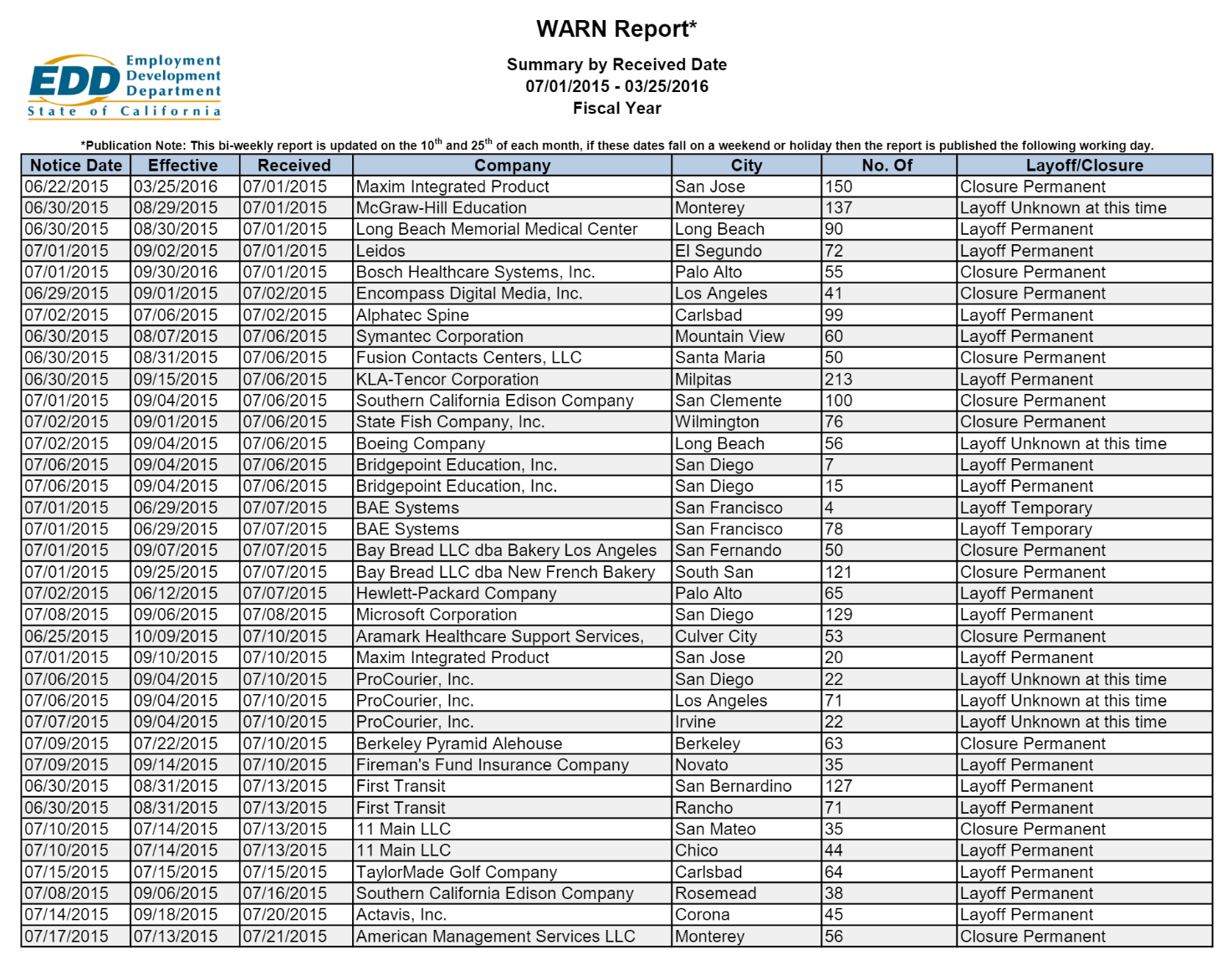
* 위 데이터를 다운로드 받기 위해서는 아래 링크에 들어가셔서 다운로드 받으시면 되겠습니다.
pdfplumber/examples/notebooks/extract-table-ca-warn-report.ipynb at stable · jsvine/pdfplumber
Plumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily extract text and tables. - jsvine/pdfplumber
github.com
-이제 pdfplubmer 패키지를 설치해줍니다.
- 이후, pdfplumber를 import 해주고, 데이터를 불러옵니다.
- 잘 load 되었는지 확인하기 위해 첫번째 페이지를 불러와봅니다.
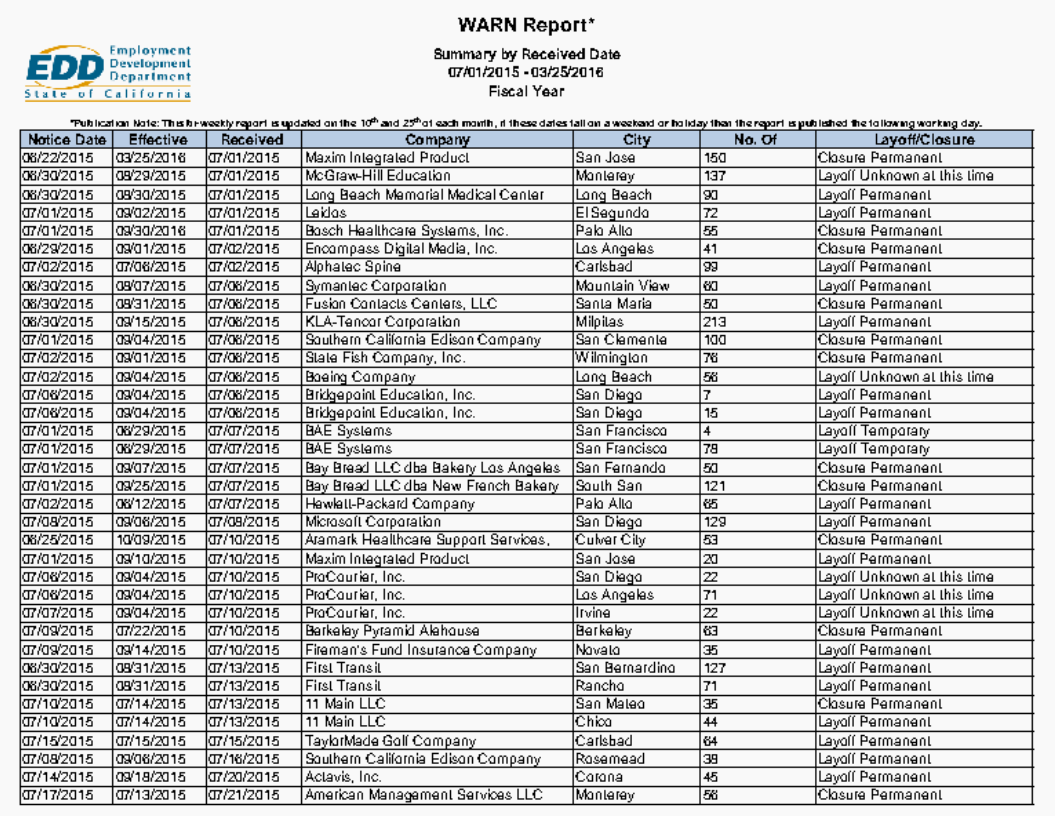
* 첫번째 페이지가 잘 load 된 것을 확인할 수 있습니다.
-이제 extract_table 함수를 활용해 표에 대한 정보들을 추출해줍니다. 그리고 잘 되었는지 확인하기 위해 표의 3번째 줄까지 출력해봅니다.
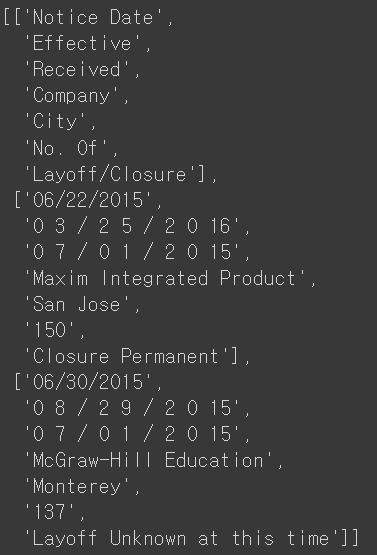
* 표 정보들이 잘 추출된 것을 확인할 수 있습니다.
- 이제 이렇게 추출된 정보들을 가공하기위해 pandas를 활용해서 dataframe의 형태로 만들어줍니다. 그리고 10번째 행까지의 데이터들을 출력해봅니다.

* 잘 도출되는 것을 확인할 수 있습니다. 이제 원하는 작업들을 진행하시면 되겠습니다.
- 마지막으로, 정말 잘 도출했는데 debuging 코드를 사용해 어떤 부분들을 인식해서 표로 정리했는지 확인해보겠습니다.
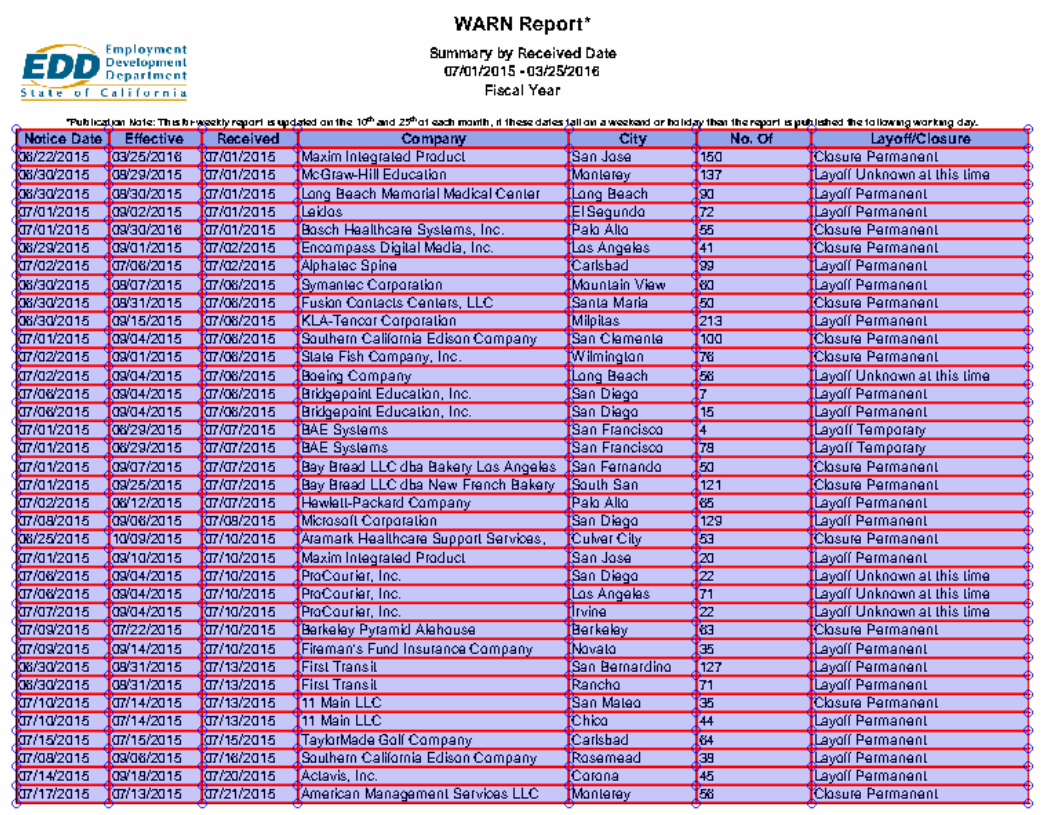
* 지난번 그림을 도출했었던 것처럼, 표도 빠짐없이 잘 인식하고 있음을 알 수 있습니다.
'업무자동화 with Python' 카테고리의 다른 글
| [업무자동화 with Python] PDF Plumber로 PDF 표 추출하기 (실습) (1) | 2024.12.08 |
|---|---|
| [업무자동화 with Python] Pytesseract를 활용한 OCR (Optical Character Recognition) (6) | 2024.11.06 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (4) (표 추출) (1) | 2024.10.22 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (3) (표 추출) (0) | 2024.10.21 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (1) (그림 추출) (3) | 2024.10.19 |




댓글