
업무간, PDF로 보내온 대량의 문서의 내용을 정리해야할 때 많은 스트레스를 받아본 경험이 있으실 겁니다.
저는 이러한 상황에서, 웹사이트에서 제공해주는 무료 PDF to excel 변환기나, ChatGPT등 생성형 AI로 이를 처리하려고 했을때 내가 원하는 형태의 정보로 가공되지 않았던 경험이 종종 있었는데요.
그래서 위와 같은 사이트들의 근간이 되는 알고리즘에 대해서 확인해보자는 마음으로 PDF 문서내용을 추출하는 Python library에 대해서 알아보았습니다.
이번에 활용할 Library는
PDFPlumber입니다.
https://github.com/jsvine/pdfplumber
GitHub - jsvine/pdfplumber: Plumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily ext
Plumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily extract text and tables. - jsvine/pdfplumber
github.com
1. PDF Plumber란?
- PDF Plumber는 PDF 문서의 내용을 효율적으로 추출할 수 있는 파이썬 라이브러리로,
단순한 텍스트 추출뿐만 아니라, PDF 파일내의 표, 이미지, 글자 위치 등 다양한 정보를 구조적으로 분석하고 추출하는 기능을 제공합니다.
- PDF는 포맷이 복잡한 경우가 많기 때문에 PDFPlumber는 표 또는 복잡한 레이아웃이 있는 PDF에서 데이터를 추출할 때 유용하여, 일반적인 PDF 추출 사이트나 ChatGPT와 같은 생성형 AI가 잘 하지 못하는 부분들도 해낼 수 있습니다.
* ChatGPT의 경우, 여러기능 중 이미지 인식 및 추출 기능이 탑재되어있는 형태이기에 특화된 라이브러리를 우리가 원하는대로 커스터마이징 하기에는 종종 제한이 생깁니다.
- 그렇기에 업무에 있어서 활용하고 싶은 정보를 원하는 방법대로 추출할 수 있다는 장점이 있습니다.
2. PDF Plumber를 활용한 문서내용 추출 (이미지 내 곡선 추출) (ChatGPT 결과와 비교)
- 이번 분석에 활용한 파일은 PDFPlumber github에서 제공하고 있는 예제 파일 중 하나인
"ag-energy-round-up-2017-02-24" 이라는 파일입니다.
- 파일의 형태는 아래와 같습니다.
1) ChatGPT를 활용한 결과
- 먼저, 유료버전의 ChatGPT4o에 해당 파일에서 곡선에 해당하는 부분에 대한 정보 및 표시를 달라고 해보았습니다.
* 개략적인 정보는 잘 요약한것 같습니다. 하지만, 원하는 곡선에 대한 정보를 제공하지는 않았습니다. 그래서 다시 물어보았습니다.

* 아래 그림처럼 결국 GPT도 pdfplumber를 활용하려고 하지만, 내장된 라이브러리가 아니다 보니 자꾸 분석 오류가 나고 코드만 제공하게 됩니다.
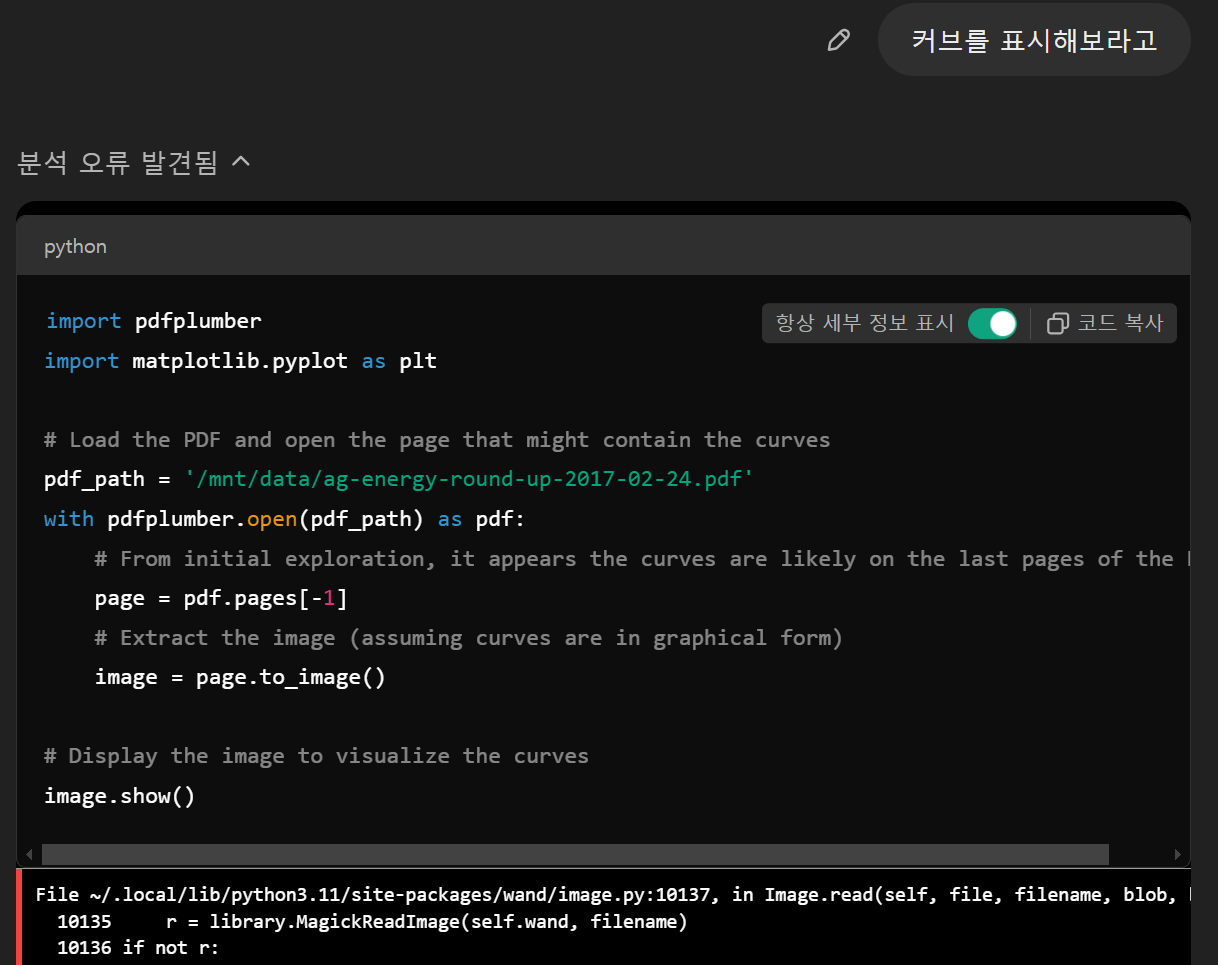
* 결국 오류 수정 및 분석끝에 다음과 같은 결과를 주지만, 우리가 제시했던 파일의 모습과는 다른 형태입니다.

2) PDFPlumber 활용
- 결국 PDFPlumber를 활용해야하는 시점이 오게 되었습니다.
- 파이썬을 활용할 때 VSCode나 파이참 등 다양한 형태를 활용하시겠지만, 어디서든 동일한 결과를 얻을 수 있게 코드 구현은 코랩에서 진행했습니다. (GPU를 따로 사용하지 않기에 무료버전으로도 이상없이 구현가능합니다)
(코드 실행 전, https://github.com/jsvine/pdfplumber/blob/stable/examples/pdfs/ag-energy-round-up-2017-02-24.pdf
pdfplumber/examples/pdfs/ag-energy-round-up-2017-02-24.pdf at stable · jsvine/pdfplumber
Plumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily extract text and tables. - jsvine/pdfplumber
github.com
에 들어가서 파일을 다운로드 받아준 뒤, 구글 드라이브에 업로드 해주어야합니다.)
- 먼저, 아래와 같이 구글 드라이브에서 "드라이브 마운트" 버튼을 클릭해서 공유 동의를 해준뒤 드라이브를 마운트해줍니다.
(또는 아래 코드를 실행해줍니다)
- 이후 pdfplumber 패키지를 설치해줍니다.
- 다음은 설치된 pdfplumber를 불러오고 버전을 확인해줍니다. 제가 구현하는 시점의 버전은 0.11.4 입니다.
- 이후 pdfplumber를 활용해 파일을 읽어주고, to_image를 활용해 이미지를 출력해봅니다. 첫번째 페이지를 출력하위해 [0]을 넣었습니다(예제 파일은 page가 1개 밖에 없긴 합니다.)
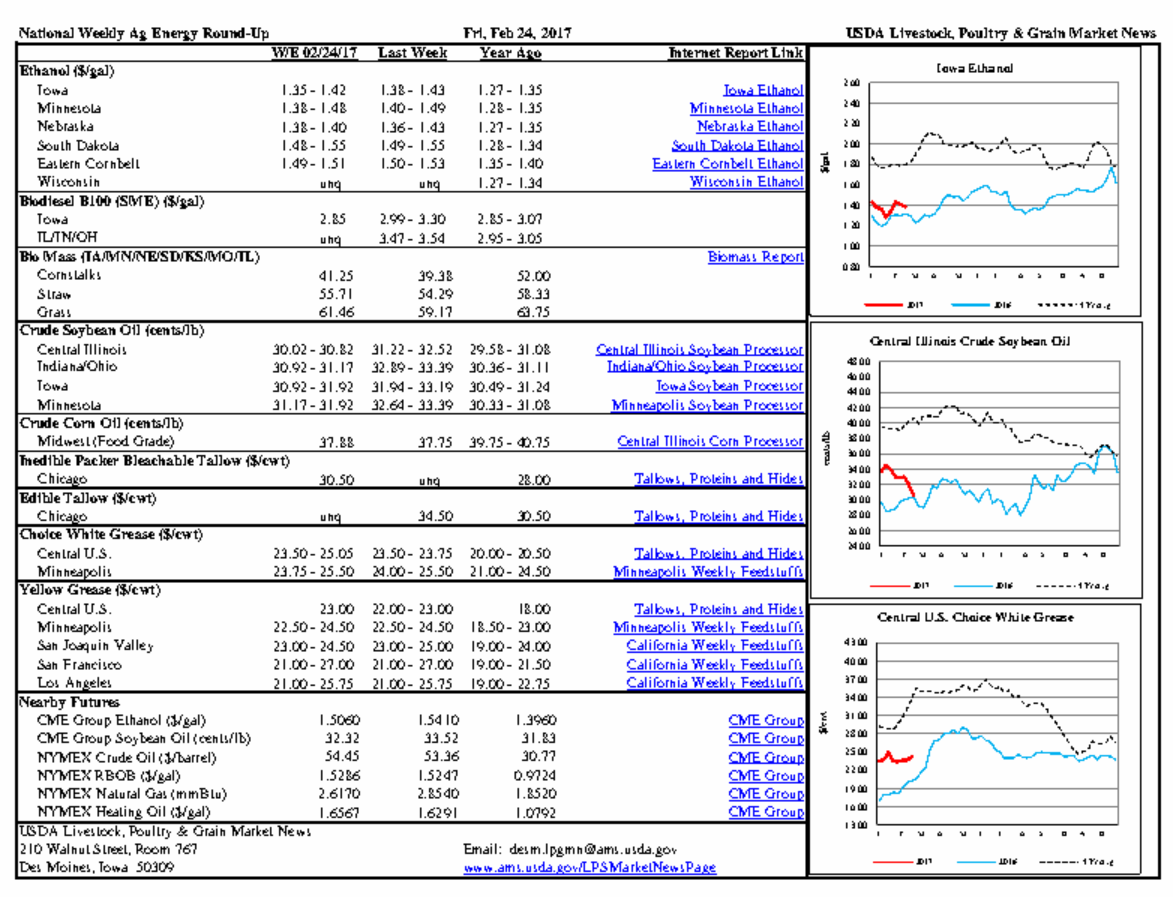
- 파일을 보시면 곡선(curve)이 포함되어 있는 그림이 있는데 이때 곡선이 몇개있는지 추출해보겠습니다.

* 총 9개라는게 잘 추출됩니다.(각 표별로 3개씩)
- 각 curve에 대한 정보가 어떻게 있는지 확인해보겠습니다.
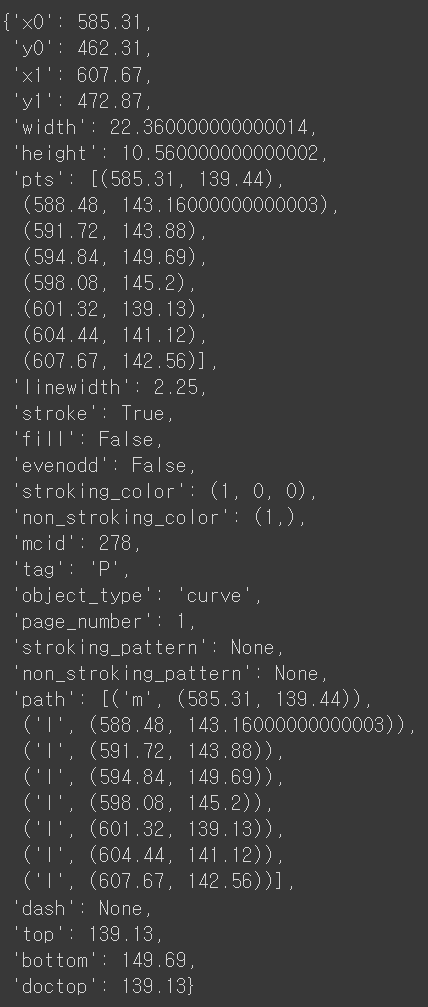
* 첫번째 커브에 대한 정보입니다. 아래 결과와 같이 좌표, 높이, 너비, 각 점들의 위치등 다양한 정보가 도출됩니다.
- 정말 제대로 추출했는지 해당 파일위에 표시를 해보겠습니다. 초록색으로 곡선을 표시해달라고 했으며, 너비는 3입니다.
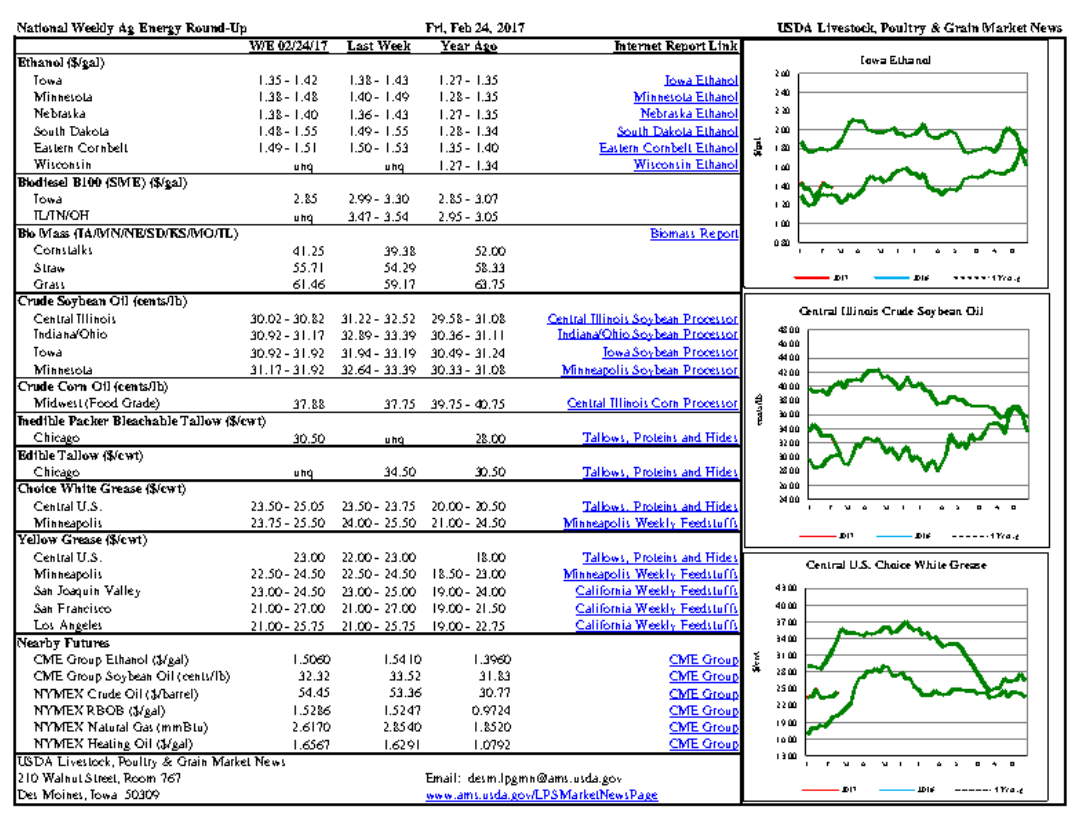
* 그림 상 9개의 커브에 3의 두께를 가진 선으로 덫칠한 결과입니다. 잘 인식하는 것 같습니다.
- 똑같은 색으로 했기때문에 제대로 인식했는지 확인이 잘 안되는데, 이번에는 각 종류별로 색깔을 다르게 해보겠습니다. 또한 표시도 구분되게 하기 위해 cricle로 표시해보면 다음과 같습니다.

- 또한, 수평선을 더 세분화해서 인식시킬 수도 있습니다.
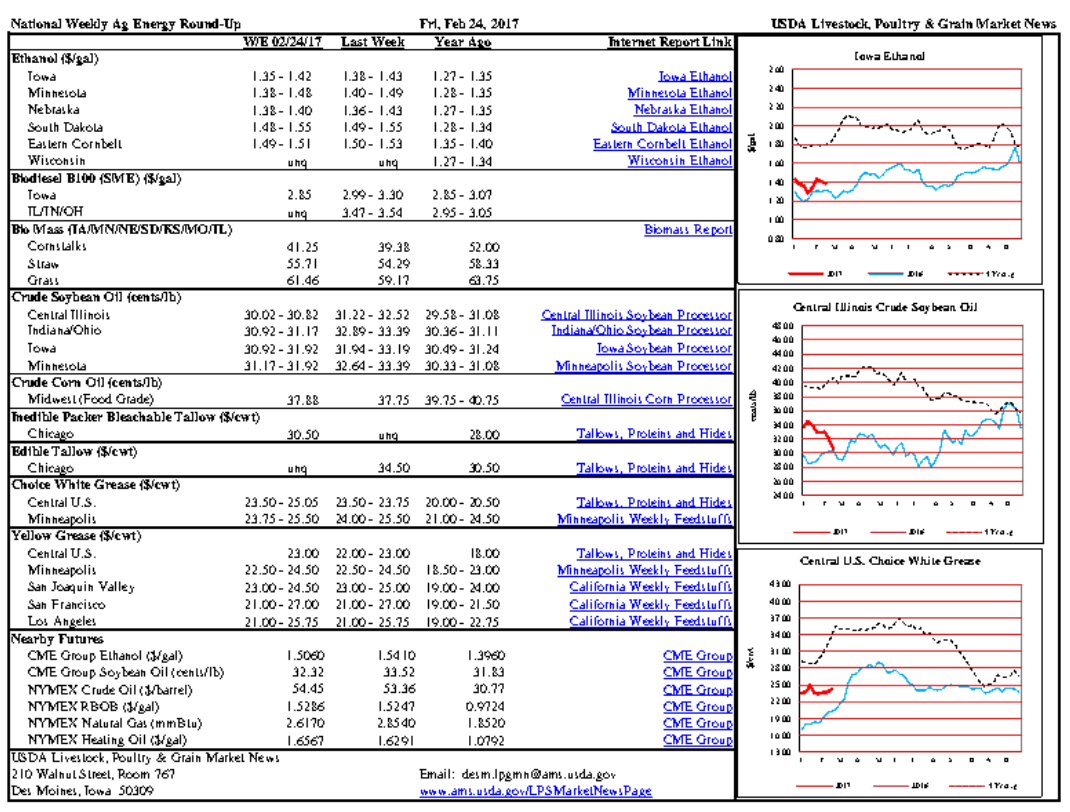
위와 같이 파이썬 코드를 통해서 pdfplumber를 구현해보았습니다.
이번에는 pdf 내의 그림을 얼마나 잘 인식하는지, 그리고 그 그림에 대한 정보 추출은 어떻게 되는지를 알아보았습니다.
추출된 정보를 활용해서 파이썬을 활용해 그림을 재현해볼 수도 있으며 여러모로 활용해 볼 수 있습니다.
다음시간에는 표 정보 등에 대해서 추출해보는 시간을 가져보겠습니다.
'업무자동화 with Python' 카테고리의 다른 글
| [업무자동화 with Python] PDF Plumber로 PDF 표 추출하기 (실습) (1) | 2024.12.08 |
|---|---|
| [업무자동화 with Python] Pytesseract를 활용한 OCR (Optical Character Recognition) (6) | 2024.11.06 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (4) (표 추출) (1) | 2024.10.22 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (3) (표 추출) (0) | 2024.10.21 |
| [업무자동화 with Python] PDF문서내용 추출(PDFPlumber 활용) (2) (표 추출) (2) | 2024.10.20 |




댓글