
이번 시간에는 간단한 코드 몇 줄만을 가지고 멜론차트 데이터를 가져오는 실습을 해보겠습니다.
실습은 재현성을 위해 코랩 무료버전에서 진행했으며, 이번 실습간에는 별다른 패키지 없이 코랩에 내장된 패키지들을 그대로 활용하기에 정말 쉽고 간단합니다.
1. 웹크롤링을 통해 멜론차트 데이터 가져오기
- 멜론차트와 같은 표(Table)의 형태로 되어있는 웹페이지를 발견하시면 아래와 같은 방법으로 쉽게 데이터를 크롤링 하실 수 있습니다.
- 먼저, 데이터를 얻고 싶은 사이트를 들어가줍니다. 이번 실습간에는 멜론차트를 활용해보겠습니다.
https://www.melon.com/chart/index.htm
Melon
음악이 필요한 순간, 멜론
www.melon.com

* 해당 페이지는 24년 10월 16일 13시를 기준으로 되어있는 차트입니다.
- 이제 구글 코랩을 실행시켜 줍니다.
- 이후, 아래와 같이 코드를 작성 후 실행시켜줍니다.
* pandas는 데이터를 데이터프레임화 시키기 위해 활용해줍니다.
* request는 웹 페이제이서 HTTP 요청을 보내고 응답을 받기 위해 사용합니다.
* BeautifulSoup은 HTML 코드를 구분 분석하여 원하는 정보를 추출하는데 사용합니다.
* StringIO : 문자열 데이터를 파일처럼 처리하기 위해 사용하며, pandas의 pandas.read_html에서 사용하기 위해 HTML 문자열을 감싸줍니다.
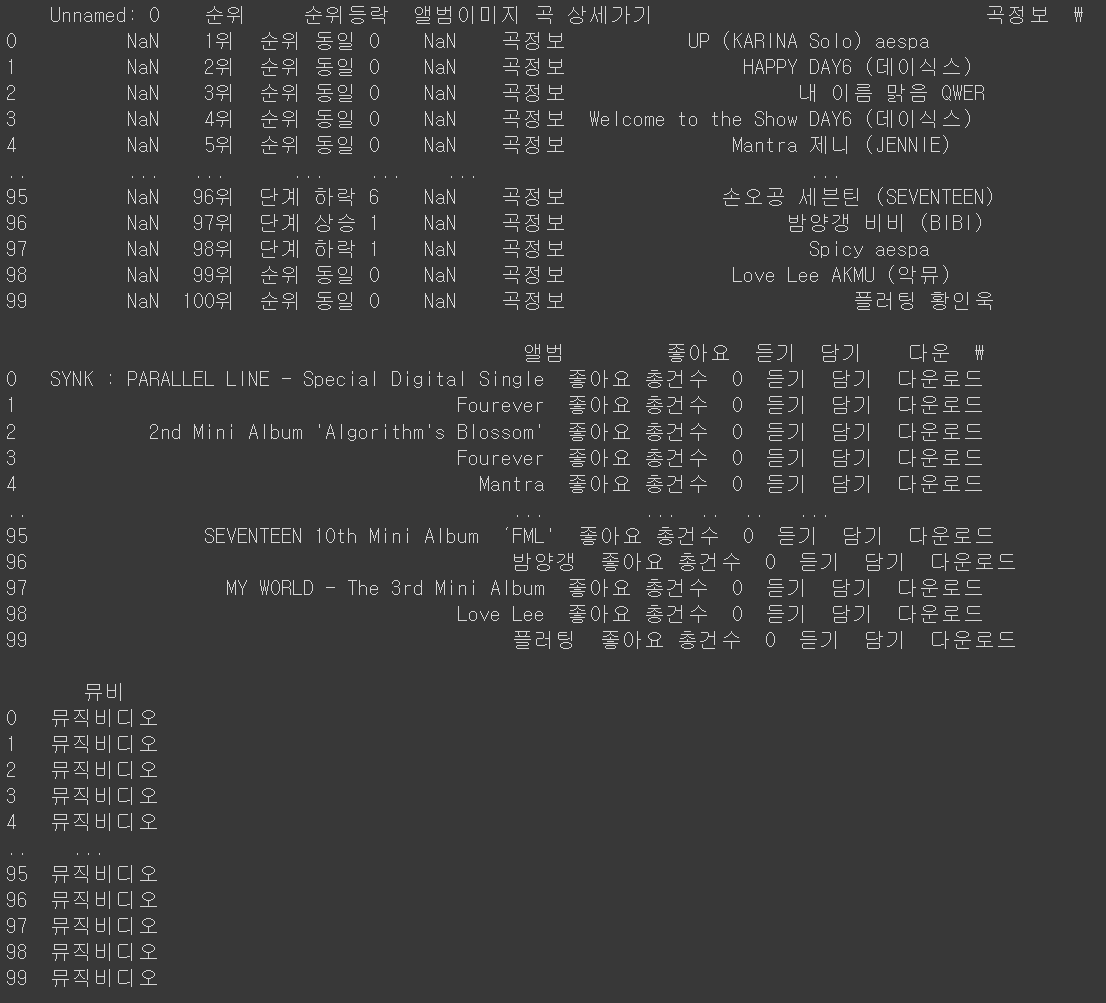
* 데이터를 전반적으로 잘 가져온것 같지만 원하지 않는 열들이 있는 것을 확인할 수 있습니다.
- 데이터의 열 제목들은 어떻게 저장되었는지 확인해보겠습니다.

* 위와 같이 페이지에 표시된 부분들을 잘 가져온것을 알 수 있습니다.
- 이 중에서 의미있는 정보인, 순위 / 순위등락 / 곡정보 / 앨범 / 좋아요 만을 선택해서 데이터를 구성해보겠습니다.
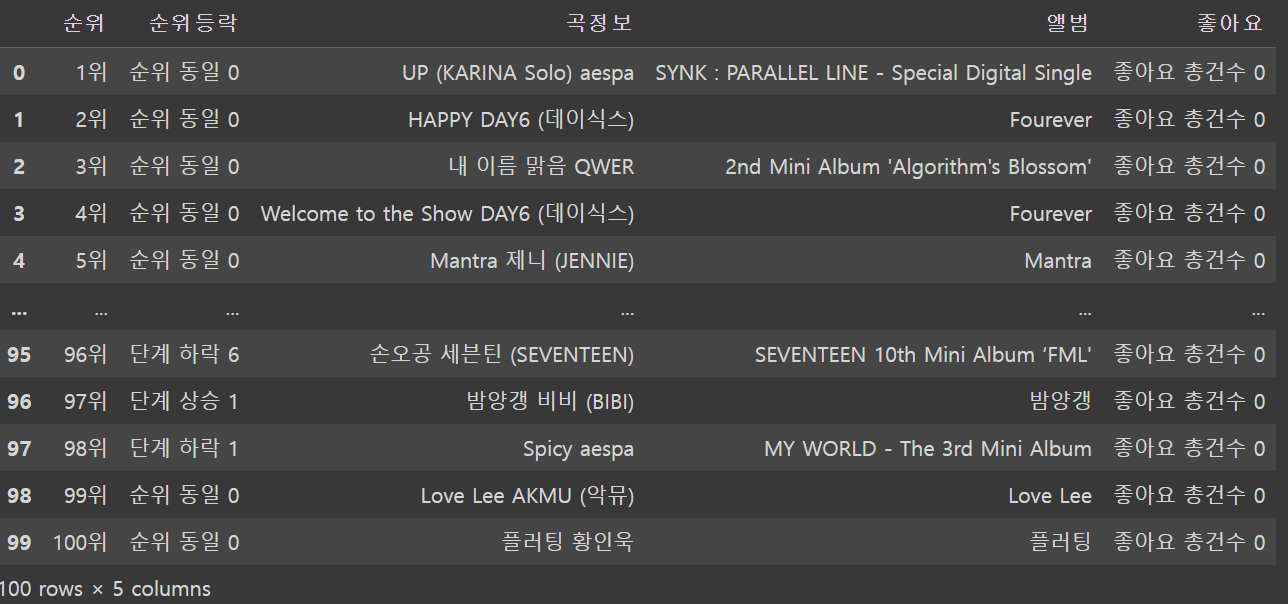
* 결과를 보면 전반적으로 데이터를 잘 가져온 것을 알 수 있습니다. 다만, 좋아요 부분에서는 실제 좋아요 건수를 가져오지 못했는데, 이 부분에 대해서는 추가적인 분석이 필요할 것 같습니다.
'웹크롤링 with Python' 카테고리의 다른 글
| [웹크롤링 with Python] 페이지에서 원하는 정보들 추출하기 / GlobalFirePower 사이트 정보 추출해보기 (0) | 2024.06.15 |
|---|---|
| [웹크롤링 with Python] 동적크롤링 / 네이버뉴스 썸네일 다운로드 (1) | 2024.06.13 |
| [웹크롤링 with Python] CNN 뉴스 기사 제목 및 본문 크롤링 (0) | 2024.06.12 |



댓글