
이번에는 지난 번에 알아본 정보들을 바탕으로 페이지 내에 있는 특정 정보들에 대해서 크롤링하고 데이터프레임으로 정리해보는 시간을 가져보도록 하겠습니다.
오늘 크롤링을 해 볼 사이트는
GlobalFirePower
입니다.

해당 사이트는 2006년부터 매년 본인들의 기준으로 세계 각국의 군사력 지수를 산정하여 발표하는 사이트인데요
최근에는 군사력지수 뿐만 아니라 이를 계산할때 사용했던 제반적인 정보들까지 제공하기에 여러 유용한 정보들이 국가별로 잘 정리되어있다고 볼 수 있겠습니다.
이번에 크롤링 해볼 페이지는 아래와 같습니다.
https://www.globalfirepower.com/countries-listing.php
2024 Military Strength Ranking
Ranking the nations of the world based on current available firepower.
www.globalfirepower.com

해당 페이지의 일부는 위에서 보시는 것처럼 각 국가의 이름과 해당 국가의 Power Index를 제시하고 있는 페이지 입니다.
총 145개국의 정보가 들어가 있는데 이를 추출해서 정리해보도록 하겠습니다.
크롤링을 익히기 위해 3가지의 단계로 나누어서 진행해보겠습니다.
1단계. 국가 이름을 순서대로 추출해보기
먼저 해당 페이지에서 국가이름에 해당하는 부분에 마우스 우측 버튼을 클릭하여 html 태그의 형식을 확인해봅니다.
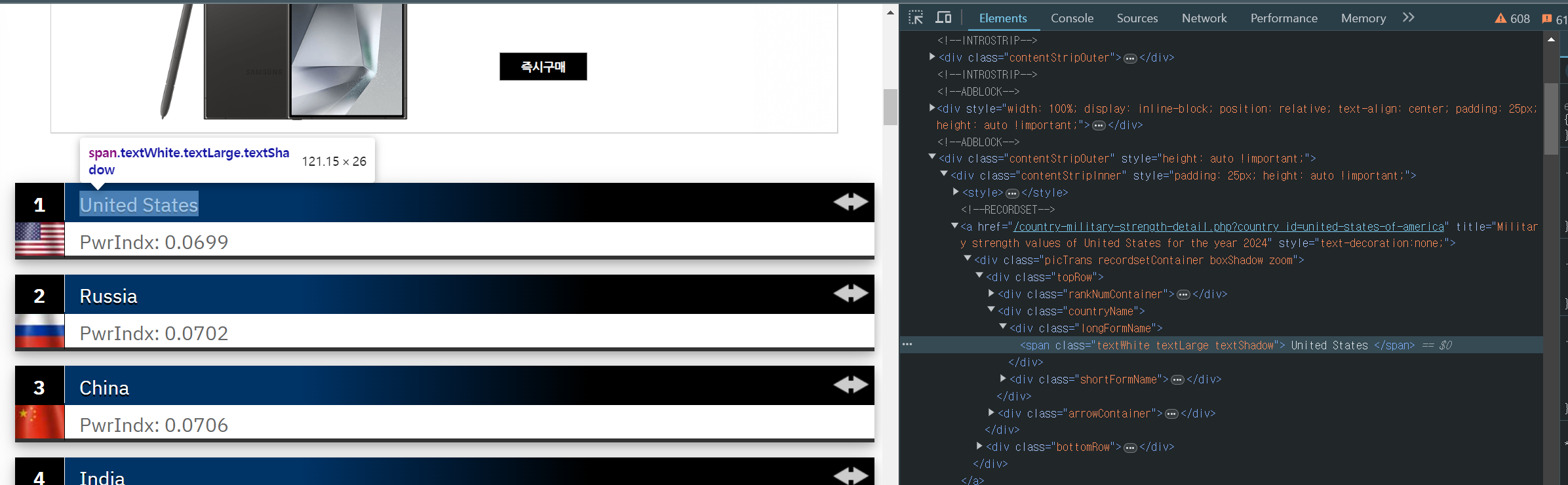
해당 부분을 확인해보니 textWhite.textLarge.textShadow 라는 부분으로 구성되어 있음을 알 수 있는데요. 다른 나라의 이름도 동일한 형식인지 확인해보겠습니다.
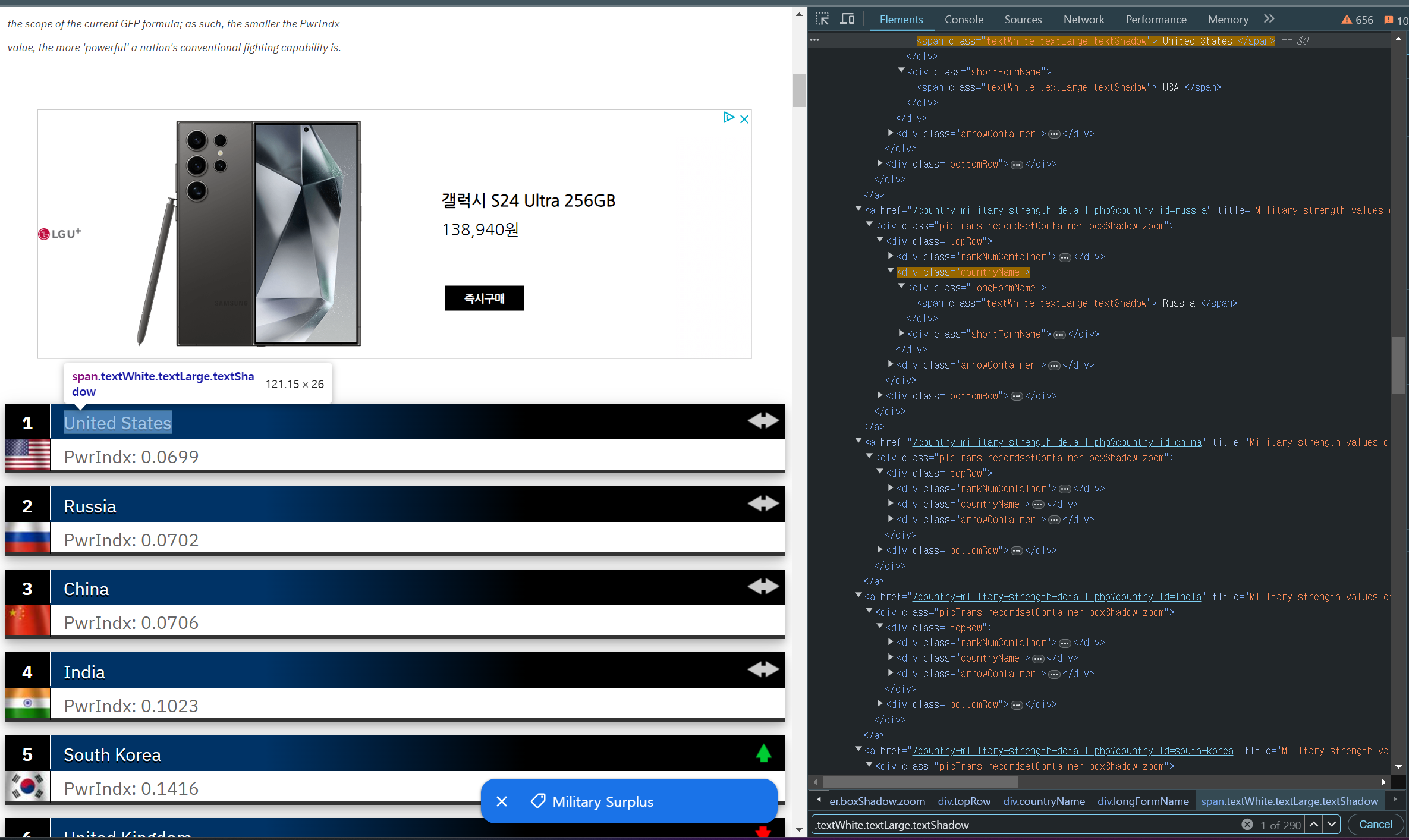
"검사" 창에서 ctrl + f 를 눌러서 textWhite.textLarge.textShadow라는 부분에 각국의 명들이 할당되어 있는 것을 확인할 수 있습니다.
이를 활용하여 간단하게 코딩하여 리스트를 추출해보겠습니다.
import requests
from bs4 import BeautifulSoup
# Global Firepower 웹사이트에서 데이터 가져오기
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 국가 이름을 포함하는 요소 선택
items = soup.select(".textWhite.textLarge.textShadow")
# 각 국가 이름을 추출하여 출력 (약어 제외)
countries = []
for item in items:
country = item.text.strip()
countries.append(country)
print(len(countries))
countries
결과는 아래와 같이 국가명과 약어가 반복되는 순으로 나오게 됩니다. 그래서 총 145개국에 대한 리스트여서 길이가 145가 아니라 그 2배(국가명 1 + 약어 1)인 290개가 나오게되었습니다.
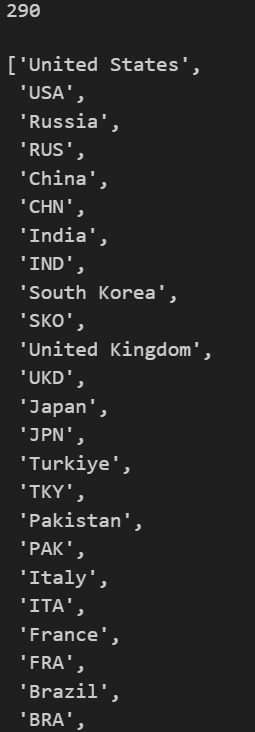
그래서 이번에는 글자가 3글자 초과인 것들만 취하는 로직을 추가해보겠습니다.
import requests
from bs4 import BeautifulSoup
# Global Firepower 웹사이트에서 데이터 가져오기
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 국가 이름을 포함하는 요소 선택
items = soup.select(".textWhite.textLarge.textShadow")
# 각 국가 이름을 추출하여 출력 (약어 제외)
countries = []
for item in items:
country = item.text.strip()
if len(country) > 3: # 약어 제외 (길이 3 이하인 항목 제외)
countries.append(country)
print(len(countries))
countries
원하는 결과가 나왔습니다.

이제 해당 국가들의 인덱스에 대해서 추출해보겠습니다.

이번에는 textLarge.textGray 라는 html 태그에 편성되어있는 것을 확인할 수 있습니다.
위와 동일하게 진행해줍니다. 이때 선행으로 진행해보니 PWRInDx : 라는 문자들이 포함되기에 정규식을 활용해 문자들을 제거하고 숫자만 취하는 조건을 추가해주었습니다.
import requests
from bs4 import BeautifulSoup
import re
# Global Firepower 웹사이트에서 데이터 가져오기
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 수치를 포함하는 요소 선택
items = soup.select(".textLarge.textLtGray")
# 수치 데이터를 추출하여 출력
PwrIndx = []
for item in items:
power_index = item.text.strip()
# "PwrIndx: " 제거하고 숫자만 추출
number = re.sub(r'PwrIndx: ', '', power_index)
PwrIndx.append(number)
print(len(PwrIndx))
print(PwrIndx)
원하는 결과가 나왔습니다.

이제 이 두가지를 한번에 해보겠습니다. 한쌍씩 동일한 논리로 진행하면 통합된 결과가 나오게 됩니다.
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
# Global Firepower 웹사이트에서 데이터 가져오기
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 국가 이름을 포함하는 요소 선택
country_items = soup.select(".textWhite.textLarge.textShadow")
# 수치를 포함하는 요소 선택
pwrindx_items = soup.select(".textLarge.textLtGray")
# 국가 이름과 파워 인덱스 추출
countries = []
for item in country_items:
country = item.text.strip()
if len(country) > 3: # 약어 제외 (길이 3 이하인 항목 제외)
countries.append(country)
# 수치 데이터를 추출
pwrindx = []
for item in pwrindx_items:
power_index = item.text.strip()
# "PwrIndx: " 제거하고 숫자만 추출
power_index = re.sub(r'PwrIndx: ', '', power_index)
pwrindx.append(power_index)
# 데이터 프레임 생성
df = pd.DataFrame({
'Country': countries,
'PowerIndex': pwrindx
})
print(df)
원하는 결과가 나왔습니다.

이와 같이 복잡하지 않은 정적인 크롤링 방법을 먼저 익히고, 이를 연계해주는 동적 크롤링을 익히면 우리도 이제 단순 반복업무에서 해방 될 수 있습니다 :)



댓글