반응형

웹 크롤링을 통해 CNN 뉴스 기사를 크롤링하는 방법에 대해서 알아보겠습니다.
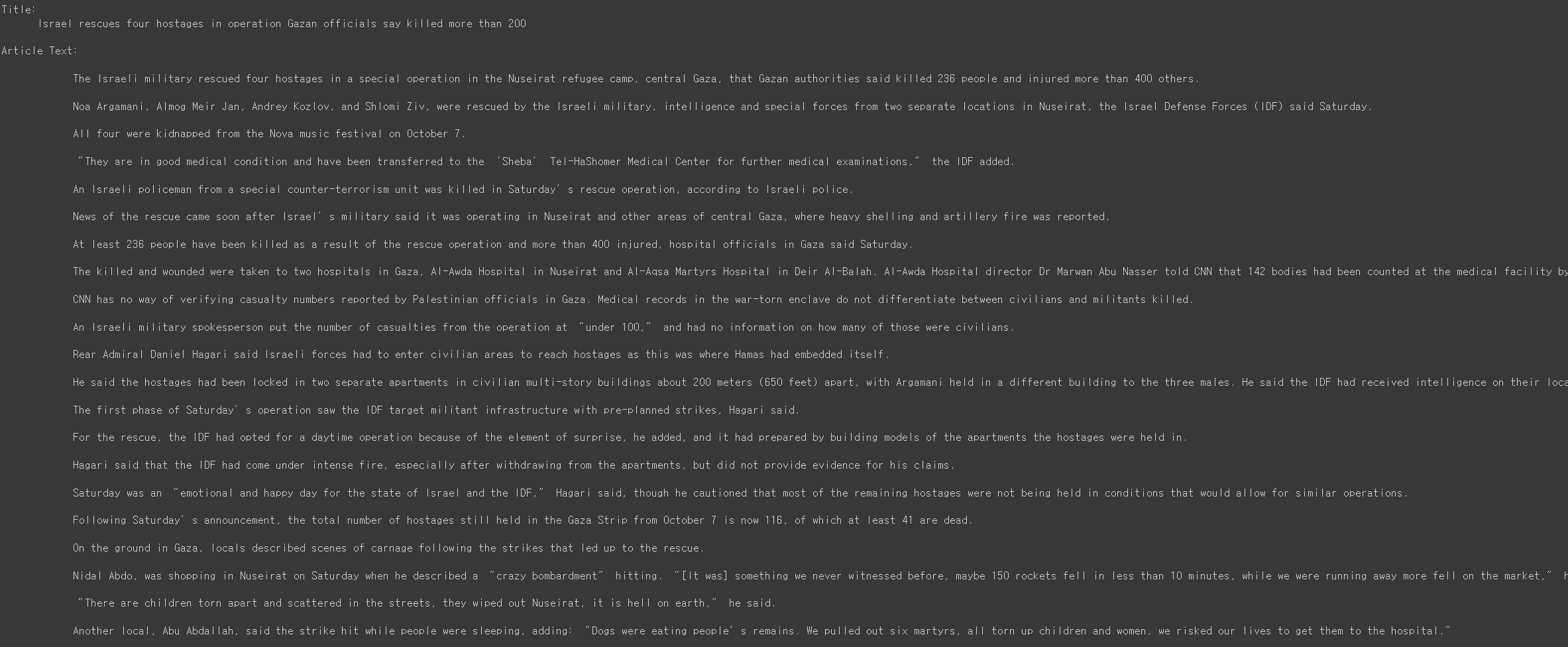
이번 예제는 단일적인 페이지의 제목(Title)과 본문(Article Text)을 크롤링하는 코드를 소개하고자 합니다.
연습을 위해 크롤링하고자하는 페이지는 아래와 같습니다.(CNN 검색을 했을때 가장 첫번째 보이는 아무 페이지나 선택했습니다)
https://edition.cnn.com/2024/06/08/middleeast/four-israeli-hostages-freed-gaza-intl/index.html
제목은 다음과 같습니다.

본문 내용의 일부는 아래와 같습니다.

크롤링을 위해 requests 와 BeatufiulSoup를 활용하겠습니다.
requests는 웹페이지를 요청하기 위해
BeautifulSoup는 html 파싱과 내용을 찾기 위해서 입니다.
결과는 아래와 같습니다.
import requests
from bs4 import BeautifulSoup
# 크롤링할 뉴스 웹사이트 URL
url = "https://edition.cnn.com/2024/06/08/middleeast/four-israeli-hostages-freed-gaza-intl/index.html"
# 웹 페이지 요청
response = requests.get(url)
# 페이지 내용 파싱
soup = BeautifulSoup(response.content, 'html.parser')
# 기사 제목 추출
title_element = soup.find('h1')
if title_element:
title = title_element.get_text()
print(f"Title: {title}")
else:
print("Title not found")
# 본문 텍스트 추출 (예시로 CNN 기사 본문 클래스 사용)
article_body_elements = soup.find_all('div', class_='paragraph')
if not article_body_elements:
article_body_elements = soup.find_all('div', class_='zn-body__paragraph')
if not article_body_elements:
article_body_elements = soup.find_all('p') # 다른 가능한 본문 태그 시도
article_text = ' '.join([paragraph.get_text() for paragraph in article_body_elements])
print("Article Text:")
print(article_text)
반응형
'웹크롤링 with Python' 카테고리의 다른 글
| [웹크롤링 with Python] 멜론차트 데이터 가져오기 (3) | 2024.10.23 |
|---|---|
| [웹크롤링 with Python] 페이지에서 원하는 정보들 추출하기 / GlobalFirePower 사이트 정보 추출해보기 (0) | 2024.06.15 |
| [웹크롤링 with Python] 동적크롤링 / 네이버뉴스 썸네일 다운로드 (1) | 2024.06.13 |



댓글