
이번에는 간단한 비전 트랜스포머 코드를 활용해
CIFAR-100 Dataset에 대한 분류를 해보겠습니다.
Vision Transformer에 대한 이론적인 내용은 아래 포스팅을 참조 바랍니다.
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2)
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2)
이번에 알아보 내용은 Vision Transformer입니다. 해당 모델은 "An Image is worth 16x16 words: Transformers for image recognition at scale" 이라는 논문에서 등장했습니다. 해당 논문은 2021년 ICLR에서 발표된 이후, 많은
jaylala.tistory.com
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2)
[개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (2/2)
지난 포스팅에 이어서 비전트랜스포머(Vistion Transformer/ ViT)에 대해서 알아보겠습니다. [개념 정리] 비전 트랜스포머 / Vision Transformer(ViT) (1/2) 지난 시간에는 인코더 부분에 대해서 알아보았습니다
jaylala.tistory.com
[해당 파이썬 코드는 코랩 환경에서 실행하였습니다]
먼저, keras 모듈을 활용하기 위해 아래 코드를 실행해줍니다.
(미 실행시, ops 모듈이 작동하지 않더군요 ㅜ)
pip install keras-nightly
다음으로 Keras의 백엔드를 JAX로 설정 후 필요한 라이브러리들을 임포트해줍니다.
import os
os.environ["KERAS_BACKEND"] = "jax" # @param ["tensorflow", "jax", "torch"]
import keras
from keras import layers
from keras import ops
import numpy as np
import matplotlib.pyplot as plt
이때, JAX는 구글에서 개발한 라이브러리로, Numpy와 유사한 API를 제공하지만, 자동미분, GPU 및 TPU 가속, 함수 변환(jax.jit, jax.grad, jax.vmap) 등을 사용해 코드를 최적화 할 수 있습니다.
이제 데이터를 로드해줍니다.
CIFAR-100은 100개의 클래스를 가지고 있으며, input shape는 다음과 가로 32, 세로 32의 픽셀, 3개의 색상 채널(RGB)을 가집니다.
그리고 keras.datasets에서 cifar100 데이터를 로드하고 train과 teest 데이터의 구성을 확인해봅니다.
num_classes = 100
input_shape = (32, 32, 3)
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar100.load_data()
print(f"x_train shape: {x_train.shape} - y_train shape: {y_train.shape}")
print(f"x_test shape: {x_test.shape} - y_test shape: {y_test.shape}")

이제 학습간 활용할 하이퍼 파라미터에 대해서 정의해줍니다.
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 256
num_epochs = 10 # For real training, use num_epochs=100. 10 is a test value
image_size = 72 # We'll resize input images to this size
patch_size = 6 # Size of the patches to be extract from the input images
num_patches = (image_size // patch_size) ** 2
projection_dim = 64
num_heads = 4
transformer_units = [
projection_dim * 2,
projection_dim,
] # Size of the transformer layers
transformer_layers = 8
mlp_head_units = [
2048,
1024,
] # Size of the dense layers of the final classifier
*이때 일반적인 학습률, 배치사이즈 등 뿐만 아니라, ViT 사용을 위해 패치사이즈, 패치의 갯수, 프로젝션 차원, 헤드의 개수 등을 정의해줍니다.
(ViT 함수 정의 간 활용합니다.)
다음은 학습 모델의 강건성(Robustness)을 위해 Data augmentation을 진행해줍니다. 이때 horizontal flip(수평 대칭), 회전, Zoom을 데이터 중 랜덤하게 하게 해줍니다.
data_augmentation = keras.Sequential(
[
layers.Normalization(),
layers.Resizing(image_size, image_size),
layers.RandomFlip("horizontal"),
layers.RandomRotation(factor=0.02),
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
],
name="data_augmentation",
)
# Compute the mean and the variance of the training data for normalization.
data_augmentation.layers[0].adapt(x_train)
다음은 이미지를 작은 패치들로 분할하는 커스텀 레이어를 정의해줍니다.
class Patches(layers.Layer):
def __init__(self, patch_size):
super().__init__()
self.patch_size = patch_size
def call(self, images):
input_shape = ops.shape(images)
batch_size = input_shape[0]
height = input_shape[1]
width = input_shape[2]
channels = input_shape[3]
num_patches_h = height // self.patch_size
num_patches_w = width // self.patch_size
patches = keras.ops.image.extract_patches(images, size=self.patch_size)
patches = ops.reshape(
patches,
(
batch_size,
num_patches_h * num_patches_w,
self.patch_size * self.patch_size * channels,
),
)
return patches
def get_config(self):
config = super().get_config()
config.update({"patch_size": self.patch_size})
return config
이제 정의된 패치 커스텀 레이어를 활용해서 샘플 이미지를 불러와서 잘 작동하는지 활용해보겠습니다.
plt.figure(figsize=(4, 4))
image = x_train[np.random.choice(range(x_train.shape[0]))]
plt.imshow(image.astype("uint8"))
plt.axis("off")
resized_image = ops.image.resize(
ops.convert_to_tensor([image]), size=(image_size, image_size)
)
patches = Patches(patch_size)(resized_image)
print(f"Image size: {image_size} X {image_size}")
print(f"Patch size: {patch_size} X {patch_size}")
print(f"Patches per image: {patches.shape[1]}")
print(f"Elements per patch: {patches.shape[-1]}")
n = int(np.sqrt(patches.shape[1]))
plt.figure(figsize=(4, 4))
for i, patch in enumerate(patches[0]):
ax = plt.subplot(n, n, i + 1)
patch_img = ops.reshape(patch, (patch_size, patch_size, 3))
plt.imshow(ops.convert_to_numpy(patch_img).astype("uint8"))
plt.axis("off")



최초 설정한 하이퍼 파라미터로 인해 이미지의 크기와 패치의 사이즈가 잘 정의되었음을 확인할 수 있습니다.
패치의 총 개수와 패치당 요소의 개수 등을 수치적으로, 그리고 시각적으로 확인할 수 있습니다.
(패치 레이어 함수가 잘 정의함을 확인했습니다.)
이제 잘 나누어진 이미지 패치를 임베딩 벡터로 인코딩하는 레이어를 정의해줍니다.
이 클래스는, 각 패치에 대한 학습된 임베딩을 생성해주고, 위치 임베딩(position embedding)을 추가해 패치 간의 위치 정보를 보존해줍니다.
class PatchEncoder(layers.Layer):
def __init__(self, num_patches, projection_dim):
super().__init__()
self.num_patches = num_patches
self.projection = layers.Dense(units=projection_dim)
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = ops.expand_dims(
ops.arange(start=0, stop=self.num_patches, step=1), axis=0
)
projected_patches = self.projection(patch)
encoded = projected_patches + self.position_embedding(positions)
return encoded
def get_config(self):
config = super().get_config()
config.update({"num_patches": self.num_patches})
return config
이제 위에서 정의한 클래스들을 활용해 Vision Transformer 함수를 정의해줍니다.
def create_vit_classifier():
inputs = keras.Input(shape=input_shape)
# Augment data.
augmented = data_augmentation(inputs)
# Create patches.
patches = Patches(patch_size)(augmented)
# Encode patches.
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization 1.
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
# Create a multi-head attention layer.
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Skip connection 1.
x2 = layers.Add()([attention_output, encoded_patches])
# Layer normalization 2.
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# MLP.
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Skip connection 2.
encoded_patches = layers.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor.
representation = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
representation = layers.Flatten()(representation)
representation = layers.Dropout(0.5)(representation)
# Add MLP.
features = mlp(representation, hidden_units=mlp_head_units, dropout_rate=0.5)
# Classify outputs.
logits = layers.Dense(num_classes)(features)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=logits)
return model
특히, 트랜스포머 블록 생성하는 부분에 대해서 알아보면
1) 레이어 정규화
2) 멀티헤드 어텐션
3) 스킵 커넥션
4) 레이어 정규화
5) MLP
6) 스킨 커넥션 의 과정을 반복합니다.
이러한 블록은 위에서 정의한 하이퍼 파라미터의 수만큼 반복해서 이루어지게 됩니다.
representation 부분은 MLP를 통해서 도출된 representation 벡터들을 분류기(Classifier)에 연결하기 위해 정의했습니다.
이제 정의한 모든것들을 활용해서 학습 및 검증, 그리고 테스트를 진행해줍니다.
이때 다중 클래스에 대한 정수 인코딩을 활용하기 위해 SparseCategoricalAccuracy를 활용해줍니다.
그리고 학습 및 검증 간, loss와 accuracy, 그리고 top-5 클래스(accuracy가 높은)에 대한 accuracy가 도출되도록 해줍니다.
또한, 학습간 발생하는 위와같은 loss와 accuracy를 시각화해줍니다.
학습 데이터가 많고 모델이 무거운 만큼 학습 시간이 오래걸립니다. 아래 코드는 실습목적이므로 epochs 수는 10으로 정의해주었으나, 더 늘려도 괜찮습니다.
def run_experiment(model):
optimizer = keras.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
model.compile(
optimizer=optimizer,
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[
keras.metrics.SparseCategoricalAccuracy(name="accuracy"),
keras.metrics.SparseTopKCategoricalAccuracy(5, name="top-5-accuracy"),
],
)
checkpoint_filepath = "/tmp/checkpoint.weights.h5"
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_accuracy",
save_best_only=True,
save_weights_only=True,
)
history = model.fit(
x=x_train,
y=y_train,
batch_size=batch_size,
epochs=num_epochs,
validation_split=0.1,
callbacks=[checkpoint_callback],
)
model.load_weights(checkpoint_filepath)
_, accuracy, top_5_accuracy = model.evaluate(x_test, y_test)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%")
return history
vit_classifier = create_vit_classifier()
history = run_experiment(vit_classifier)
def plot_history(item):
plt.plot(history.history[item], label=item)
plt.plot(history.history["val_" + item], label="val_" + item)
plt.xlabel("Epochs")
plt.ylabel(item)
plt.title("Train and Validation {} Over Epochs".format(item), fontsize=14)
plt.legend()
plt.grid()
plt.show()
plot_history("loss")
plot_history("top-5-accuracy")
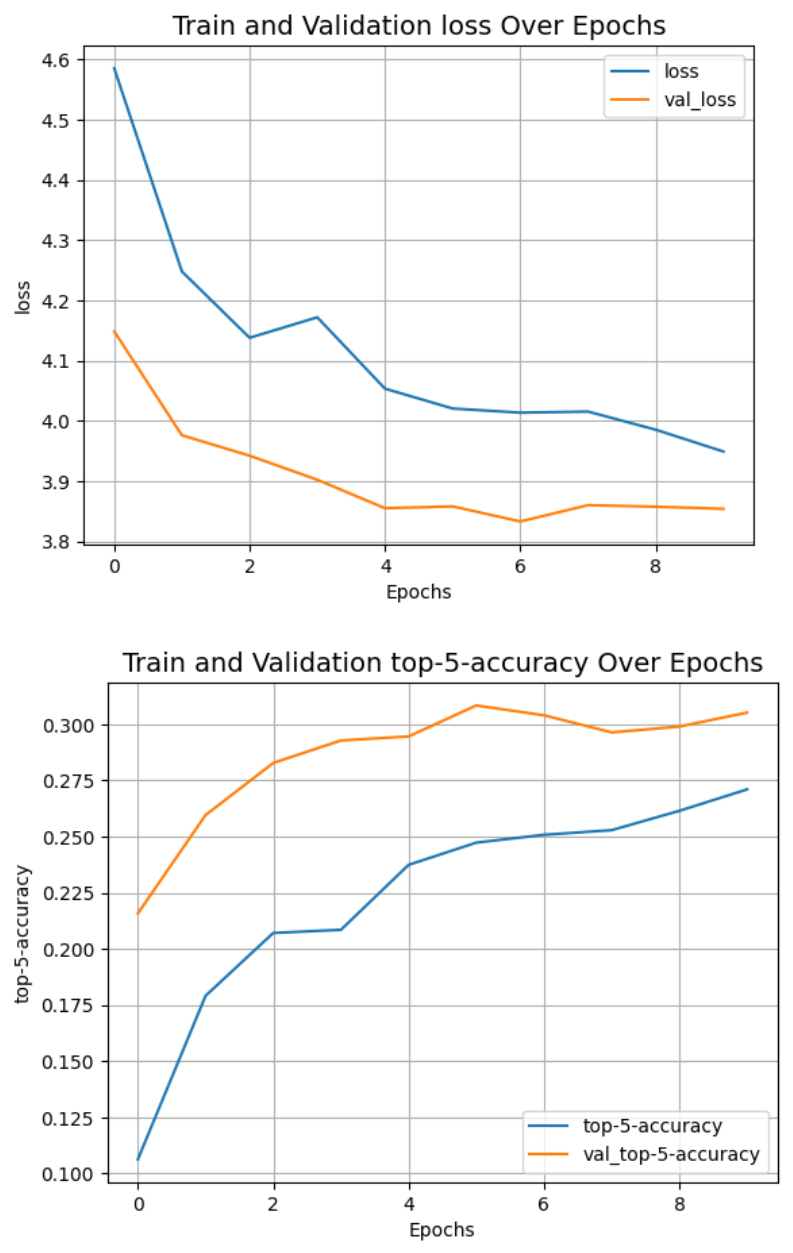
train과 validation loss를 보면 아직 overfitting이 되지 않은 모습입니다. 즉 더 학습을 시켜야하는 상태임을 알 수 있습니다.
우선 해당 코드를




댓글