
이번에 알아볼 것은 지난 시간에 알아본 정확도 및 기타 분류평가지표를 도출할 수 있는
오차행렬 또는 혼동행렬이라 불리는 Confusion Matrix에 대해서 알아보겠습니다.
1. 오차행렬 / 혼동행렬 (Confusion Matrix) 이란?
- Confusion Matrix(오차 행렬)은 분류 모델의 성능을 평가하기 위한 표입니다.
- 주로 이진 분류(두 가지 클래스로 분류) 문제를 다룰 때 사용되지만, 다중 분류에서도 그 분류 결과를 한눈에 정리해주는 용도로 사용됩니다.
- 이는, 모델이 예측한 결과와 실제 관측된 결과를 비교하는 데에 사용되며 아래 네 가지 주요 항목으로 구성됩니다.
1) True Positive(TP) : 예측값을 Positive로 예측했는데 실제 값 역시 Positive인 경우
2) True Negative(TN) : 예측값을 Negative로 예측했는데 실제 값 역시 Negative인 경우
3) False Negative(FN) : 예측값을 Negative로 예측했는데 실제 값은 Positive인 경우
4) False Positive(FP) : 예측값을 Positive로 예측했는데 실제 값은 Negative인 경우
* 위를 요약해보면,
앞에 있는 True 또는 False는, 뒤에 있는 클래스(Positive 또는 Negative / 예측값)의 사실 여부를 나타내며
뒤에 있는 Positive 또는 Negative는, 모델이 예측한 해당 데이터의 클래스를 의미합니다.
즉, (모델 예측값의 진위여부) + (모델의 예측값) 를 의미합니다.
- 이를 유방암 데이터와 연계해서 생각해보면 다음과 같습니다.

a. True Positives (TP): 모델이 실제 양성 종양을 양성으로 정확하게 예측한 환자 수입니다. 이는 유방암을 진단하고 양성 종양을 정확하게 식별한 환자 수입니다.
b. True Negatives (TN): 모델이 실제 음성 종양을 음성으로 정확하게 예측한 건강한 환자 수입니다. 이는 건강한 사람을 정확하게 건강하다고 판단한 환자 수입니다.
c. False Positives (FP): 모델이 실제로는 건강한 사람을 양성 종양으로 잘못 예측한 환자 수입니다. 양성 종양이 아닌데도 양성 종양으로 판단한 경우입니다.
d. False Negatives (FN): 모델이 실제 양성 종양을 음성으로 잘못 예측한 환자 수입니다. 양성 종양임에도 불구하고 음성 종양으로 판단한 경우입니다.
이를 활용해서 각종 평가지표들(Accurcy, Precision, Recall, f1-score 등)을 구할 수 있습니다. 데이터 분석을 통해서 실제 사례를 통해 알아보겠습니다.
2. 파이썬으로 알아보는 유방암(Breast Cancer) 데이터를 활용한 오차행렬과 평가지표들
1) 먼저 필요한 라이브러리를 임포트 해줍니다. 이때, 데이터 셋은 사이킷런에 저장되어있는 Breast Cancer 데이터를 활용해주겠습니다.
불러온 데이터는 학습용(train)과 테스트(test) 용으로 분리해줍니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 필요한 라이브러리 임포트
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve
import warnings
from sklearn.exceptions import ConvergenceWarning
warnings.filterwarnings("ignore", category=ConvergenceWarning) #경고 메시지 무시 설정
# Breast cancer 데이터셋 불러오기
data = load_breast_cancer()
X = data.data
y = data.target
# 데이터를 학습용과 테스트용으로 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
cs |
2) 이후 해당 데이터를 분류해줄 모델을 정해주어야 하는데, 이번 실습에서는 간단한 로지스틱회귀 모형을 활용하겠습니다.
특별한 파라미튜 튜닝없이 기본 모델을 사용해주며, 이를 통해 예측 결과(y_pred)를 실제 결과(y)와 비교해줍니다.
그리고 이 결과를 오차행렬(Confusion Matrix)로 만들어 정리해줍니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
# 혼동 행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Benign", "Malignant"], yticklabels=["Benign", "Malignant"])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title(' Confusion Matrix')
plt.show()
|
cs |

예측 모델은 테스트 데이터 총 114개를 예측하였으며 해당 결과를 해석하면
TP는 70개 / FP는 1개 / FN은 3개 / TN은 40개 로 정리할 수 있습니다.
3) 정확도(Accuracy) / 재현율(Recall) / 정밀도(Precision) / F1 score
3-a) 정확도는 전체 샘플 중 올바르게 분류된 샘플의 비율을 나타냅니다. 이를 식으로 표현하면 아래와 같습니다.
* 정확도(Accuracy) = (TP + TN) / (TP + TN + FP + FN)
3-b) 재현율(Recall 또는 Sensitivity)은 실제 양성 중 모델이 양성으로 올바르게 예측한 비율을 나타냅니다. 양성 클래스를 정확하게 잡아내는데 중점을 둔 지표로, 거짓 음성(FN)을 최소화하는데 유용합니다.
* 재현율 = TP / (TP + FN)
* 특히 재현율이 중요 지표인 경우는, 실제 Positive 양성 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우로, 사람의 생명이 달린 암진단의 경우에 중요하게 생각되는 지표입니다.
3-c) 정밀도(Precision)는 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 비율을 나타냅니다. 양성으로 예측된 샘플 중 얼마나 많은 것이 실제로 양성인지를 측정하며, 거짓 양성(FP)을 최소화하는 데 중점을 둡니다.
* 정밀도 = TP / (TP + FP)
* 정밀도가 중요한 경우는, 스팸메일 여부를 판단하는 모델이 대표적인 예가 되겠습니다. 해당 모델의 경우 실제 Positive인 스팸 메일을 Negative인 일반 메일로 분류하더라도 사용자가 불편함을 느끼는 정도이지만, 실제 Negative인 일반 메일을 Positive인 스팸 메일로 분류할 경우 메일을 아예 받지 못하게 되어 업무에 차질이 생길 수 있습니다.
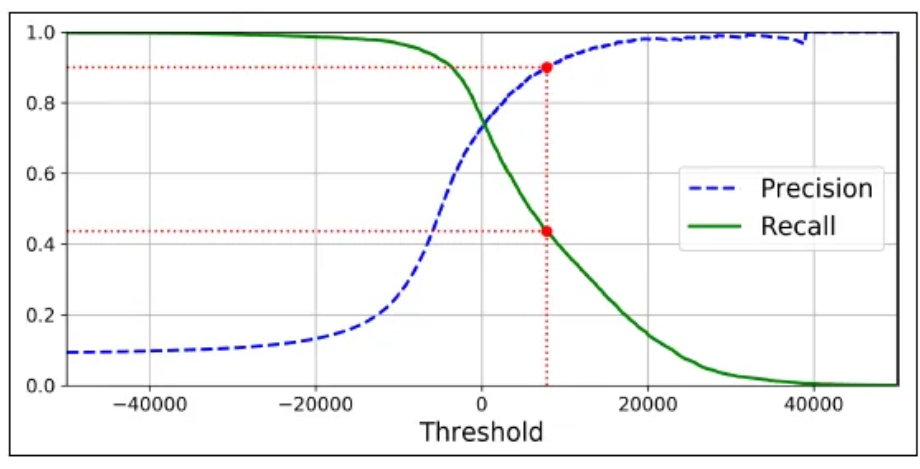
** 재현율과 정밀도의 trade-off**
a. 이 두 지표는 서로 상충 관계에 있어서, 한 지표를 높이려면 다른 지표가 감소할 수 있으며 이를 trade-off라고 합니다.
b. 재현율과 정밀도의 trade-off는 모델의 결정 임계값(threshold)을 조절함으로써 조절할 수 있습니다. 모델의 예측 확률이 특정 임계값보다 높을 때 양성으로 분류하고, 낮을 때 음성으로 분류합니다. 임계값을 낮추면 재현율이 증가하고 정밀도가 감소하며, 임계값을 높이면 정밀도가 증가하고 재현율이 감소합니다.
c-1. 임계값을 낮추면,
더 많은 샘플이 양성으로 분류되므로 재현율이 증가합니다.
하지만 더 많은 거짓 양성(FP)도 발생하여 정밀도가 감소합니다.
c-2. 임계값을 높이면,
적은 샘플이 양성으로 분류되므로 정밀도가 증가합니다.
하지만 더 많은 거짓 음성(FN)도 발생하여 재현율이 감소합니다.
d. 따라서 재현율과 정밀도는 서로 반비례 관계에 있으며, 어떤 지표를 강조할지는 문제의 특성과 목표에 따라 달라집니다. Trade-off를 조절할 때는 모델의 성능과 목표를 고려하여 적절한 임계값을 선택해야 합니다.
3-d) F1 스코어는 정밀도와 재현율의 조화 평균입니다. 모델의 성능을 하나의 숫자로 요약하는 데 사용되며, 정밀도와 재현율 간의 균형을 평가합니다.
* F1 스코어 = 2 * (정밀도 * 재현율) / (정밀도 + 재현율)
* F1 스코어는 불균형한 클래스 분포를 갖는 데이터셋에서 유용합니다.
이들을 파이썬 코드로 구현해보면 아래와 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Accuracy 계산
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: (TP+TN) / (TP+TN+FP+FN) = ({cm[1,1]}+{cm[0,0]}) / ({cm[1,1]}+{cm[0,0]}+{cm[0,1]}+{cm[1,0]}) = {accuracy:.2f}")
print('')
# Recall 계산
recall = recall_score(y_test, y_pred)
print(f"Recall: TP / (TP+FN) = {cm[1,1]} / ({cm[1,1]}+{cm[1,0]}) = {recall:.2f}")
print('')
# Precision 계산
precision = precision_score(y_test, y_pred)
print(f"Precision: TP / (TP+FP) = {cm[1,1]} / ({cm[1,1]}+{cm[0,1]}) = {precision:.2f}")
print('')
# F1 Score 계산
f1 = f1_score(y_test, y_pred)
print(f"F1 Score: 2 * (Precision * Recall) / (Precision + Recall) = 2 * ({precision:.2f} * {recall:.2f}) / ({precision:.2f} + {recall:.2f}) = {f1:.2f}")
|
cs |

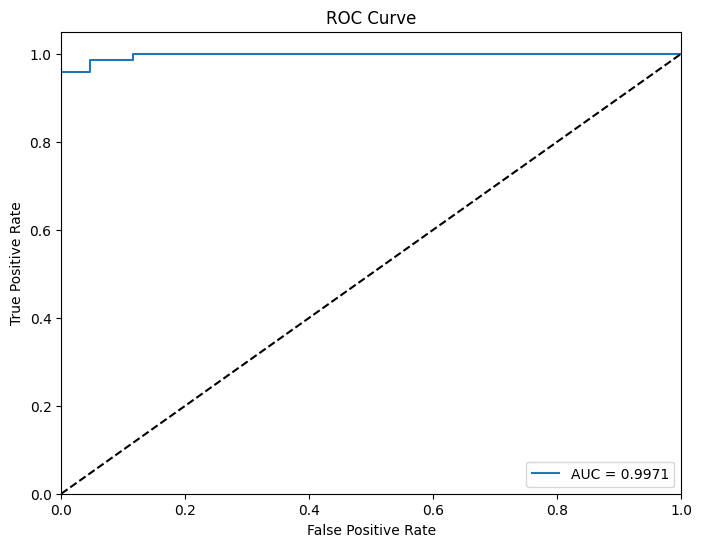
3-e) 다음은 ROC Curve와 AUC-ROC Score 입니다.
* ROC Curve(Receiver Operating Characteristic Curve)는 이진 분류 모델의 민감도와 특이도를 나타내는 곡선이며, 다양한 결정 임계값에서 모델의 성능을 시각적으로 보여줍니다.
* 이 곡선 아래의 면적을 나타내는 AUC-ROC Score(Area Under the ROC Curve Score)는 모델의 성능을 수치적으로 나타내며, 1에 가까울수록 우수한 성능을, 0.5에 가까울수록 랜덤 수준의 성능을 나타냅니다.
* AUC-ROC Score는 클래스 불균형 데이터셋에서 모델 성능을 평가하고 비교하는 데 유용합니다.
이들을 파이썬 코드로 구현해보면 아래와 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# ROC Curve 및 AUC-ROC Score 계산
y_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = roc_auc_score(y_test, y_prob)
# ROC Curve 시각화
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f'AUC = {roc_auc:.4f}')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()
|
cs |




댓글