
이번에 알아볼 내용은 딥러닝 모델 구현 간 파이썬에서 사용되는 오픈 소스 프레임워크 (Open Source Framework) 중 가장 많이 활용되는
텐서플로우(Tensorflow)와 파이토치(Pytorch)에 대해서 알아보겠습니다.
1. 텐서플로우(Tensorflow)와 파이토치(Pytorch)
1) 텐서플로우와 파이토치
a) 텐서플로우(Tensorflow)는 구글에서 개발한 딥러닝 프레임워크로, 초기에는 정적 계산 그래프를 사용하였으나 2.0 버전부터는 동적 계산 그래프를 지원합니다.
b) 파이토치(Pytorch)는 페이스북이 개발한 오픈 소스 딥러닝 프레임워크로, 동적 계산 그래프를 사용하는 것이 특징입니다.
2) 두 오픈 소스프레임워크와 딥러닝
- 텐서플로우와 파이토치는 딥러닝 및 기계 학습 모델 개발에 필수적이며, 산업 및 연구 분야에서 널리 사용되는데, 그 이유는 해당 프레임워크들을 사용하여 모델을 구축하면 a)보다 빠르게 구축가능하며 b)학습 및 배포가 용이하고 c) 그 인기로 인해 관련 커뮤니티 및 라이브러리의 발전이 활발하여 여러가지 지원을 받기 용이하다는 점이 있습니다.
2. 두 모델의 비교
1) 구문 및 API 비교
a) 텐서플로우는 정적 계산 그래프를 사용하며, 모델을 정의하고 실행하기 위해 세션을 사용합니다.
b) 파이토치는 동적 계산 그래프를 사용하며, 파이썬 스타일의 코드를 통해 모델을 정의하고 실행합니다.
이를 딥러닝 네트워크 구축에 대한 코딩의 예시를 통해 알아보겠습니다.
이를 위해 사용한 데이터는 iris 데이터입니다.
*먼저, 사용할 라이브러리와 데이터를 로드하고, 데이터에 대한 정규화 및 학습/테스트용으로 데이터를 분할해줍니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
import torch
import torch.nn as nn
import torch.optim as optim
import tensorflow as tf
from tensorflow.keras import layers
# Iris 데이터 로드
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 데이터 정규화
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
cs |
* 먼저, 구축할 모델은 파이토치 기반의 DNN 모델입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class PyTorchDNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(PyTorchDNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.softmax(x)
return x
# 모델 초기화
input_size = 4 # Iris 데이터의 특성 수
hidden_size = 8
output_size = 3 # Iris 데이터의 클래스 수
model = PyTorchDNN(input_size, hidden_size, output_size)
# 손실 함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습
num_epochs = 100
for epoch in range(num_epochs):
inputs = torch.FloatTensor(X_train)
labels = torch.LongTensor(y_train)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 테스트
with torch.no_grad():
inputs = torch.FloatTensor(X_test)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
accuracy = accuracy_score(y_test, predicted.numpy())
print("PyTorch Accuracy:", accuracy)
|
cs |

* 다음으로 구축할 모델은 텐서플로 기반의 DNN 모델입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 모델 초기화
model = tf.keras.Sequential([
layers.Input(shape=(4,)),
layers.Dense(hidden_size, activation='relu'),
layers.Dense(output_size, activation='softmax')
])
# 모델 컴파일
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 학습
model.fit(X_train, y_train, epochs=num_epochs, verbose=0)
# 테스트
y_pred = model.predict(X_test)
predicted = np.argmax(y_pred, axis=1)
accuracy = accuracy_score(y_test, predicted)
print("TensorFlow Accuracy:", accuracy)
|
cs |

* 결과 상 텐서플로우가 더 우세한것 처럼 보이지만, 모델의 세부구조에 따라서 결과는 바뀔 수 있으니 결과에 차이를 두기보다는 구조상의 차이점에 대해서 집중해서 보시는 것을 추천드립니다.
2) 각 오픈소스프레임워크의 커뮤니티 및 생태계의 차이점
a) 텐서플로우는 TensorFlow Hub, TensorFlow Extended(TFX)와 같은 확장 라이브러리 및 TensorFlow Serving과 같은 배포 도구를 제공합니다.
b) 파이토치는 PyTorch Hub 및 PyTorch Lightning과 같은 확장 라이브러리를 사용가능합니다.
c) 이를 포함해 서로를 비교한 표는 아래와 같습니다
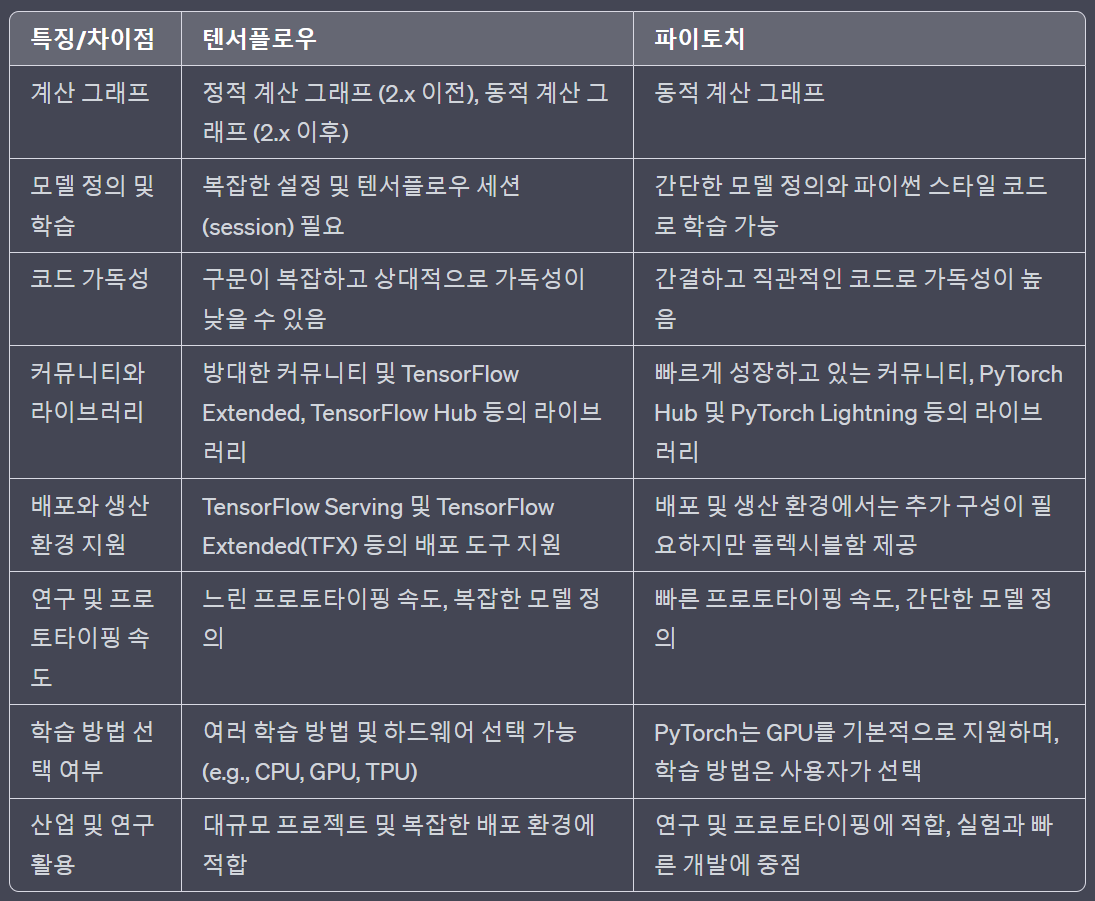
3. 결론
- 각 오픈소스 프레임워크는 프로젝트의 목표와 요구 사항을 고려하여 선택하시는 것이 바람직합니다
- 텐서플로우는 복잡한 배포 환경 및 고성능을 필요로 하는 프로젝트에 적합할 수 있습니다.
- 이에 반해, 파이토치는 동적 계산 그래프와 간단한 모델 정의로 실험 및 프로토타이핑에 적합하다고 볼 수 있습니다.




댓글