
이번에 알아볼 것은 머신러닝의 분류(Classification) 문제 중 정확도(Accuracy)에 관한 것입니다.
1. 정확도(Accuracy)란?
정확도(Accuracy)란, 분류 모델의 성능을 평가하는 지표 중 하나로, 전체 예측 중 올바르게 분류된 비율을 나타냅니다.
이를 식으로 표현하면 아래와 같은데요.

즉, 정확도는 모델이 얼마나 많은 샘플을 올바르게 분류하는지를 측정하는 지표를 말합니다.
정확도의 값은 0에서 1사이의 범위를 가지며, 1에 가까울수록 올바르게 분류된 샘플의 수가 많다는 것을 의미합니다. 예를 들어, 정확도가 0.85라면 모델이 전체 데이터 중 85%를 올바르게 분류했다는 의미입니다.
2. 파이썬 코딩으로 알아보는 정확도의 의미 (유방암(Breast Cancer) 데이터 사용)
이번에는 파이썬 코딩으로 알아보겠습니다.
먼저, 유방암(Breast Cancer) 데이터에 대해서 알아보겠습니다.
- Breast Cancer 데이터셋은 유방암 진단 분류 문제를 다루는 데 사용되는 고전적인 머신 러닝 데이터셋 중 하나입니다. 이 데이터셋은 미국 위스콘신 대학에서 수집한 유방 조직 세포의 특징을 기반으로 종양이 양성(benign)인지 악성(malignant)인지를 분류되어 있는데요.
- 해당 데이터 셋을 요약하면 아래와 같습니다.
* 총 10개의 features가 있으며, 1개의 Response("Class")로 구성되어 있습니다.
* 이 중 Response인 Class는 "2"로 표시될 경우 양성 종양(benign) / "4"로 표시될 경우 악성 종양(malignant)를 뜻합니다.
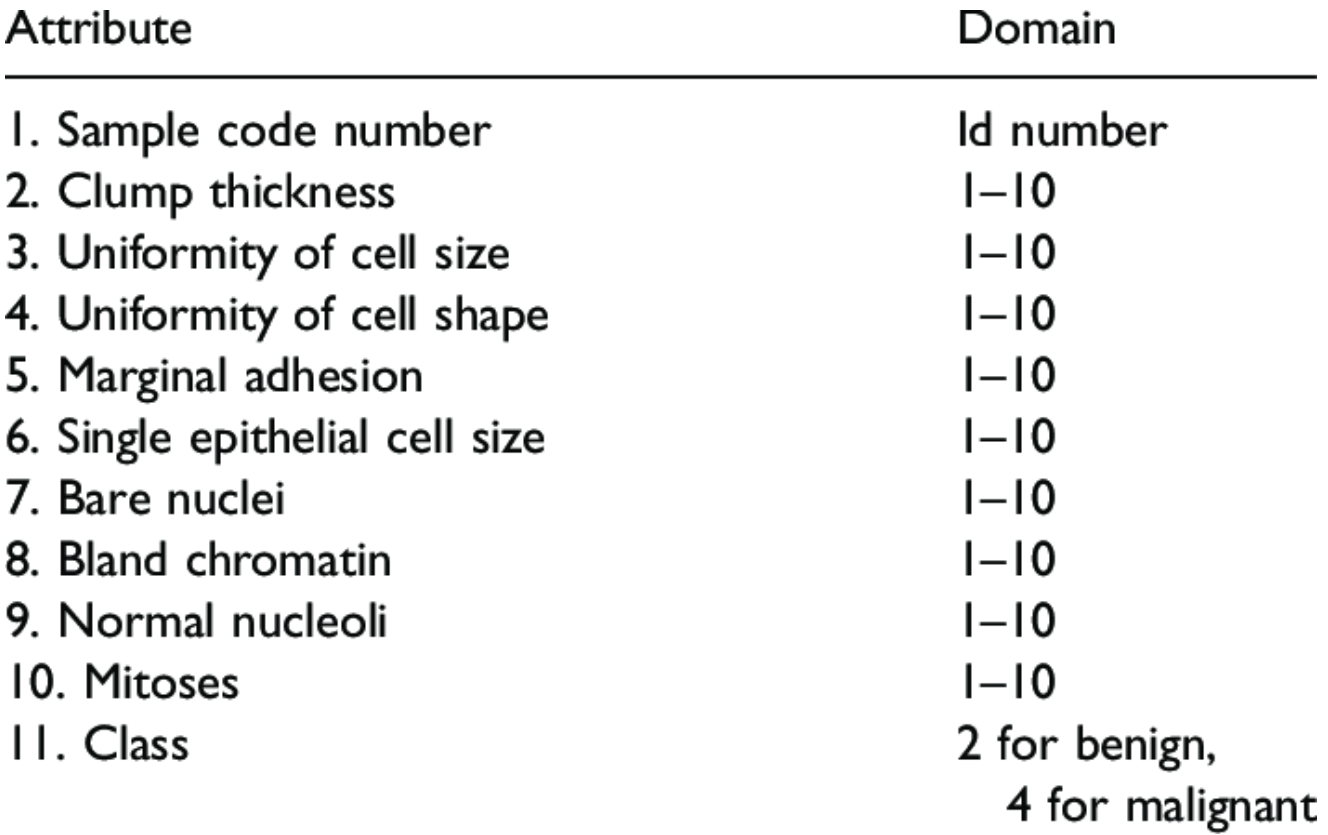
- 해당 데이터 셋은 머신러닝 학습에 널리 사용되는 오픈 데이터로, Scikit Learn의 패키지에 포함되어 있습니다. 그래서, 해당 라이브러리에 저장되어있는 데이터를 그대로 사용하여 분류 문제를 해결하는 파이썬 코딩을 해보겠습니다.
- 이때, 분류 모델은 1) Base Estimator(아무런 학습 없이, 모든 데이터를 benign으로 예측), 2) Logistic Regression, 3) Random Forest를 활용하겠으며,
이를 통해 정확도(Accuracy)의 의미를 알아보겠습니다.
1) 먼저 필요한 라이브러리들을 가져오겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#필요한 라이브러리 불러오기
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
import numpy as np
from sklearn.metrics import accuracy_score
import warnings
from sklearn.exceptions import ConvergenceWarning
# 경고 메시지 무시 설정
warnings.filterwarnings("ignore", category=ConvergenceWarning)
#Breast Cancer 데이터 셋 불러오기
from sklearn.datasets import load_breast_cancer
|
cs |
* pyplot과 seaborn은 나중에 혼동행렬(Confusion Matrix)을 시각화할때 사용할 것입니다.
* train_test_split은 데이터를 학습용과 테스트용으로 나누는 용이며
* BaseEstimator / LogisticRegression / RandomForestClassifier는 사용할 분류기에 해당하는 라이브러리
* confusion_matrix는 혼동행렬 만들때 사용
* numpy는 숫자 데이터 처리에 활용
* accuracy_score는 정확도 계산에 활용
* warnings와 ConvergenceWarning은 출력 결과물에 나타나는 오류를 미출력하기위해 사용
* 마지막으로 load_breast_cancer를 활용해 데이터셋 가져오기
2) 다음은 Breast Cancer 데이터를 가져온 뒤 데이터를 Features(X 행렬로 저장)와 y(y 행렬로 저장) 나눕니다.
이후 학습용과 테스트용으로 나누며, 학습용은 80% / 테스트용은 20%로 나눕니다.
|
1
2
3
4
5
6
7
|
# Breast Cancer 데이터 로드
data = load_breast_cancer()
X = data.data
y = data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
cs |
3) 이번에는 단순 분류기(무조건 양성이라고 예측하는)를 만들어줍니다.
단순분류기는 무조건 양성이라고 예측해야하는 부분이 필요하기에 다음과 같은 작업을 해주며, Logistic Regression과 RandomForestClassifier의 경우에는 사이킷런 라이브러리 내의 모델을 그대로 사용
+ 모델을 정리해주어 다음 작업을 편하게 만들어주었습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# BaseEstimator를 사용한 단순한 분류기 생성
class SimpleClassifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
#Logistic Regression과 RandomForestClassifer 모델은 사이킷런 라이브러리내의 모델 그대로 사용
# 모델 정리
models = [SimpleClassifier(), LogisticRegression(),RandomForestClassifier()]
|
cs |
4-1) 첫 번째 모델 : 단순분류기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#Base Estimator : models[0]
i=0
# 모델 훈련
models[i].fit(X_train, y_train)
# 예측
y_pred = models[i].predict(X_test)
#정확도(Accuracy) 출력
accuracy = accuracy_score(y_test, y_pred)
print( str(models[0]),' Accuracy: ', round(accuracy,2))
print('------------------------------------------------')
print('')
print('')
print('')
# 혼동 행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Benign", "Malignant"], yticklabels=["Benign", "Malignant"])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title(str(models[0]) +' Confusion Matrix')
plt.show()
|
cs |
해당 분류기가 도출한 결과는 아래와 같습니다.
* 정확도 : 38% ( = 43 / (43+71) )

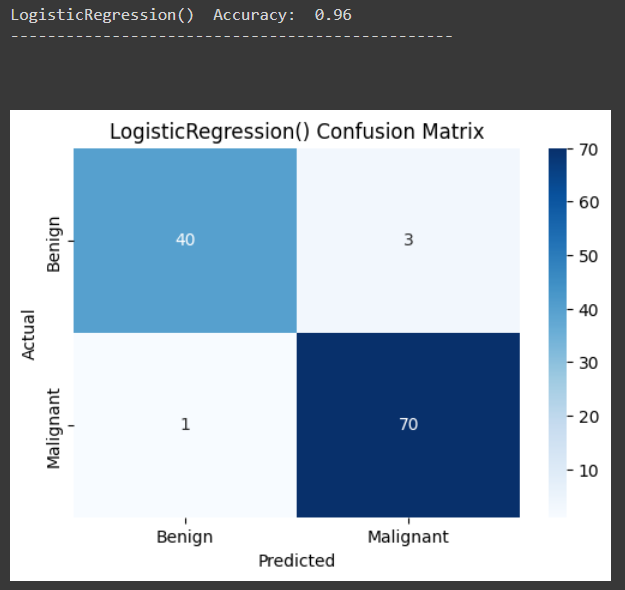
4-2) 두 번째 모델 : Logistic Regression
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#Logistic Regression : models[0]
i=1
# 모델 훈련
models[i].fit(X_train, y_train)
# 예측
y_pred = models[i].predict(X_test)
#정확도(Accuracy) 출력
accuracy = accuracy_score(y_test, y_pred)
print( str(models[i]),' Accuracy: ', round(accuracy,2))
print('------------------------------------------------')
print('')
print('')
print('')
# 혼동 행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Benign", "Malignant"], yticklabels=["Benign", "Malignant"])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title(str(models[i]) +' Confusion Matrix')
plt.show()
|
cs |
해당 분류기가 도출한 결과는 아래와 같습니다.
* 정확도 : 96% ( = 110 / (43+71) )
4-3) 세 번째 분류 모델 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#Logistic Regression : models[0]
i=1
# 모델 훈련
models[i].fit(X_train, y_train)
# 예측
y_pred = models[i].predict(X_test)
#정확도(Accuracy) 출력
accuracy = accuracy_score(y_test, y_pred)
print( str(models[i]),' Accuracy: ', round(accuracy,2))
print('------------------------------------------------')
print('')
print('')
print('')
# 혼동 행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Benign", "Malignant"], yticklabels=["Benign", "Malignant"])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title(str(models[i]) +' Confusion Matrix')
plt.show()
|
cs |
해당 분류기가 도출한 결과는 아래와 같습니다.
* 정확도 : 96% ( = 110 / (43+71) )





댓글