
이번에는 지난번 개략적인 개념과 코드 실습 위주로 알아봤었던 VAE에 대해서 조금 더 심층 깊게 이해하고자 합니다.
[생성 AI] 변이형 오토인코더(Variational Auto Encoder) (1/2)
[생성 AI] 변이형 오토인코더(Variational Auto Encoder) (1/2)
[해당 포스팅은 "만들면서 배우는 생성 AI 2탄"을 참조했습니다] 1. 변이형 오토인코더(VAE, Variational Auto Encoder)란?- 변이형 오토인코더, VAE는 심층 신경망을 이용한 생성 모델의 하나로, 데이터의
jaylala.tistory.com
[생성 AI] 변이형 오토인코더(Variational Auto Encoder) (2/2)
[생성 AI] 변이형 오토인코더(Variational Auto Encoder) (2/2)
[해당 포스팅은 "만들면서 배우는 생성 AI 2탄"을 참조했습니다] 지난번에 알아본 개념을 바탕으로 이번에는 코드를 통해 실습을 해보겠습니다. 이번에 실습할 데이터는 패션 MNIST 데이터입니다
jaylala.tistory.com
[딥러닝 with Python] 변이형 오토인코더(Variational Auto Encoder) 추가본 - CelebA Faces 활용
[딥러닝 with Python] 변이형 오토인코더(Variational Auto Encoder) 추가본 - CelebA Faces 활용
[해당 포스팅은 "만들면서 배우는 생성 AI 2탄" 을 참조했습니다] 이번 지난번 2편의 변이형 오토 인코더에 대한 포스팅의 확장 버전입니다.[생성 AI] 변이형 오토인코더(Variational Auto Encoder) (1/2) [
jaylala.tistory.com
VAE(Variational Auto Encoder / 변이형 오토 인코더)는 Auto Encoder의 변이형으로,
기존 Auto Encoder는 원본 데이터의 정보를 압축하여 고차원의 latent space에 embedding하는 Encoder, Embedding된 된 벡터를 다시 복원하는 Decoder로 구성되어 주로 Encoder를 학습하는 것에 초점이 맞춰졌다면,
VAE는 Decoder를 학습하는데 중점이 맞춰졌다고 생각하면 되겠습니다.
이제 세부적인 내용에 대해서 알아보겠습니다.
1. VAE
1) 기존 AE(Auto Encoder)의 문제
- 기존 AE는 a) 특별히 유용하거나 잘 구성된 latent space를 만드는게 제한되었고, b) 학습된 모델로부터 새로운 데이터를 샘플링할 수가 없다는 문제가 있었습니다. 즉, 기존 데이터를 잘 복원하는 법만을 학습해서 기존 학습된 데이터들과 다른 이미지가 들어왔을때 그 차이를 극대화 시켜주는 이상치 탐지(Anomaly Detection)에 특화되었다고 볼 수 있습니다.
- 즉, AE는 생성이라는 부분에서는 활용되기가 제한되었습니다.
- AE는 x라는 input data를 잘 학습해서 x가 잘 embedding 될 수 있는 manifold를 학습해나가는 것이 주요 목적이었습니다.
* 데이터의 특징을 잘 저장할 수 있는 mainfold를 학습하고 그곳에 mapping하는 것이 주목적이라고 보면 되겠습니다.
2) 생성을 위한 AE 구조의 변형
- 이런 구조적인 한계로 인해 생성 모델의 일환으로 AE를 변형해보고자 나온 것인 Variational Auto Encoder(VAE) 입니다.
- 이때, 이와 같은 생각을 해볼 수 있습니다.
* 만약 모집단의 모든 데이터를 학습한 AE가 있다면, 이를 통해 우리가 원하는 데이터를 정확히 재구성해낼 수 있습니다. 그러나 현실적으로 모집단의 모든 데이터를 안다는 것은 불가능에 가깝고, 이 때문에 우리가 수집한 데이터는 모집단을 추정하기 위한 샘플로 간주할 수 있습니다. 이를 통해 모집단의 분포를 추정하는 방법을 고민하게 되었습니다.
* 이러한 아이디어에서 나온 것이 바로 VAE 입니다. AE는 입력 데이터의 특징을 잘 표현하는 manifold를 학습하는 능력을 가지고 있습니다. VAE는 이 능력을 바탕으로 입력 데이터를 manifold 상의 latent space로 매핑하고, 이후 잠재 공간에서의 데이터 분포를 추정하여, 학습하지 않은 새로운 데이터도 생성할 수 있다는 아이디어가 바로 VAE의 핵심이 되겠습니다.
즉, 이를 통해 VAE는 확률적 접근을 활용하여 샘플링을 통해 새로운 데이터를 생성할 수 있는 모델이라는 것입니다.
* Auto Encoder
*Variational Auto Encoder

위와 같이 VAE는 입력 이미지를 latent space에 embedding 후, embdding 차원 별 평균과 분산을 구하여 확률 분포를 추정하여 이를 바탕으로 decoding 하는 방법을 택하고 있습니다.
3) VAE의 도출과정(Derivation)
- First Try : ELBO의 등장
* ELBO는 Evidence Lower Bound의 줄임말로 복잡한 확률 모델에서 직접 계산하기 어려운 Likelihood를 근사하는 방법을 말합니다. 이는 아래에서 보여드릴 VAE의 Derivation 과정에서 설명드리겠습니다.
* VAE의 목표는 입력 데이터 x의 likelihood인 p(x)를 최대화하는 것입니다. 이는 다음과같이 표현해볼 수 있습니다.
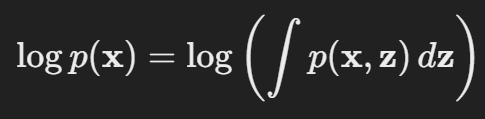
* 그러나, 이 적분을 직접 계산하는 것은 실제 z의 전체 분포를 모르는 상태에서 어려운 일입니다. 이를 위해
Variational Distribution (변분 분포)를 도입합니다.
이때 변분 분포는 실제 분포를 근사하는 분포로 우리가 정의할 수 있는 분포라고 보시면 됩니다. 대표적으로 Gaussian Distribution이 있겠습니다.(실제로 VAE에서도 Gaussian Distribution을 활용합니다.

* 로그와 적분을 분리하는 것은 어렵기 때문에 이를 기대값으로 표현해보겠습니다. (기대값의 정의도 모든 가능한 경우의 수, 즉 모집단을 모두 고려하는 것이기에 적분에 근사하는 개념으로 볼 수 있습니다)
아래 식을 보시면 이제 logp(x)는 변분 분포에 대한 기대값으로 정의가 됩니다.
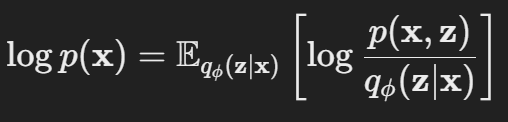
* 이제 위 식 내부에 p(z given x)를 분모 분자에 곱해주고 나서 log로 분리시켜준뒤

그리고 두번째항에서 분자의 p(z given x)는 우리가 모든 z에 대해서 알 수 없기에 계산할 수 없는 부분이다보니 이를 추정하는 변분 분포로 전환해주고, KL Divergence 의 개념을 도입해서 정리해보면 아래와 같이 정리할 수 있습니다.

* 이때 위 식의 첫번째 항을 나눠보면 아래와 같이 나오고 이를 ELBO로 표현하게 됩니다.
* 여기서 ELBO는 AE에서 활용되었던 재구성 스코어(Reconstruction Score)와 VAE 유도과정에서 추가된 KL 발산항으로 나눌 수 있으며. 아래와 같은 개념을 가지고 있습니다.

* 즉, 최종적으로 p(x)의 log likelihood를 높이는 것이 학습의 목표이고,
이때 ELBO의 Reconstruction score는 크게, KL Divergence Loss는 작게 만드는 것이 필요합니다.
* 다시 한번 정리해보면 p(x)의 log likelihood는 다음과 같이 표현해볼 수 있고,

여기서

* 이때 문제가 되는 것은 ELBO에 포함되지 않은 KL 발산항이고, 이는 변분 분포 인 q(z given x)가 실제 사후 분포인 p(z given x)와 얼마나 다른지를 측정하는 것입니다.
이때 일반적으로 우리가 알고있는 확률 분포로 p를 근사한 q더라도 p를 완벽하게는 표현할 수 없기에 이 값은 항상 0보다 크게 될 것입니다.
* 그렇기에 이 부분은 학습간 통제가 제한되는 부분이고, 결국 우리는 ELBO 부분을 최대하하는 것이 목표가 되어야 겠습니다.
'딥러닝 with Python' 카테고리의 다른 글
| [개념정리] ELBO란? Evidence Lower Bound란? (0) | 2024.10.30 |
|---|---|
| [개념 정리] 스케쥴러란? Scheduler (딥러닝 학습) (0) | 2024.10.29 |
| [딥러닝 with Python] GELU란?(Gaussian Error Linear Unit) (0) | 2024.10.27 |
| [논문 리뷰] ShapeNet : A Shapelet-Neural Network Approach for Multivariate Time Series Classification (시계열 분류) (1) | 2024.10.26 |
| [개념 정리] Shapelet이란? (시계열 분류) (0) | 2024.10.25 |




댓글